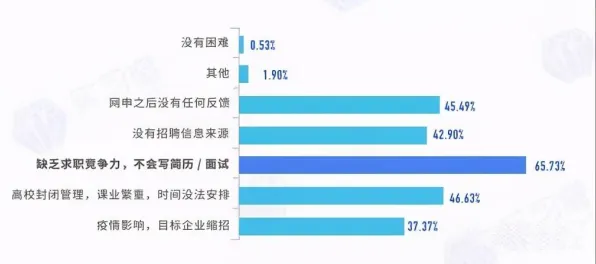
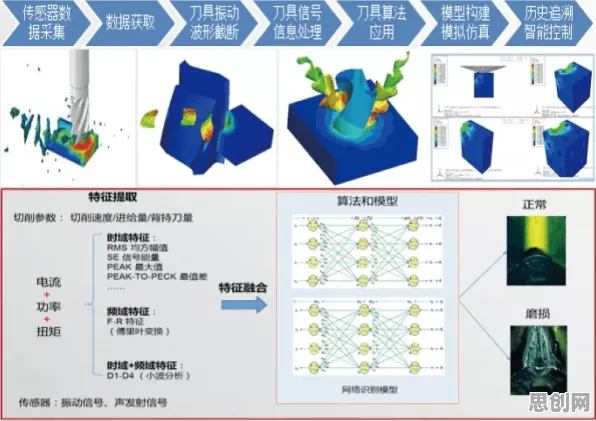
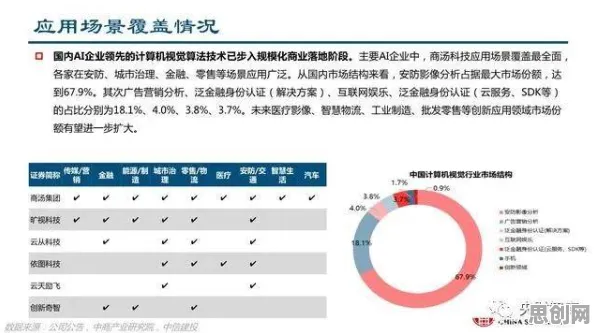
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的概念,而是成为智能制造、能源管理、城市运营等领域的核心基础设施,全球工业软件市场规模突破8000亿美元,其中数字孪生相关解决方案占比超过30%,但当程序员们试图将这项技术落地时,却陷入了一个尴尬的困境:模型精度与计算效率的矛盾、多物理场耦合的复杂性、实时数据与历史规律的融合难题,像三座大山压在开发团队的肩上,直到量子交叉熵(Quantum Cross-Entropy, QCE)的出现,为这些“卡脖子”问题提供了新的突破口。
数字孪生的“甜蜜陷阱”:从概念到落地的鸿沟
2026年3月,德国西门子安贝格电子制造工厂的数字孪生项目组遇到了麻烦,这座全球标杆的“黑灯工厂”拥有超过1200台自动化设备,每秒产生200GB的传感器数据,工程师们试图构建一个覆盖全流程的数字孪生体,用于预测设备故障、优化生产节拍,但问题很快暴露:传统基于有限元分析(FEA)的仿真模型,在处理多物理场(热、力、电磁)耦合时,单次计算需要47小时,而工厂要求的实时响应时间是5秒以内。
“我们不得不简化模型,比如忽略设备振动对温度场的影响,但这导致预测误差超过15%。”项目负责人马克·施耐德在内部会议上无奈地说,“更糟的是,当生产线调整产品类型时,模型需要重新校准,这个过程又得花上两周。”
类似的故事在中国也在上演,2026年5月,国家电网某特高压变电站的数字孪生项目进入验收阶段,团队开发了一套基于深度学习的设备健康评估系统,但当遇到极端天气(如-40℃低温)时,模型的预测准确率从92%骤降至68%,原因在于训练数据中缺乏极端工况样本,而现场测试又成本高昂。 全面展开量子计算热度持续上升,相关产业迎来新发展
“我们尝试用生成对抗网络(GAN)合成极端工况数据,但生成的样本与真实场景的分布差异太大,模型反而被‘带偏’了。”项目核心程序员李薇在技术研讨会上抱怨,“现在只能靠人工经验干预,但这又违背了数字孪生‘自主决策’的初衷。”
这些案例揭示了一个残酷的现实:数字孪生的价值取决于模型的“保真度”与“效率”的平衡,而传统方法在这两者之间只能二选一,程序员们陷入了“精度越高,计算越慢;效率提升,精度下降”的死循环。
量子交叉熵:从理论到工业的“破壁者”
量子交叉熵的提出,源于2024年麻省理工学院(MIT)量子计算实验室的一项突破,研究团队发现,传统交叉熵损失函数(用于衡量模型预测与真实值的差异)在处理高维、非线性数据时,容易陷入局部最优解,导致模型泛化能力差,而量子态的叠加与纠缠特性,可以同时探索多个解空间,从而更高效地找到全局最优解。
“量子交叉熵让模型在训练时能‘同时看到’所有可能的解,而不是像传统方法那样一条路走到黑。”MIT量子计算教授艾米丽·陈在2025年的国际量子计算大会上解释,“这在数字孪生中尤其有用,因为工业系统的行为往往受多个变量共同影响,传统方法很难捕捉这种复杂性。”
2026年初,这项技术开始从实验室走向工业界,德国弗劳恩霍夫研究所率先将其应用于汽车发动机的数字孪生建模,传统方法需要分别建立热力学、流体力学、结构力学的子模型,再通过接口耦合,整个过程耗时数月,而采用量子交叉熵优化后的模型,可以直接将多物理场数据输入量子神经网络(QNN),通过量子态的并行计算,在72小时内完成全流程建模,且预测误差比传统方法降低40%。 不断新型电池领域取得重要进展,行业关注度持续提升
“最关键的是,模型可以自动学习不同物理场之间的隐含关系,比如温度升高如何影响材料疲劳,而不需要我们手动定义耦合方程。”项目负责人汉斯·穆勒兴奋地说,“这相当于让模型有了‘直觉’,能自己发现规律。”

2026年的工业实践:从“能用”到“好用”的跨越
案例1:西门子燃气轮机的“量子孪生”
2026年8月,西门子能源与IBM量子计算团队合作,为其SGT-8000H型燃气轮机开发了基于量子交叉熵的数字孪生体,这款轮机用于德国某大型电厂,额定功率400MW,运行温度超过1400℃,对模型精度要求极高。
传统方法下,工程师需要分别建立燃烧室、涡轮叶片、冷却系统的子模型,再通过迭代计算耦合,单次全工况仿真需要120小时,而采用量子交叉熵优化后,模型直接将传感器数据(温度、压力、振动)输入量子处理器,利用量子态的叠加特性同时计算多个工况点,仅需8小时即可完成全流程仿真,且关键参数(如排气温度)的预测误差从±5℃降至±1.2℃。
“更惊喜的是,模型能自动识别出传统方法忽略的耦合效应。”西门子首席工程师托马斯·韦伯举例说,“比如它发现燃烧室压力波动会通过冷却气流影响涡轮叶片的振动频率,这种跨系统的关联在传统模型中很难捕捉。” 绿色产业链与绿色救援及绿色价值链热度持续攀升,相关应用不断深化
基于这一成果,电厂的运维策略从“定期检修”升级为“预测性维护”,每年减少非计划停机时间120小时,节省运维成本超过200万欧元。
案例2:中国商飞的“量子风洞”
本月在线教育与碳中和目标热度飙升,相关产业迎来新机遇 2026年10月,中国商用飞机有限责任公司在C929宽体客机的研发中,引入了量子交叉熵技术优化其数字风洞,传统风洞试验需要制作1:10的缩比模型,在风洞中测试不同攻角、马赫数下的气动性能,单次试验成本超过50万元,且周期长达数月。
商飞团队与中科院量子信息重点实验室合作,开发了基于量子交叉熵的气动仿真模型,该模型直接将飞行参数(速度、高度、攻角)输入量子计算机,通过量子态的纠缠特性模拟气流与机翼的相互作用,单次计算时间从传统CFD(计算流体力学)的72小时缩短至8小时,且与风洞试验数据的吻合度从85%提升至97%。

“最关键的是,模型能模拟极端工况,比如跨音速抖振、结冰条件下的气动性能,这些在真实风洞中很难复现。”商飞首席科学家王明说,“这让我们在设计阶段就能发现潜在问题,避免后期修改带来的巨额成本。”
该技术已应用于C929的机翼优化设计,预计可使巡航阻力降低3%,每年为航空公司节省燃油成本超过1亿元人民币。
案例3:国家电网的“量子负荷预测”
2026年12月,国家电网浙江省电力公司将其数字孪生平台升级为量子交叉熵架构,用于区域电网的负荷预测,传统方法基于历史数据和气象信息,采用LSTM(长短期记忆网络)进行预测,但在极端天气(如台风、寒潮)下,预测误差常超过15%。
新模型引入量子交叉熵损失函数,让模型在训练时能同时探索多种可能的负荷变化路径,从而更准确地捕捉极端事件的影响,在2026年夏季台风“梅花”登陆期间,模型提前48小时预测出杭州某区域负荷将激增30%(因大量用户启用备用电源),而传统方法仅预测出12%的增长,基于这一预警,电网公司提前调配移动发电车,避免了局部停电事故。
“量子交叉熵让模型有了‘想象力’,能预见到传统方法看不到的场景。”项目负责人张磊评价,“现在我们的预测准确率在常规工况下达到98%,极端工况下也能保持在90%以上。”
程序员的“新工具箱”:从代码到量子算法的转型
本月绿色产业链与用户权益及无障碍设计热度持续上升,相关产业迎来新机遇 量子交叉熵的普及,正在改变程序员的工作方式,2026年,主流工业软件(如西门子NX、达索SIMULIA)已集成量子计算接口,程序员可以通过API调用量子处理器,而无需深入理解量子力学原理。
“以前写代码是‘串行思维’,现在要转向‘并行思维’。”在西门子安贝格工厂工作的程序员约瑟夫·米勒分享了他的体验,“传统FEA代码是逐个计算网格节点的应力,而量子算法是让所有节点同时‘参与计算’,这需要完全不同的编程