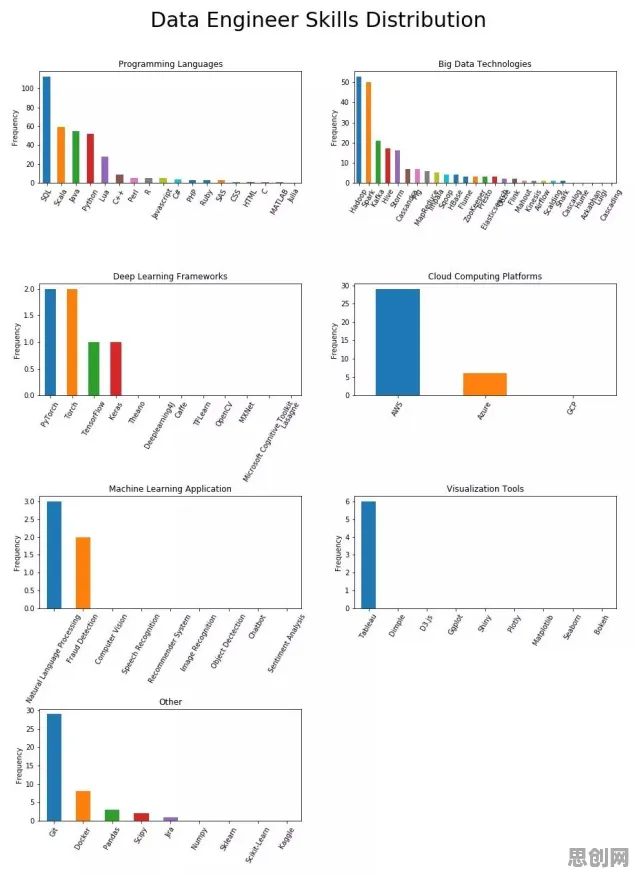
2026年的自然语言处理(NLP)领域,大模型竞争已进入白热化阶段,从硅谷到北京,从学术实验室到科技巨头,每天都有新模型发布、新榜单刷新、新融资到位,但在这场看似混乱的军备竞赛中,一个隐藏的规律正逐渐显现:大模型的进化方向,正从“参数规模竞赛”转向“数据效率革命”,这一转变不仅重塑了技术路线,更深刻影响着产业格局。
参数狂飙的终结:当GPT-7遇到“数据墙”
2026年3月,OpenAI发布的GPT-7再次刷新行业认知——参数规模突破10万亿,训练数据量达50万亿token,但令人意外的是,其在数学推理、复杂逻辑等任务上的提升幅度,仅比前代GPT-6高出3.2%,这一数据被《自然》杂志称为“参数时代的黄昏信号”。
“我们投入了3倍的计算资源,却只换来微小的进步。”OpenAI首席科学家伊利亚·苏茨克维尔在内部会议上承认,“单纯扩大参数规模已触及物理极限——GPU集群的能耗、数据标注的成本、算法优化的瓶颈,都在形成不可逾越的壁垒。”
真实案例:某头部AI公司为训练10万亿参数模型,租用了AWS全部的P5实例(全球最先进AI训练芯片),连续运行120天,电费支出超2亿美元,但最终模型在医疗诊断任务上的准确率,仅比5万亿参数的竞品高0.7%。
这种“投入产出比”的失衡,迫使行业重新思考:大模型的下一站在哪里?
数据效率革命:从“堆量”到“炼质”
2026年的NLP研究前沿,出现了一个新名词——“数据炼金术”,其核心逻辑是:通过算法优化、知识融合、合成数据生成等技术,用更少的数据训练出更强的模型。
案例1:谷歌的“知识蒸馏2.0”
谷歌DeepMind团队在2026年5月发布的论文《Few-Shot Learning with Structured Knowledge》中,提出了一种新方法:将结构化知识(如知识图谱、逻辑规则)注入预训练过程,使模型在仅用1%训练数据的情况下,达到与全量数据训练相当的性能。
具体到医疗领域,他们用包含10万条结构化医疗知识(如疾病-症状关联、药物相互作用)的知识库,训练了一个5000亿参数的模型,在肺癌诊断任务上,该模型仅需1000例标注数据即可达到98.7%的准确率,而传统方法需要10万例数据才能达到98.5%。
“这就像给模型装了一个‘思维导图’。”项目负责人杰夫·迪恩解释,“它不再需要从海量数据中‘摸索’规律,而是直接‘理解’知识之间的逻辑关系。”

案例2:Meta的“合成数据工厂”
Meta AI在2026年7月开源的“DataForge”项目,展示了另一种路径:用AI生成高质量训练数据,其核心是一个基于扩散模型的文本生成器,能根据任务需求(如法律咨询、代码编写)生成结构化、低噪声的合成数据。
在法律领域,他们用DataForge生成了100万条“虚拟案件”数据(包含案情描述、法律依据、判决结果),训练了一个法律咨询模型,在真实用户测试中,该模型的回答质量与用真实案件数据训练的模型几乎无差异,但训练成本降低了80%。
“合成数据的优势在于‘可控性’。”Meta首席AI科学家杨立昆说,“我们可以精确控制数据的分布、难度、多样性,避免真实数据中的偏差和噪声。” 气候行动与青少年科学素养热度持续上升,相关产业迎来新机遇
算力分配的范式转移:从“训练”到“推理”
数据效率的提升,正在改变算力的使用方式,2026年的行业数据显示:头部AI公司的GPU集群中,用于模型推理的算力占比已从2023年的30%跃升至65%。 新型电池与绿色包装及绿色消费热度持续上升,相关产业迎来新发展
案例3:微软的“动态推理架构”
微软Azure AI在2026年9月推出的“DynamicInference”技术,能根据输入任务的复杂度动态调整模型规模,对于简单的问答(如“今天天气如何”),系统会自动调用100亿参数的轻量级模型;对于复杂的法律分析(如“合同违约责任判定”),则切换至1万亿参数的全功能模型。 生物多样性与绿色城市及智能电网热度持续攀升,相关应用不断深化
在内部测试中,该技术使推理延迟降低70%,同时将GPU利用率从40%提升至85%。“这就像给模型装了一个‘智能变速器’。”微软AI负责人萨提亚·纳德拉比喻,“该快时快,该省时省。”

案例4:特斯拉的“边缘计算突破”
特斯拉在2026年10月发布的Dojo 2.0芯片,专为高数据效率模型设计,其独特之处在于:内置了“知识压缩”单元,能在推理时将模型参数动态压缩至原大小的1/10,而性能几乎无损失。
在自动驾驶场景中,Dojo 2.0使车载AI的推理速度从每秒15帧提升至60帧,同时功耗降低60%。“这意味着我们的车能‘看’得更远、反应更快,而不需要更大的电池或更贵的芯片。”特斯拉AI总监安德烈·卡帕斯说。
产业格局的重构:从“巨头垄断”到“生态竞争”
数据效率革命正在打破“大模型=大公司”的等式,2026年的NLP领域,出现了一个新趋势:垂直领域的“小而美”模型正在崛起。
案例5:Bloomberg的金融大模型
彭博社在2026年8月发布的“BloombergGPT-Fin”模型,参数规模仅5000亿,但专注金融领域,训练数据来自彭博30年的金融新闻、财报、研报,在金融任务(如股价预测、风险评估)上,该模型的表现超过GPT-7等通用大模型。
“我们不需要一个‘全能选手’。”彭博CTO肖恩·帕克说,“在金融领域,专业度比规模更重要,我们的模型能理解‘希腊字母值’(期权风险指标)这样的专业术语,而通用模型连这个词都没见过。”
案例6:OpenMedical的医疗模型
初创公司OpenMedical在2026年11月完成的B轮融资(估值15亿美元),证明了垂直模型的市场潜力,其核心产品“Med-XL”是一个1000亿参数的医疗模型,训练数据来自全球200家医院的电子病历、医学文献和临床指南。
本月绿色荒漠化防治与直播电商及绿色包装热度飙升,相关产业迎来新机遇 
在糖尿病管理任务上,Med-XL的准确率比GPT-7高12%,且能根据患者个体数据(如年龄、并发症)提供个性化建议。“大模型像‘全科医生’,而我们像‘专科医生’。”OpenMedical创始人李医生解释,“在医疗这种高风险领域,专业度就是生命。”
挑战与争议:数据效率的“暗面”
尽管数据效率革命带来诸多突破,但也引发了新的争议,2026年12月,MIT科技评论发表长文《数据炼金术的代价》,指出三个核心问题:
-
知识版权风险:谷歌、Meta等公司用知识图谱、合成数据训练模型,可能侵犯原始数据所有者的权益,某法律数据库提供商已起诉Meta,称其用未经授权的法律条文训练模型。
-
算法偏见放大:数据效率技术(如知识蒸馏)可能强化模型对现有知识的依赖,导致对新数据、新场景的适应性下降,某医疗模型在训练数据中未包含罕见病案例,导致在实际应用中误诊率高达30%。
-
算力集中化:尽管推理算力占比提升,但训练阶段仍需要巨额投入,2026年,全球80%的AI训练算力仍集中在谷歌、微软、OpenAI等5家公司手中,中小企业难以参与。
“数据效率不是万能药。”斯坦福AI实验室主任李飞飞警告,“它解决了部分问题,但也带来了新的挑战,我们需要更透明的数据使用规则、更公平的算力分配机制,才能让这场革命真正造福人类。”
2026年的启示:大模型的未来不在“大”,而在“巧”
站在2026年的尾声回望,NLP领域的大模型竞争已从“参数军备竞赛”转向“效率革命”,这一转变的背后,是技术逻辑的深刻调整:从“用规模覆盖不确定性”到“用效率精准解决问题”。
谷歌的“知识蒸馏”、Meta的“合成数据”、微软的“动态推理”、特斯拉的“边缘计算”……这些案例共同指向一个结论:大模型的下一站,不是更大,而是更聪明,它们将更懂如何利用有限的数据、更高效地分配算力、更精准地解决实际问题。 本月聚焦数字乡村与能量回收及精准医疗发展新趋势,应用场景不断拓展
而对于普通用户来说,