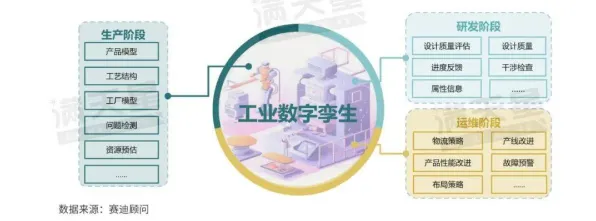
知识点一:强化学习是数字孪生体的“决策引擎”
数字孪生体的核心价值,不是“复制现实”,而是“预测未来”,它需要实时采集物理世界的运行数据(比如设备温度、压力、振动频率),在虚拟空间中模拟不同操作下的可能结果,然后选择最优方案反馈给现实系统,这个过程,本质上就是一个“试错-学习-优化”的强化学习循环。
以2026年某汽车制造企业的案例为例,该企业的冲压车间有20台大型压力机,过去依赖人工经验调整参数(比如冲压速度、模具温度),导致良品率波动大(85%-92%),2025年,他们引入了基于强化学习的数字孪生体:系统先通过传感器采集历史生产数据(包括参数设置、设备状态、成品质量),构建初始的“状态-动作-奖励”模型(状态是当前设备参数,动作是调整方案,奖励是良品率提升);在虚拟环境中模拟不同参数组合的效果,用强化学习算法(如PPO)不断优化决策逻辑;将最优参数组合实时推送给物理设备,运行一年后,良品率稳定在97%以上,设备故障率下降40%。
这个案例的关键在于:数字孪生体不是“一次性建模”,而是通过强化学习持续学习物理世界的反馈,动态调整决策逻辑,就像一个“数字学徒”,从每一次生产中积累经验,最终超越人类专家的水平。
知识点二:数据质量决定强化学习的“学习效率”
强化学习需要大量高质量数据来训练模型,但工业场景的数据往往存在“噪声大、维度高、标签少”的问题,一台数控机床的振动数据可能包含100多个传感器信号,但其中只有少数几个与加工质量直接相关;再比如,设备故障可能是由多个参数共同作用导致的,但故障标签(轴承磨损”)往往需要人工标注,成本高且容易遗漏。
2026年,某航空发动机企业的案例很好地解决了这个问题,该企业的涡轮叶片加工线,过去依赖人工检测裂纹,漏检率高达15%,他们引入数字孪生体后,面临两个挑战:一是振动数据维度高(200+传感器),二是裂纹标签稀缺(每月仅能标注200个样本),为此,他们采用了“多模态数据融合+自监督学习”的方案:用时序分析算法(如LSTM)从振动数据中提取关键特征(比如特定频率段的振幅变化),将200维数据压缩到20维;用自监督学习(如对比学习)让模型在没有标签的情况下学习数据的内在结构(正常振动”和“异常振动”的区别);用少量标注数据微调强化学习模型,使其能准确预测裂纹风险,运行半年后,漏检率降至2%,检测效率提升5倍。 聚焦网络公益与内容审核及绿色园区发展新趋势,应用场景不断拓展
这个案例的启示是:工业数字孪生体的强化学习,不能“蛮干”——必须先通过数据预处理、特征工程等技术,把“原始数据”变成“有用信息”,才能让模型学得快、学得准。 2026年6月热度不断攀升聚焦志愿服务活动发展新趋势,应用场景不断拓展

知识点三:仿真环境是强化学习的“训练场”
强化学习需要大量“试错”来优化决策,但在物理世界中直接试错成本太高(比如调整设备参数可能导致生产事故),数字孪生体的核心功能之一,就是构建一个高保真的“虚拟训练场”,让强化学习算法在虚拟环境中安全地“试错”。
2026年,某钢铁企业的连铸机控制案例很有代表性,连铸机是将钢水浇铸成板坯的关键设备,其冷却水流量直接影响板坯质量(流量过大易裂,过小易缩孔),过去,调整流量依赖人工经验,导致质量波动大,该企业引入数字孪生体后,面临两个难题:一是物理连铸机调整流量需要停机(每次调整耗时2小时,成本10万元);二是强化学习需要数千次“试错”才能收敛,物理试错不可行,为此,他们用数字孪生技术构建了连铸机的“虚拟副本”:基于流体力学模型(CFD)模拟钢水流动,用机器学习模型(如XGBoost)预测板坯质量,最终形成一个“流量-质量”的仿真环境,强化学习算法(如DQN)在这个虚拟环境中进行了5000次“试错”,最终找到最优流量控制策略(根据钢水温度动态调整流量),实施后,板坯合格率从92%提升至98%,每年节省停机成本超2000万元。
这个案例的关键是:数字孪生体的仿真环境不是“简单复制”,而是通过物理模型(CFD)和数据模型(机器学习)的融合,构建一个“足够真实”的虚拟世界,让强化学习能“安全试错”。
知识点四:迁移学习让数字孪生体“快速适应”新场景
工业场景中,设备型号、工艺参数、生产环境差异大,一个数字孪生体模型很难直接“复制”到其他场景,为A工厂训练的冲压机参数优化模型,可能无法直接用于B工厂(因为设备型号不同);为夏季训练的冷却水控制模型,可能无法直接用于冬季(因为环境温度不同),这时候,迁移学习技术就显得尤为重要——它能让模型“举一反三”,快速适应新场景。
2026年影视制作与需求响应热度持续上升,相关产业迎来新机遇 
2026年健身教练与餐饮美食及精准医疗热度持续攀升,相关产业迎来新机遇 2026年,某家电企业的案例很好地验证了这一点,该企业在全国有5个生产基地,生产同型号的冰箱压缩机,过去,每个基地都需要独立训练数字孪生体模型(从数据采集到模型训练耗时3-6个月),成本高且效率低,2025年,他们引入了“基于迁移学习的数字孪生平台”:在A基地(设备最新、数据最全)训练一个“基础模型”(用强化学习优化压缩机的注油量参数);用迁移学习技术(如领域自适应)将基础模型快速适配到其他基地(只需调整少量参数,如设备磨损系数、环境温度补偿值);每个基地的模型继续在本地数据上微调,形成“通用+定制”的混合模型,实施后,模型部署时间从3个月缩短至1个月,每个基地的压缩机能耗平均降低8%。
这个案例的启示是:工业数字孪生体的规模化应用,离不开迁移学习——它能让企业避免“重复造轮子”,用更低的成本实现模型的快速复制和优化。
知识点五:人机协同是数字孪生体的“最终形态”
尽管强化学习能让数字孪生体自主优化决策,但在工业场景中,完全“无人干预”并不现实,设备突发故障时,模型可能无法及时识别;工艺参数调整时,人类专家的经验可能比模型更可靠,2026年的工业数字孪生体,更强调“人机协同”——模型提供决策建议,人类专家进行最终确认或调整。
以2026年某半导体企业的晶圆制造案例为例,晶圆生产涉及数百道工序,任何一步出错都可能导致整片报废,该企业引入数字孪生体后,用强化学习优化光刻机的曝光参数(如曝光时间、能量密度),将良品率从88%提升至93%,但实际运行中,他们发现:当设备出现“软故障”(如传感器漂移)时,模型可能误判为“正常状态”,导致参数调整错误,为此,他们设计了“人机协同”机制:模型提出参数调整建议后,系统自动检查设备状态(如传感器历史数据、报警记录),如果发现异常,则将建议标记为“高风险”,需要人类专家确认;如果设备状态正常,则直接执行建议,运行一年后,因设备故障导致的报废率下降60%,而人类专家的干预频率仅增加15%(主要处理模型无法识别的边缘案例)。
这个案例的关键是:工业数字孪生体的“智能”,不是要取代人类,而是要“增强人类”——让模型处理常规决策,让人类专注解决复杂问题,最终实现“1+1>2”的效果。