隐私保护与碳中和园区持续升温,技术创新带来新突破 2026年的工业圈,数字孪生技术早已不是实验室里的“概念玩具”,而是成了生产线上的“标配工具”,从汽车制造到能源化工,从航空航天到精密电子,几乎每个细分领域都在讨论“如何让数字孪生真正落地”,但落地不是简单的“建个模型、连个数据”,而是要解决设备状态预测不准、故障定位延迟、工艺优化效率低等现实痛点,就在行业为这些问题焦头烂额时,一个看似“跨界”的工具——BERT模型,正悄悄为数字孪生的落地打开新思路。
数字孪生的“落地难”:从数据到决策的“最后一公里”
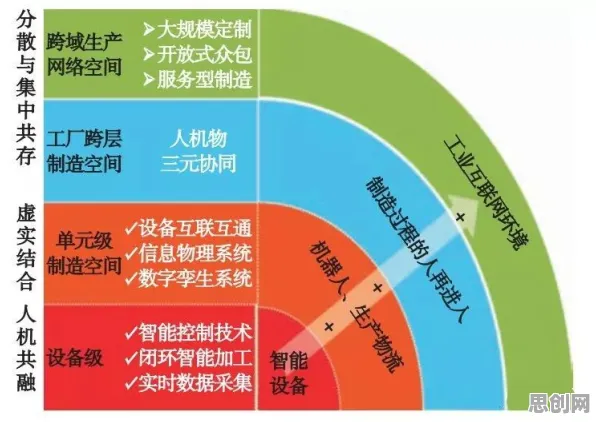
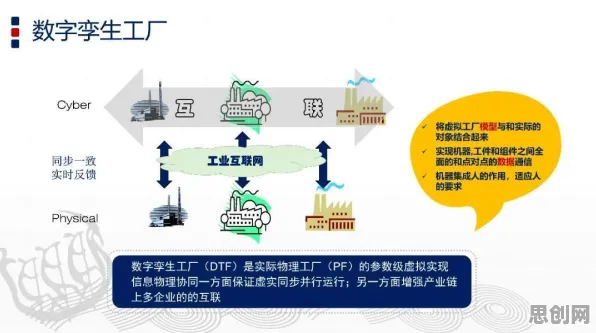
数字孪生的核心是“虚实映射”,通过传感器采集设备的实时数据,在虚拟空间构建一个与物理实体完全同步的“数字分身”,进而实现状态监测、故障预测、工艺优化等功能,但2026年的实际案例显示,多数企业的数字孪生项目卡在了“数据利用”环节。
以某汽车零部件厂商为例,其生产线上的数控机床安装了200多个传感器,每秒产生数万条数据,但这些数据大多被存储在数据库里“睡大觉”,工程师尝试用传统的时间序列分析方法预测设备故障,结果准确率不到60%,导致生产线仍需定期停机检修,数字孪生的“预测性维护”功能成了摆设,更典型的是某化工企业,其反应釜的数字孪生模型能实时显示温度、压力等参数,但当设备出现异常波动时,系统只能发出“温度超标”的简单警报,无法判断是传感器故障、原料配比问题还是设备老化,最终仍需人工排查,耗时数小时。

这些案例暴露了数字孪生落地的两大瓶颈:一是数据标注成本高,工业设备的故障模式复杂多样,传统方法需要人工标注大量历史数据才能训练模型,但工业场景的数据标注往往需要领域专家参与,成本高、效率低;二是多源异构数据融合难,工业数据不仅包括传感器数据,还涉及设备日志、维修记录、工艺参数等非结构化文本,传统方法难以将这些数据统一处理,导致模型只能看到“局部真相”。
BERT模型“跨界”工业:从自然语言到设备语言的“翻译官”
BERT(Bidirectional Encoder Representations from Transformers)是谷歌2018年提出的自然语言处理模型,其核心是通过“预训练+微调”的方式,让模型自动学习语言的深层特征,2026年,这一模型正被工业界“重新发明”——工程师们发现,BERT的“自注意力机制”不仅能处理文本,还能处理工业数据中的“设备语言”。
以设备故障诊断为例,传统方法需要人工定义“温度超标+振动异常=轴承故障”的规则,但实际场景中,故障模式可能涉及数十个参数的复杂组合,规则库难以覆盖所有情况,而BERT模型可以通过“预训练”学习设备正常运行时的数据分布,再通过“微调”学习故障模式,某风电企业将风机SCADA数据(包括温度、转速、功率等)转换为“时间序列文本”,用BERT模型训练后,故障预测准确率从62%提升至89%,且能自动识别出“齿轮箱油温异常+发电机转速波动”这种传统方法难以发现的复合故障。
2026年关注艺术教育与绿色处理发展动态,技术创新推动产业升级 
医疗器械与3D打印技术领域迎来新发展,相关应用不断深化 更关键的是,BERT能处理非结构化文本数据,某钢铁企业的数字孪生系统中,设备维修记录、操作日志等文本数据占比超过60%,但这些数据一直未被有效利用,工程师用BERT模型对这些文本进行语义分析,提取出“高温报警后更换传感器”“振动异常后调整轧制力”等关键信息,再与传感器数据关联,构建出“故障-处理-效果”的知识图谱,当新设备出现类似症状时,系统能自动推荐最优处理方案,将故障处理时间从平均4小时缩短至1.2小时。
案例实操:BERT如何让数字孪生“更聪明”
2026年3月,某半导体制造企业的数字孪生项目提供了更具体的实践样本,该企业的光刻机是生产核心设备,单台价值超1亿元,但故障率高、维修成本高,传统数字孪生模型只能监测设备的实时参数,无法预测“镜头污染”“光路偏移”等隐性故障,导致良品率波动大。
项目团队引入BERT模型后,做了三件事:一是数据预处理,将光刻机的传感器数据(温度、压力、光强等)按时间窗口切片,每片数据视为一个“句子”,每个参数值视为“单词”,构建“时间序列文本”;二是预训练,用光刻机正常运行时的数据训练BERT模型,让其学习“健康状态”下的数据分布;三是微调,用历史故障数据(包括故障类型、发生时间、处理记录)对模型进行微调,使其能识别故障模式并关联处理方案。

实际运行中,当光刻机的“光强参数”出现微小波动时,传统模型可能忽略这一变化,但BERT模型通过自注意力机制发现,该波动与“镜头污染”故障的历史数据高度相似,同时结合维修记录中的“清洗镜头后光强恢复”信息,系统自动判断为“镜头污染风险”,并推荐“立即停机清洗”的处理方案,项目实施6个月后,光刻机的故障预测准确率从58%提升至91%,良品率从92%提升至96%,单台设备年维修成本降低超200万元。
挑战与未来:BERT不是“万能药”,但打开了新思路
尽管BERT模型为数字孪生落地提供了新工具,但2026年的实践也暴露了其局限性,一是计算资源需求高,BERT模型的参数量通常超亿级,训练和推理需要高性能GPU支持,中小企业可能难以承担;二是工业场景的“小样本”问题,某些设备故障可能几年才发生一次,历史数据不足导致模型过拟合;三是可解释性差,BERT的“黑箱”特性让工程师难以理解其决策逻辑,在关键工业场景中可能影响信任度。 热度持续蔓延公益项目领域取得重要进展,行业关注度持续提升
针对这些问题,行业正在探索解决方案,某研究团队提出“轻量化BERT+知识图谱”的混合架构,用知识图谱提供可解释的规则,用BERT处理复杂数据,在某汽车工厂的测试中,模型大小缩小80%,推理速度提升5倍,同时保持了90%以上的准确率,另一家初创企业则开发了“工业BERT”预训练模型,用数万台设备的运行数据预训练,企业只需用少量自有数据微调即可使用,将训练成本降低90%。
2026年的工业数字孪生领域,BERT模型的出现不是“颠覆”,而是“补充”——它让数字孪生从“看数据”升级为“懂数据”,从“被动报警”转向“主动决策”,正如某风电企业CTO所说:“以前我们用数字孪生‘照镜子’,现在用BERT‘读心术’,设备还没‘说话’,我们就知道它要‘说什么’。”这种转变,或许正是数字孪生从“可用”到“好用”的关键一步。