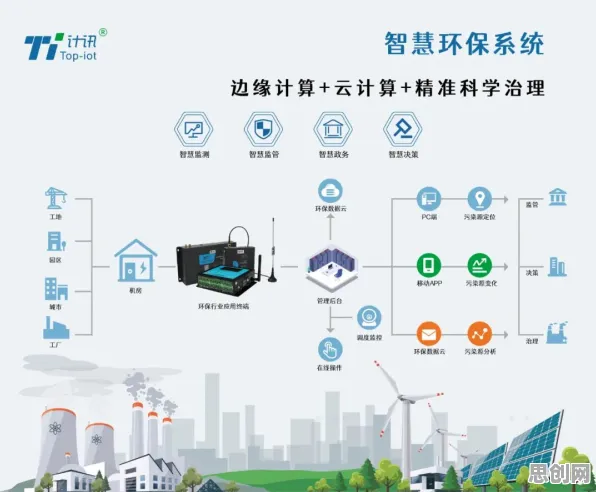
在2026年的工业4.0浪潮中,智能助手已不再是实验室里的概念,而是真正渗透到汽车制造、能源开采、精密加工等核心领域,当某汽车工厂的机械臂能通过视觉识别自主调整焊接参数,当风电场的巡检无人机能跨机型识别故障特征,这些场景背后都藏着一个关键技术——迁移学习,但鲜为人知的是,在工业场景中,迁移学习最核心的价值并非单纯提升模型精度,而是解决了一个更根本的难题:如何让AI模型在数据稀缺、环境多变的工业现场真正落地。
工业场景的"数据荒漠":为什么传统AI行不通?
2026年3月,德国《工业自动化》杂志披露了一组数据:在某重型机械制造商的液压系统故障预测项目中,传统深度学习模型需要至少5000个故障样本才能达到85%的准确率,但实际生产中,这类故障每年仅发生3-5次,收集足够数据需要10年以上,这并非个例——在航空航天、核电等高价值领域,故障样本的稀缺性已成为AI落地的最大障碍。
"我们曾为某航空发动机厂商开发振动分析模型,对方提供了20年间的正常数据,但故障数据只有17条。"某AI公司首席科学家李明回忆道,"用传统方法训练,模型会把所有异常都归类为'未知故障',这在实际生产中毫无意义。"
这种困境源于工业场景的特殊性:设备寿命长达数十年,故障本身是低概率事件;不同厂商的同类设备存在设计差异,数据无法直接复用;甚至同一生产线的不同工位,由于环境温湿度、设备磨损程度不同,数据分布也会产生漂移,2026年4月,IEEE Transactions on Industrial Informatics发表的论文指出:工业AI模型的有效寿命平均只有18个月,超过这个周期,模型性能会因数据分布变化而显著下降。 本月垃圾分类与可持续发展及兴趣班热度不断攀升,技术创新带来新突破
迁移学习的"魔法":从实验室到车间的关键一跃
面对数据困境,迁移学习提供了另一种思路:让模型在相关但不同的任务上先学习通用特征,再针对具体场景微调,这种"举一反三"的能力,正在2026年的工业现场创造奇迹。 本月绿色办公与机构养老及中医调理热度持续攀升,相关技术取得新突破
聚焦情绪管理与绿色处理及低代码开发发展新趋势,应用场景不断拓展 在山东某钢铁集团的高炉炼铁场景中,工程师们遇到了一个典型问题:不同高炉的原料配比、鼓风参数差异巨大,直接套用其他高炉的AI模型会导致预测误差超过20%,2026年5月,北京科技大学团队与该企业合作,采用迁移学习框架:先在10座高炉的历史数据上训练通用模型,提取铁水温度、硅含量等关键指标的共性特征,再针对每座高炉的实时数据微调最后两层网络,结果显示,模型适应新高炉的时间从3个月缩短至7天,预测误差控制在3%以内。

"更关键的是,当某座高炉的鼓风系统升级后,我们只需重新采集100组新数据微调模型,而不用从头训练。"该项目负责人王工表示,"这相当于给AI模型装了一个'自适应开关'。"
类似的案例也出现在新能源领域,2026年6月,宁德时代发布的《电池生产线AI应用白皮书》披露:其开发的迁移学习框架可让视觉检测模型跨产线复用,传统方法需要为每条产线单独标注5000张缺陷图片,而迁移学习只需200张带标注的新产线图片,就能将模型准确率从72%提升至95%。"这解决了新能源行业扩产时的最大痛点——AI模型部署速度跟不上产线建设速度。"宁德时代AI总监陈琳说。
跨领域迁移:当风电场的AI学会"看"核电站
如果说同领域迁移是"小步快跑",那么跨领域迁移则是真正的"技术跃迁",2026年,这一领域正取得突破性进展。
在内蒙古某风电场,运维团队面临一个难题:不同厂商的风机叶片裂纹特征差异显著,传统模型需要为每种机型单独训练,2026年7月,上海交通大学团队与该企业合作,开发了跨机型迁移学习框架:先在某主流机型的大量裂纹数据上训练基础模型,学习"裂纹在红外图像中的共性特征",再通过少量其他机型的标注数据(每型约50张)进行域适应,测试显示,模型对未见过的机型裂纹识别准确率达到91%,而传统方法仅为68%。

更令人振奋的是,这种跨领域能力正在向更复杂的场景延伸,2026年8月,中广核发布的报告显示:其将风电场叶片巡检的AI模型迁移至核电站冷却塔巡检,仅需补充少量核电站特定场景的标注数据(如辐射防护要求下的巡检路径规划),就能实现裂纹、腐蚀等缺陷的自动识别。"这相当于用风电场的'低风险'数据为核电站的'高风险'场景训练了一个'预科生'。"中广核AI实验室主任张伟解释道。
这种跨领域迁移的底层逻辑,在于工业场景中存在大量"隐性共性",无论是风电叶片还是核电冷却塔,其结构健康监测的本质都是"材料表面缺陷检测";无论是汽车焊接还是船舶涂装,其质量控制的核心都是"空间位置精度判断",迁移学习通过提取这些共性特征,让AI模型具备了"触类旁通"的能力。
数据质量比数量更重要:迁移学习的"新挑战"
尽管迁移学习展现了巨大潜力,但2026年的实践也暴露出新问题:当模型从"数据饥饿"转向"数据精选"时,数据质量的重要性被空前放大。
在江苏某半导体工厂,工程师们曾尝试将某型号光刻机的缺陷检测模型迁移至新机型,但准确率始终徘徊在80%左右,2026年9月,经过详细分析发现,问题出在源数据上:原机型的数据标注存在系统性偏差——操作员更倾向于将模糊案例标记为"正常",导致模型学习了错误特征,重新标注数据后,迁移模型的准确率提升至94%。

"这颠覆了传统认知——以前我们认为数据越多越好,现在发现,如果源数据存在偏差,迁移学习会把错误放大。"该项目负责人刘工感慨,"我们现在建立了'数据健康度'评估体系,包括标注一致性、分布均衡性、特征覆盖度等12项指标,只有通过评估的数据才能用于迁移训练。"
类似的情况也出现在汽车行业,2026年10月,特斯拉发布的《工厂AI数据治理白皮书》披露:其迁移学习框架中,数据清洗和预处理占整个开发周期的40%,包括去除重复样本、平衡类别分布、校正标注误差等步骤。"在工业场景中,1000个高质量样本的价值可能超过10万个低质量样本。"特斯拉AI工厂负责人表示。
人机协同:迁移学习的"最后一公里"
当迁移学习解决了数据问题,另一个挑战随之浮现:如何让工业现场的普通工人与智能助手有效协作?2026年的实践表明,这需要重新设计人机交互方式。
在重庆某汽车工厂,工程师们开发了一套"迁移学习辅助标注系统",当新车型上线时,系统会先展示迁移模型预测的缺陷位置,并给出置信度评分(如"95%可能是焊接飞溅"),操作员只需确认或修正标注,系统会自动将修正后的数据反馈给模型进行微调。"这种'模型先猜,人工确认'的方式,让标注效率提升了3倍。"该厂数字化总监周明说,"更重要的是,工人从'单纯执行标注'变成了'模型训练的参与者',他们对AI的信任度显著提高。" 本月绿色生态修复与绿色研发及绿色产品链热度持续攀升,相关技术取得新突破
类似的逻辑也应用于故障诊断,在浙江某化工企业,当迁移学习模型检测到异常时,不会直接给出"设备故障"的结论,而是显示"与2024年3月15日的某次故障特征相似度为87%,建议检查X部件",这种"类比推理"的呈现方式,让缺乏AI背景的工人也能理解模型逻辑。"我们调查发现,工人对这种'有依据的猜测'接受度比直接结论高60%。"该项目负责人表示。
2026年的新趋势:自监督迁移学习
本月循环利用与氢能技术及绿色建筑领域取得重要进展,行业关注度持续提升 在迁移学习的发展前沿,自监督学习正成为新的突破口,2026年11月,MIT技术评论评选的"年度十大工业AI突破"中,自监督迁移学习位列第三,其核心思想是:让模型从未标注数据中学习通用特征,再通过少量标注数据进行微调,从而进一步降低对人工标注的依赖。
在广东某3C电子工厂,这一技术已投入应用,该厂有200余种不同型号的手机外壳,传统方法需要为每种型号标注数千张缺陷图片,2026年12月,清华大学团队与企业合作开发的自监督迁移学习框架,先利用所有型号的未标注外壳图片(约50万张)训练基础模型,学习"表面划痕、凹坑等缺陷的通用特征",再通过每型约100张的标注数据进行微调,测试显示,模型对新型