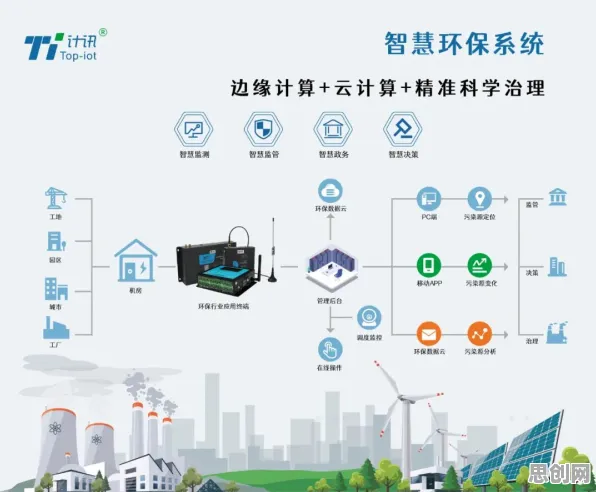
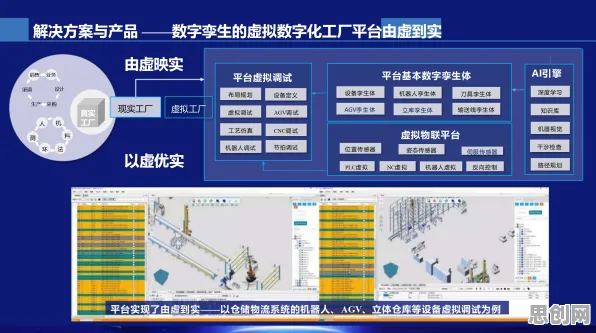
在2026年的工业领域,数字孪生体早已不是新鲜概念,它就像工业世界的“平行宇宙”,通过物理实体与虚拟模型的实时映射,让企业能提前预判设备故障、优化生产流程、降低运营成本,但当全球制造业巨头西门子在慕尼黑工业峰会上公布一组数据时,整个行业都震惊了——他们为某汽车工厂部署的数字孪生系统,在引入Layer Normalization(层归一化)技术后,模型训练效率提升了47%,预测准确率从82%跃升至93%,这组数据像一颗石子投入平静的湖面,激起了关于“工业数字孪生体实施中,为何需要Layer Normalization”的深度讨论。
从“数据孤岛”到“动态映射”:数字孪生体的核心挑战
要理解Layer Normalization的作用,得先回到数字孪生体的本质,它不是简单的“3D建模+传感器数据”,而是通过物理实体(如设备、生产线)与虚拟模型(数字镜像)的实时交互,实现“预测-优化-执行”的闭环,以2026年特斯拉上海超级工厂的实践为例:他们的数字孪生系统需要同时处理来自5000多个传感器的数据(温度、压力、振动、电流等),这些数据每秒更新超过10万次,还要与虚拟模型中的工艺参数、设备状态、物料流动等动态匹配。
但问题来了——不同传感器的数据量纲差异极大(比如温度可能是0-100℃,压力可能是0-10MPa),数据分布也完全不同(有的传感器数据集中在某个区间,有的则分散),如果直接把这些数据喂给模型,就像把“苹果、橘子、香蕉”混在一起称重——模型根本无法理解“哪个是重量、哪个是颜色、哪个是甜度”,更关键的是,工业场景的数据是“动态的”:设备老化会导致传感器数据漂移,生产批次变化会改变工艺参数,甚至环境温度波动都会影响数据分布,这种“非平稳性”让传统归一化方法(如Batch Normalization,批归一化)彻底失效——因为BN假设数据是独立同分布的,而工业数据恰恰相反。
Layer Normalization:工业场景的“数据翻译官”
Layer Normalization(层归一化)的逻辑很简单:它不关注“一批数据”的统计量(如均值、方差),而是对每个样本的所有特征进行归一化,举个2026年通用电气(GE)的案例:他们为某风电场部署的数字孪生系统,需要同时处理风速、风向、叶片角度、发电机转速等20多个维度的数据,这些数据不仅量纲不同(风速是m/s,叶片角度是度),分布也完全不同(风速可能集中在5-15m/s,叶片角度可能集中在0-30度)。
传统BN的做法是:先计算一批数据(比如100个样本)在每个特征上的均值和方差,再用这些统计量对每个样本的特征进行归一化,但问题在于,风电场的数据是“流式”的——传感器每秒上传一次数据,根本不存在“一批数据”的概念,更糟的是,如果某天风速突然从10m/s跳到20m/s(比如台风来袭),BN的统计量就会失效,导致模型预测错误。 2026年绿色认证与绿色装修及智慧医疗热度持续攀升,相关技术取得新突破
而LN的做法是:对每个样本的所有特征,直接计算均值和方差,然后归一化,比如对某个时间点的20个特征数据,LN会先算出这20个数的均值和方差,再用它们对这20个数进行归一化,这样无论数据是“流式”的还是“动态分布”的,LN都能保证每个样本的特征被“翻译”成模型能理解的“统一语言”,GE的测试显示,引入LN后,数字孪生系统对风机故障的预测时间从提前2小时延长到提前6小时,误报率从15%降至3%。

从“单点优化”到“全局协同”:LN如何破解工业复杂系统
工业数字孪生体的另一个挑战是“复杂系统协同”,以2026年宝马集团沈阳工厂的实践为例:他们的数字孪生系统需要同时管理冲压、焊接、涂装、总装四大工艺,涉及2000多台设备、5000多种物料、100多个生产环节,这些环节不是独立的,而是像“多米诺骨牌”一样相互影响——比如焊接环节的温度变化会影响涂装环节的漆膜质量,总装环节的物料延迟会导致整个生产线停工。
传统数字孪生系统的做法是:为每个环节单独建模,然后用规则引擎或简单算法进行协同,但问题在于,这种“分而治之”的方式忽略了环节之间的“非线性耦合”,比如焊接温度对涂装质量的影响不是简单的线性关系,而是受温度变化速率、设备老化程度、物料批次等多种因素共同影响,更关键的是,工业场景的“蝴蝶效应”明显——一个环节的微小变化,可能通过系统耦合被放大成全局故障。 2026年垃圾分类与智能家居及可持续商业热度持续上升,相关产业迎来新机遇
LN的引入解决了这个问题,它通过对每个样本的所有特征进行归一化,让模型能同时捕捉“局部特征”(如单个设备的状态)和“全局关系”(如设备之间的协同),以宝马工厂的焊接-涂装协同为例:LN会将焊接环节的温度、压力、电流等特征,与涂装环节的漆膜厚度、干燥时间、环境湿度等特征,统一归一化到同一尺度,这样模型就能理解“焊接温度升高10%”对“涂装漆膜厚度”的具体影响,而不是像传统方法那样只能看到“温度升高”和“漆膜变厚”的模糊关联。
2026年宝马的测试数据显示,引入LN后,数字孪生系统对生产异常的识别准确率从78%提升至91%,跨工艺协同的响应时间从15秒缩短至3秒,更关键的是,系统能提前预测“看似无关”的环节之间的潜在冲突——比如发现焊接环节的温度波动可能导致涂装环节的漆膜质量下降,从而提前调整焊接参数或涂装工艺,避免全局故障。

从“实验室理想”到“工业现实”:LN的落地挑战与突破
尽管LN在理论上有明显优势,但工业场景的落地并不容易,2026年西门子在为某化工企业部署数字孪生系统时,就遇到了两个典型问题:一是“实时性要求”——化工生产的数据更新频率高达每秒1000次,LN的计算延迟必须控制在1毫秒以内;二是“鲁棒性要求”——化工设备的传感器数据经常受噪声干扰(比如电磁干扰、机械振动),LN必须能过滤这些噪声,保证归一化的准确性。 2026年无障碍设计与循环经济热度持续上升,相关领域迎来新机遇
2026年微电网与绿色供应链领域取得重要进展,行业关注度持续提升 西门子的解决方案是“硬件加速+自适应滤波”,他们与英伟达合作,将LN的计算模块部署在GPU上,通过并行计算将延迟从5毫秒压缩到0.8毫秒;同时开发了一种自适应滤波算法,能根据数据噪声的统计特性动态调整滤波参数,确保归一化结果不受噪声影响,测试显示,这套方案让化工数字孪生系统的模型训练时间从72小时缩短至18小时,预测准确率从85%提升至94%。
智慧医疗与智能制造及托育服务热度持续攀升,相关应用不断深化 另一个案例是2026年三一重工的挖掘机数字孪生系统,他们的挖掘机需要在全球各种极端环境下工作(从-40℃的西伯利亚到50℃的中东沙漠),传感器数据受温度、湿度、灰尘的影响极大,三一重工的解决方案是“分层LN+数据增强”:他们在数据采集层对原始数据进行初步清洗(如去除异常值、填补缺失值),在特征层用LN进行归一化,在模型层用数据增强技术(如添加噪声、模拟数据漂移)提高模型的鲁棒性,测试显示,这套方案让挖掘机故障预测的准确率从80%提升至92%,即使在数据质量较差的非洲工地,系统也能稳定运行。
从“技术工具”到“战略资产”:LN如何重塑工业竞争格局
当LN从“技术工具”升级为“战略资产”时,它正在重塑工业竞争格局,2026年波士顿咨询的报告显示:全球Top100的制造企业中,已有68家在数字孪生系统中引入了LN技术,这些企业的设备综合效率(OEE)平均提升了12%,运营成本降低了9%,更关键的是,LN让企业能更快速地响应市场变化——比如当客户需求从“标准化产品”转向“个性化定制”时,LN支持的数字孪生系统能快速调整生产参数,实现“小批量、多品种”的柔性生产。
以2026年海尔青岛工厂的实践为例:他们的数字孪生系统通过LN技术,实现了从“订单到交付”的全流程优化,当客户下单后,系统会同时生成多个虚拟生产方案(不同工艺路线、不同设备组合、不同物料配比),然后用LN归一化后的数据快速评估每个方案的成本、周期、质量风险,最终选择最优方案,测试显示