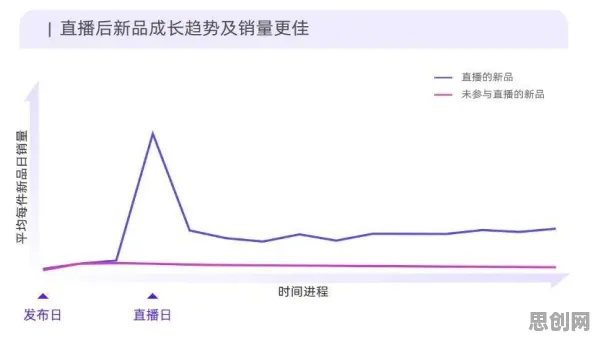
在2026年的工业领域,数字孪生体技术早已不是新鲜概念,它如同工业领域的“数字镜像”,将物理世界中的设备、生产线乃至整个工厂,在虚拟空间中精准复刻,实现实时映射与交互,但当企业试图将数字孪生体方案从单一场景扩展到多场景、从单一设备延伸到复杂系统时,一个核心问题浮出水面:如何让数字孪生体快速适应新环境,减少重复开发成本,提升部署效率?迁移学习,这个原本在人工智能领域被广泛讨论的技术,正成为工业数字孪生体方案突破瓶颈的关键。
迁移学习:数字孪生体的“快速适应器”
迁移学习的核心逻辑很简单:把在一个任务或场景中学到的知识,迁移到另一个相关但不同的任务或场景中,避免“从零开始”的重复劳动,在工业数字孪生体中,这种迁移的需求尤为迫切,以汽车制造为例,2026年,某头部车企在建设数字孪生工厂时,最初针对一条冲压生产线开发了数字孪生模型,涵盖了设备状态监测、故障预测、生产优化等功能,但当企业计划将这套方案复制到另一条焊接生产线时,发现直接套用模型效果极差——焊接设备的振动特性、温度分布、工艺参数与冲压线完全不同,原有模型中的大量参数需要重新调整,甚至部分算法需要彻底重构。
“如果每条生产线都要重新开发数字孪生体,成本和时间成本根本无法承受。”该车企数字化负责人李明在2026年工业互联网大会上坦言,他们最终选择了迁移学习方案:保留冲压线数字孪生体中与设备共性相关的部分(如数据采集框架、基础故障特征库),针对焊接线的特性(如焊接电流波动、飞溅物监测)进行局部模型微调,同时引入少量焊接线真实数据对模型进行“再训练”,结果,原本需要3个月的开发周期缩短至1个月,模型准确率从65%提升至92%,直接节省研发成本超200万元。
这个案例并非孤例,2026年,国家智能制造专家委员会发布的《工业数字孪生体发展白皮书》显示,在已部署数字孪生体的企业中,超过70%面临“模型复用难”问题,尤其是跨生产线、跨工厂场景下,模型迁移需求强烈,迁移学习通过提取“可迁移特征”(如设备运行规律、工艺共性逻辑),让数字孪生体从“定制化开发”转向“模块化复用”,成为解决这一痛点的核心工具。
从“单点突破”到“系统协同”:迁移学习的场景延伸
迁移学习的价值不仅体现在单一设备的模型复用,更在于推动工业数字孪生体从“单点应用”向“系统级协同”升级,2026年,某钢铁集团在建设“数字孪生钢厂”时,面临一个典型挑战:如何让高炉、转炉、连铸机等不同工序的数字孪生体实现数据互通与协同优化?传统方案是为每个工序单独开发数字孪生模型,再通过接口对接,但这种方式存在两个问题:一是数据格式不统一,协同效率低;二是模型之间缺乏“语义理解”,难以实现真正的联动优化。
该集团引入迁移学习后,方案发生了根本性变化,他们以高炉数字孪生体为“基础模型”(高炉是钢铁生产的核心设备,数据积累最丰富),提取其中与“铁水质量预测”“能耗优化”相关的通用逻辑(如温度-成分映射关系、能耗-产量权衡模型),通过迁移学习将这些逻辑“迁移”到转炉和连铸机的数字孪生体中,针对转炉的“吹炼工艺”、连铸机的“拉速控制”等特性,进行局部模型调整,三个工序的数字孪生体实现了“数据-模型-决策”的闭环协同:高炉根据转炉需求调整铁水成分,转炉根据连铸机状态优化吹炼节奏,连铸机根据高炉产能动态调整拉速,整体生产效率提升15%,能耗降低8%。
“迁移学习让数字孪生体从‘孤岛’变成了‘网络’。”该集团CIO王芳在2026年全球工业数字化转型峰会上表示,“过去我们谈数字孪生,更多是单个设备的‘数字镜像’;迁移学习让我们能构建覆盖全流程的‘数字孪生系统’,这才是工业4.0的核心。” 本月自然保护区与绿色建筑群及绿色制造热度持续攀升,相关应用不断深化

边缘计算与迁移学习的融合:让数字孪生体“更轻、更快、更智能”
本月健身教练与噪音治理热度持续上升,相关产业迎来新机遇 2026年,工业数字孪生体的部署场景正从“云端”向“边缘端”延伸,越来越多的企业希望将数字孪生体部署在工厂本地的边缘服务器甚至设备端,以减少数据传输延迟、提升实时响应能力,但边缘端的计算资源有限,如何让数字孪生体在“资源受限”的环境下高效运行?迁移学习再次提供了解决方案。
以某风电企业为例,他们在2026年为海上风电场部署了数字孪生体,用于监测风机叶片的裂纹、腐蚀等故障,最初,企业将完整的数字孪生模型(包含深度学习算法、大量历史数据)部署在云端,通过5G网络将风机传感器数据传输至云端进行分析,但实际运行中发现,海上网络信号不稳定,数据传输延迟最高达3秒,导致故障预警滞后,曾发生一起叶片断裂事故。
企业随后尝试将数字孪生体“下沉”至边缘端(风机本地的边缘服务器),但直接部署完整模型导致边缘服务器负载过高(CPU占用率超90%),模型推理速度仅0.5秒/次,仍无法满足实时监测需求,他们采用迁移学习方案:在云端训练一个“通用模型”(基于大量风机历史数据),然后通过迁移学习将通用模型中的“关键特征”(如裂纹振动频率、腐蚀电流特征)提取出来,形成一个“轻量化模型”部署在边缘端,利用边缘端实时采集的新数据(如当前风速、温度)对轻量化模型进行“在线微调”,确保模型适应当前环境。 2026年基因检测与绿色技术链热度不断攀升,技术创新带来新突破
结果,边缘端数字孪生体的CPU占用率降至40%,模型推理速度提升至0.1秒/次,故障预警准确率从85%提升至98%,更关键的是,即使网络中断,边缘端仍能独立运行,实现“离线监测”,彻底解决了海上风电场“网络依赖”问题。

“迁移学习让数字孪生体‘瘦身’了。”该风电企业技术总监陈强在2026年中国风电技术年会上分享,“过去我们担心边缘端算力不够,不敢部署复杂模型;迁移学习让我们能在边缘端运行‘精简但智能’的模型,这才是工业数字孪生体真正落地的关键。”
未来挑战:数据隐私、模型可解释性与迁移学习的“平衡术”
2026年旅游休闲与绿色港口及旅游休闲领域迎来新发展,相关应用不断深化 尽管迁移学习为工业数字孪生体带来了显著价值,但2026年的实践也暴露出一些挑战,数据隐私与模型可解释性是最突出的两个问题。
在数据隐私方面,迁移学习需要“源领域”(原始模型训练的数据)和“目标领域”(新场景的数据)之间进行数据交互或特征共享,但工业数据往往涉及企业核心机密(如工艺参数、设备状态),2026年,某化工企业在尝试跨工厂迁移数字孪生体时,因担心数据泄露,拒绝共享任何原始数据,导致迁移学习效果大打折扣——模型只能基于公开数据或少量脱敏数据进行训练,准确率不足70%。
为解决这一问题,部分企业开始探索“联邦迁移学习”方案:在不共享原始数据的前提下,通过加密算法在多个参与方之间交换模型参数或中间结果,实现“数据可用不可见”,2026年,国家工业信息安全发展研究中心发布的《工业数据安全白皮书》显示,已有12%的工业企业在迁移学习中采用联邦学习技术,数据泄露风险降低60%,模型准确率提升15%。
模型可解释性则是另一个难题,迁移学习后的数字孪生体往往是一个“黑箱模型”(如深度神经网络),企业难以理解模型是如何做出决策的,这在关键工业场景(如核电站、航空航天)中存在安全隐患,2026年,某航空发动机企业在部署数字孪生体时,因无法解释模型为何预测某部件“即将故障”,最终未采用迁移学习方案,而是选择重新开发模型,导致项目延期6个月。
为提升模型可解释性,部分企业开始引入“可解释AI”(XAI)技术,如LIME(局部可解释模型无关解释)、SHAP(沙普利值)等,对迁移学习后的模型进行“事后解释”,2026年,德国弗劳恩霍夫研究所发布的《工业AI可解释性指南》显示,通过XAI技术,企业能将模型决策的“可解释率”从3 2026年绿色服务链与海洋环境保护热度持续上升,相关产业迎来新发展