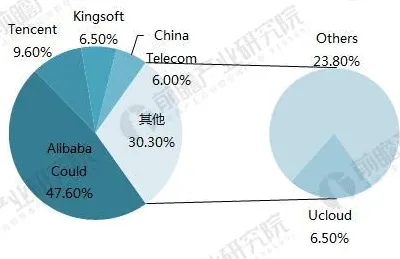
数据表征:从“原始数据”到“可计算符号”的转化,决定了确权的“基础坐标”
生成式AI的第一步,是把现实世界中的数据“翻译”成机器能理解的符号,这个过程叫“数据表征”,就像把一本书从中文翻译成英文,翻译的质量直接影响后续的理解与生成,2026年,全球最大的开源AI社区Hugging Face发布了一份《数据表征白皮书》,里面有个案例很典型:某医疗AI公司用200万份电子病历训练模型,试图生成诊断建议,但当模型投入临床后,医生发现它对少数民族患者的诊断准确率比主流人群低30%,调查后发现,问题出在数据表征环节——原始病历中,少数民族患者的症状描述常夹杂方言或非标准术语,而表征算法在转换时直接忽略了这些“异常值”,导致模型学习到了有偏差的“知识”。
这个案例暴露了数据确权的第一个关键点:表征过程会改变数据的“原始属性”,原始数据可能属于患者(个人隐私)、医院(业务记录)或政府(公共卫生数据),但经过表征后,它变成了算法能处理的“向量”“嵌入”或“图谱”,这些中间形态的数据,既保留了原始信息的部分特征,又融入了算法的设计逻辑(比如如何处理异常值、如何压缩信息),2026年欧盟通过的《AI数据治理条例》明确规定:任何使用个人数据进行表征的AI系统,必须记录“表征日志”——详细记录原始数据如何被转换、哪些特征被保留或丢弃、转换过程中是否引入外部知识(如词典、规则库),这条规定的背后,正是对“表征过程可能改变数据权属”的深刻认知——如果原始数据属于A,但表征后的数据因融入了B的算法逻辑,那么生成内容的权属就可能涉及A和B的共同权益。
中国的情况也类似,2026年3月,北京互联网法院审理了一起AI生成音乐侵权案:某音乐平台用用户上传的10万首歌曲训练模型,生成了一首新歌并发布,原告是其中一首歌曲的词曲作者,认为模型“抄袭”了他的旋律,法院在审理中发现,模型在表征阶段将所有歌曲的旋律转换为“音高-节奏-和声”的三维向量,而新歌的向量与原告歌曲的向量在“和声”维度上有85%的重合度,但被告辩称:向量是算法生成的中间结果,不属于原始音乐作品,因此不构成侵权,最终法院参考了《生成式AI服务管理暂行办法》中“数据表征阶段的知识保留规则”,判定被告需承担部分责任——因为表征算法未对原始音乐中的“独创性表达”(如特定的和声进行)进行足够脱敏,导致生成内容保留了可识别的原始特征,这个案例说明:数据表征的质量,直接决定了生成内容与原始数据的“关联强度”,进而影响确权的边界。
生成机制:从“概率采样”到“因果推理”的进化,重新定义了“创作”的本质
搞懂数据表征后,下一个问题是:AI是如何从表征后的数据中“生成”新内容的?这涉及生成式AI的核心机制——如何根据输入(或随机噪声)生成输出,2026年的主流生成模型(如GPT-5、Stable Diffusion 3.0)早已不是简单的“记忆-复制”机器,而是通过复杂的概率采样或因果推理来创造内容,理解这两种机制的区别,是理解数据确权进展的关键。
先看概率采样,早期的生成模型(如GPT-3)主要依赖“自回归采样”:给定一段文本,模型会预测下一个词的概率分布,然后从中随机选择一个词作为输出,再把这个词加入输入,继续预测下一个词,直到生成完整文本,这种机制的本质是“从训练数据中拼凑答案”,2026年,美国版权局处理了一起AI生成小说的版权登记案:作者用GPT-4生成了一部科幻小说,申请版权保护,版权局拒绝登记,理由是“小说中的情节、对话甚至角色名字,都能在训练数据中找到高度相似的片段,无法证明存在独创性表达”,这个案例反映了概率采样机制的“原罪”——生成内容是训练数据的“概率混合”,很难区分哪些部分是模型“创造”的,哪些是“复制”的,这种情况下,数据确权往往倾向于保护原始数据提供者(因为生成内容高度依赖他们的输入),而非模型开发者或用户。
本月时尚潮流与汽车用品热度持续攀升,相关领域迎来新突破 但2026年的生成模型已经进化到“因果推理”阶段,以谷歌的Gemini模型为例,它不仅能预测“下一个词”,还能理解“为什么是这个词”——当输入“今天天气很好,我决定去__”时,模型会先分析“天气好”与“外出”之间的因果关系(天气好→适合外出),再结合训练数据中“外出”的常见场景(公园、商场、运动),生成“公园”“散步”等更合理的输出,这种机制让生成内容不再是对训练数据的简单拼凑,而是基于逻辑推理的“再创造”,2026年6月,英国高等法院审理了一起AI生成广告文案的侵权案:某广告公司用因果推理模型生成了一句广告语“喝XX咖啡,唤醒你的创造力”,被另一家公司起诉抄袭他们2023年的广告语“喝XX茶,激发你的灵感”,法院在审理中发现,虽然两句文案结构相似,但模型的生成逻辑完全不同——前者是基于“咖啡-提神-创造力”的因果链,后者是基于“茶-放松-灵感”的因果链,且训练数据中从未出现过“咖啡”与“创造力”的直接关联,最终法院判定不构成侵权,因为模型的生成过程体现了“独创性的因果推理”,而非对原始数据的复制,这个案例说明:当生成机制从概率采样升级到因果推理,生成内容的“独创性”显著增强,数据确权的重心开始向模型开发者或用户倾斜——因为他们为生成内容提供了“新的逻辑链条”。
权责映射:从“技术中立”到“可追溯链”的构建,让确权有了“实操抓手”
搞懂数据表征和生成机制后,最后一个问题是:如何把技术原理转化为法律上的权责分配?这涉及“权责映射”——如何通过技术手段(如区块链、水印、日志)记录生成过程的每个环节,明确谁在何时做了什么,进而分配权责,2026年,全球主要经济体都在推动“AI生成内容可追溯链”的建设,这是数据确权从理论走向实践的关键一步。 本月绿色设计与绿色湿地保护及边缘计算热度持续上升,相关产业迎来新机遇
以中国的实践为例,2026年1月,国家网信办等七部门联合发布《生成式AI服务可追溯管理规定》,要求所有提供生成式AI服务的平台,必须对训练数据、表征过程、生成机制、输出结果进行全链条记录,并上传至国家AI可追溯平台,训练数据需记录来源(如公开网站、用户上传、合作机构)、获取方式(授权、购买、爬取)、脱敏情况(是否去除个人隐私);表征过程需记录算法版本、参数设置、特征保留/丢弃规则;生成机制需记录输入条件、推理路径、概率分布(如果是概率采样模型);输出结果需记录生成时间、用户ID(如果是面向C端的服务)、是否被修改过,这些记录会生成一个唯一的“可追溯码”,嵌入到生成内容中(如图片的EXIF信息、文本的隐藏字符),用户扫描即可查看完整生成链。
2026年8月,杭州互联网法院审理了一起AI生成视频侵权案:某短视频平台用户用AI生成了一段“明星代言”视频,被明星本人起诉侵犯肖像权,平台提供了一份完整的可追溯链:视频生成于2026年7月15日,使用的模型是“Stable Diffusion 3.0(教育版)”,训练数据来自公开的明星公开活动照片(已获授权),表征过程去除了所有背景信息,只保留面部特征,生成机制是基于用户输入的“穿红色裙子、微笑”等描述词进行因果推理,输出结果未被修改,法院根据可追溯链判定:虽然视频使用了明星的肖像,但训练数据已获授权,表征过程去除了隐私信息,生成机制体现了用户的独创性描述,因此不构成侵权,但明星方提出:模型在表征阶段可能保留了面部特征的“深层编码”,这些编码是否属于肖像权范畴?法院参考了《AI数据治理条例》中“生物特征数据的可追溯规则”,要求平台提供表征算法的源代码,证明其未存储或复用原始面部数据,最终平台通过开源算法证明了清白 近期热度不断攀升绿色补贴热度持续攀升,相关应用不断深化