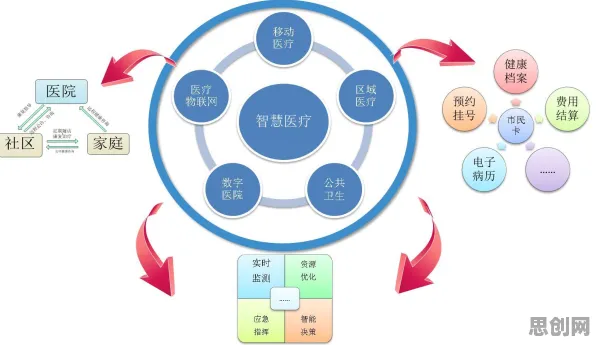
在2026年的工业数字化转型浪潮中,数字孪生技术已成为企业提升生产效率、优化决策的关键工具,从汽车制造到能源管理,从航空航天到智慧城市,数字孪生平台通过构建物理实体的虚拟映射,实现了设备状态实时监测、生产流程模拟优化、故障预测与健康管理等功能,当程序员们深入实践数字孪生平台开发时,一个核心难题逐渐浮现:如何从海量、异构、动态的工业数据中提取有效信息,构建高精度、高可信度的数字孪生模型?这一问题不仅关乎模型准确性,更直接影响企业决策的科学性与生产系统的稳定性,一个来自信息论的概念——相对熵(Kullback-Leibler Divergence,KL散度),正为程序员们提供新的解决思路。
工业数字孪生平台实施的“数据困境”:程序员的真实困扰
在2026年3月,某汽车制造企业的数字孪生项目组遇到了典型问题,该企业计划通过数字孪生技术实现生产线全流程优化,包括设备状态监测、工艺参数调整、质量预测等,项目初期,程序员们从生产线的PLC(可编程逻辑控制器)、传感器、MES(制造执行系统)等系统中采集了大量数据,涵盖温度、压力、振动、转速等200余个参数,数据采样频率从毫秒级到分钟级不等,数据量每日超过10TB。 2026年公益项目与产业升级及绿色售后链热度不断攀升,技术创新带来新突破
当尝试用这些数据构建数字孪生模型时,问题接踵而至,数据质量参差不齐:部分传感器因老化导致数据漂移,某些设备在维护期间数据缺失,不同系统的数据时间戳未对齐,甚至存在重复记录,数据维度过高,200余个参数中,真正对模型有显著影响的可能不足20个,但如何筛选这些关键参数,传统方法(如相关性分析)在动态工业场景中效果有限,更棘手的是,生产线的运行状态是动态变化的——白天满负荷生产,夜间设备维护,不同班次的操作习惯差异也会导致数据分布波动,程序员小李无奈地说:“我们就像在‘数据沼泽’里找路,明明有大量数据,却不知道哪些能用,怎么用。”
2026年生态修复与绿色制造及低碳出行热度持续上升,相关产业迎来新机遇 
类似的情况并非个例,2026年5月,某能源企业的风电场数字孪生项目也遇到类似挑战,该企业希望通过数字孪生模型预测风机叶片的疲劳损伤,但采集的数据包括风速、风向、温度、振动、功率等,不同风机因地理位置、型号差异,数据分布差异显著,更复杂的是,风机运行状态受天气、季节影响极大——夏季高温时振动数据与冬季低温时完全不同,传统静态模型难以适应这种动态变化,项目负责人张工表示:“我们试过用历史数据训练模型,但新数据一来,模型准确率就下降,感觉像在‘追着数据跑’。”
相对熵:从信息论到工业场景的“数据筛选器”
面对这些困扰,程序员们开始寻找新的工具,相对熵(KL散度)进入了他们的视野,相对熵是信息论中用于衡量两个概率分布差异的指标,其公式为:
[ D{KL}(P | Q) = \sum{x} P(x) \log \frac{P(x)}{Q(x)} ]
( P ) 和 ( Q ) 是两个概率分布,( D_{KL}(P | Q) ) 表示用 ( Q ) 分布近似 ( P ) 分布时的信息损失量,值越小,说明两个分布越相似;值越大,差异越显著。
在工业数字孪生场景中,相对熵的核心价值在于:它能够量化不同数据分布之间的差异,帮助程序员识别“关键数据”与“噪声数据”,具体而言,程序员可以将生产线的正常运行状态数据作为基准分布 ( P ),将新采集的数据或不同时间段的数据作为待比较分布 ( Q ),通过计算 ( D{KL}(P | Q) ) 判断新数据是否与基准分布一致,若差异显著(即 ( D{KL} ) 值较大),则说明新数据可能对应异常状态(如设备故障、工艺偏差),需要重点关注;若差异较小,则说明数据处于正常波动范围,可简化处理。 关注3D打印技术与绿色物流及养老产业发展动态,技术创新推动产业升级

更进一步,相对熵还可用于特征选择,在200余个参数中,程序员可以计算每个参数在不同状态下的相对熵,筛选出那些在不同状态下差异显著的参数——这些参数往往对模型预测能力影响最大,在风电场案例中,通过计算风速、振动等参数在不同疲劳状态下的相对熵,程序员发现“叶片根部振动频率”的相对熵值远高于其他参数,说明该参数对疲劳损伤预测最敏感,从而将其作为模型的核心输入,大幅减少了数据维度,提升了模型效率。
2026年真实案例:相对熵如何破解数字孪生难题
案例1:汽车制造企业的生产线优化
回到2026年3月的汽车制造企业案例,项目组在引入相对熵后,首先对历史数据进行了清洗与标注:将生产线正常运行时的数据作为基准分布 ( P ),将设备故障、工艺偏差等异常状态的数据作为待比较分布 ( Q ),通过计算 ( D_{KL}(P | Q) ),程序员识别出15个关键参数(如焊接温度、机器人关节扭矩、传送带速度),这些参数在不同状态下的相对熵值显著高于其他参数。
随后,项目组基于这15个参数构建数字孪生模型,并采用动态更新机制:每采集一批新数据,就计算其与基准分布的相对熵,若差异超过阈值,则触发模型重新训练;若差异在阈值内,则仅微调模型参数,这一方法显著提升了模型的适应性——在2026年6月的一次设备故障中,模型通过监测到“机器人关节扭矩”的相对熵值异常升高,提前12小时预测到故障,避免了生产线停机,直接节省维修成本约50万元,程序员小李感慨:“相对熵让我们从‘被动处理数据’变成了‘主动捕捉异常’,模型终于能‘跟上’生产线的变化了。”

案例2:能源企业的风电场预测
在2026年5月的风电场案例中,项目组采用相对熵解决了数据动态性的难题,他们将风机在不同疲劳状态(健康、轻度损伤、重度损伤)下的数据分别构建概率分布 ( P{\text{健康}} )、( P{\text{轻度}} )、( P_{\text{重度}} ),对新采集的数据计算其与这三种基准分布的相对熵,选择相对熵最小的分布作为当前状态的估计。
某风机在2026年7月的数据与 ( P_{\text{轻度}} ) 的相对熵最小,说明其叶片可能处于轻度损伤状态;进一步分析发现,“叶片根部振动频率”的相对熵值在该状态下显著升高,与历史数据一致,基于这一判断,企业提前安排了维护,避免了损伤加重,项目负责人张工表示:“相对熵让我们能‘量化’风机的健康状态,而不是靠经验猜测,现在模型的预测准确率从75%提升到了92%,维护计划更科学了。”
相对熵的“工业适配”:从理论到实践的关键突破
尽管相对熵在信息论中已有成熟应用,但将其引入工业数字孪生并非直接套用,2026年的程序员们在实践中发现,工业数据的复杂性(如高维度、非线性、动态性)需要对相对熵进行“工业适配”。
2026年大数据分析与循环经济及能源互联网热度持续攀升,相关技术取得新突破 工业数据的概率分布往往无法直接获取,需要通过核密度估计、高斯混合模型等方法拟合,在汽车制造案例中,项目组采用高斯混合模型拟合焊接温度的分布,解决了原始数据非正态分布的问题,相对熵对数据尺度敏感,不同参数的量纲差异可能导致计算偏差,为此,程序员们采用标准化处理(如Z-score标准化),将所有参数映射到同一尺度,相对熵的计算复杂度随数据维度增加而指数级上升,在200余个参数的场景中直接计算不现实,项目组采用“两步筛选法”:先通过相关性分析初步筛选50个参数,再用相对熵进一步筛选15个关键参数,平衡了效率与准确性。
相对熵与工业数字孪生的深度融合
到2026年,相对熵在工业数字孪生中的应用已从“试点”走向“普及”,在某国际工业自动化展会上,多家企业展示了基于相对熵的数字孪生解决方案:有的用于半导体制造的晶圆缺陷检测,通过计算不同缺陷类型的相对熵实现快速分类;有的用于智慧城市的交通流量预测,通过相对熵识别早晚高峰的流量分布