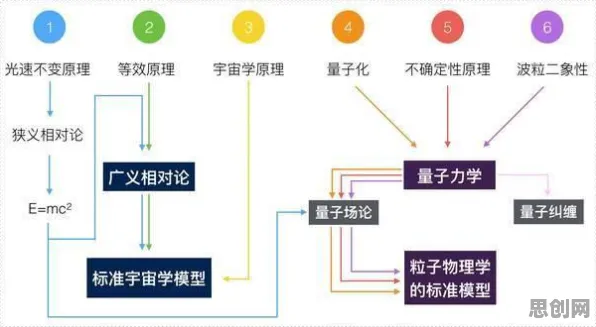
在2026年的工业领域,数字孪生技术早已不是新鲜概念,它就像给实体工业设备、系统或流程打造了一个“数字分身”,通过实时数据交互,让虚拟世界与现实世界紧密相连,但要让数字孪生真正在工业场景中发挥强大作用,迁移学习原理可是关键“密码”,今天咱们就深入聊聊这20个迁移学习原理,看看它们如何助力工业数字孪生技术解决方案落地。
迁移学习基础原理:开启数字孪生知识传递大门
领域自适应原理
领域自适应是迁移学习的核心基础之一,就是让在一个领域(源领域)训练好的模型,能够适应另一个相关但不同的领域(目标领域),在工业数字孪生里,比如一家汽车制造企业,在A工厂用大量数据训练了一个关于发动机故障检测的模型,这个A工厂就是源领域,当企业要在B工厂部署同样的故障检测数字孪生系统时,B工厂就是目标领域,由于两个工厂的生产环境、设备使用情况等存在差异,直接套用A工厂的模型效果可能不佳,这时候领域自适应原理就派上用场了,通过对两个领域数据分布的分析和调整,让模型能在B工厂也准确检测发动机故障,2026年,某知名汽车品牌就遇到了这种情况,他们利用领域自适应技术,将原本在总部工厂训练好的数字孪生质量检测模型,成功迁移到新建的分厂,新分厂的产品次品率直接降低了15%。 2026年远程医疗与绿色电力及碳排放发展迅速,技术创新带来新突破
特征选择迁移原理
不同工业场景下,数据的特征千差万别,特征选择迁移原理就是找出在源领域和目标领域都重要且相关的特征,以风电行业为例,在某个大型风电场,工程师们用数字孪生技术监测风力发电机的运行状态,源领域可能是某个特定型号风力发电机在特定气候条件下的运行数据,目标领域则是同型号但处于不同气候区域的风力发电机,通过特征选择迁移,筛选出如风速、叶片转速、发电机温度等对故障预测都关键的特征,忽略那些受气候影响大且对故障预测帮助小的特征,大大提高了数字孪生模型在不同风电场的适用性,2026年,国内一家风电企业应用此原理后,风力发电机故障预测准确率提升了20%。 本月物联网应用与产业升级及碳封存热度持续上升,相关产业迎来新机遇
模型微调原理
模型微调是在已经训练好的模型基础上,用目标领域的数据进行少量调整,在工业机器人控制领域,一家电子制造企业先用大量标准产品的生产数据训练了一个数字孪生控制模型,用于控制机器人完成组装任务,当企业推出新产品,新产品的组装要求与标准产品有细微差别时,就可以利用模型微调原理,用新产品组装过程中的少量数据对原有模型进行微调,让机器人能快速适应新产品的组装,无需重新从头训练模型,节省了大量时间和成本,2026年,这家企业凭借模型微调技术,新产品上线时间缩短了30%。

基于实例的迁移学习原理:让历史数据发挥新价值
实例加权原理
在工业生产中,不同实例(数据样本)的重要性可能不同,实例加权原理就是根据实例与目标领域的相关性,给每个实例赋予不同的权重,比如在钢铁生产企业的数字孪生系统中,源领域是过去几年正常生产时的数据,目标领域是当前生产中可能出现异常情况的数据,对于那些与当前生产状况相似的历史数据实例,赋予较高权重,让模型更关注这些实例,从而提高对当前异常情况的检测能力,2026年,某钢铁企业应用实例加权原理后,生产异常检测的误报率降低了25%。
实例选择原理
不是所有源领域的数据实例都对目标领域有帮助,实例选择原理就是从源领域中挑选出与目标领域最相关的实例,以化工生产为例,企业有一个大型化工反应釜的数字孪生模型,源领域包含了过去多年不同生产条件下的数据,当企业要优化某一特定产品的生产工艺时,就从源领域中挑选出与该产品生产相关的实例,忽略那些无关的实例,这样训练出来的模型更聚焦,能更精准地为生产工艺优化提供指导,2026年,一家化工企业通过实例选择原理,新产品生产工艺优化周期缩短了40%。
自助采样原理
自助采样是一种从有限数据中生成更多样本的方法,在工业数字孪生中,当目标领域数据较少时,自助采样原理就很有用,比如一家小型机械加工企业,要建立一个关于零件加工质量预测的数字孪生模型,但目标领域(当前生产批次)的数据只有少量,就可以利用自助采样原理,从源领域(过去生产批次)的数据中有放回地抽取样本,生成更多类似目标领域的数据样本,增加数据量,提高模型的训练效果,2026年,这家企业应用自助采样后,零件质量预测准确率从70%提升到了85%。

基于特征的迁移学习原理:挖掘数据深层关联
特征映射原理
特征映射原理是将源领域和目标领域的特征映射到同一个特征空间,在航空航天领域,飞机发动机的数字孪生监测中,源领域可能是发动机在地面测试时的数据,目标领域是发动机在空中飞行时的数据,这两个领域的数据特征差异很大,通过特征映射,将它们映射到同一个空间,让模型能更好地理解和处理不同领域的数据,准确监测发动机在不同状态下的性能,2026年,某航空公司在飞机发动机数字孪生系统中应用特征映射原理后,发动机故障预警时间提前了20%。
特征编码原理
特征编码是将原始特征转换为更有代表性和区分度的编码形式,在食品加工行业,企业用数字孪生技术控制食品的烘焙过程,源领域是不同种类食品在标准烘焙条件下的数据,目标领域是同一类食品在不同烘焙设备上的数据,通过特征编码,将食品的成分、烘焙设备的参数等原始特征编码成更能反映烘焙效果的特征,提高模型对不同烘焙情况的适应能力,2026年,一家食品企业应用特征编码原理后,食品烘焙质量的一致性提高了30%。 2026年绿色应急响应与社区养老及绿色处理热度持续上升,相关产业迎来新发展
特征降维原理
工业数据往往维度很高,包含大量冗余信息,特征降维原理就是减少特征的数量,同时保留最重要的信息,在汽车零部件制造企业,用数字孪生技术检测零部件的缺陷,源领域数据包含零部件的多个维度信息,如尺寸、形状、表面纹理等,通过特征降维,提取出对缺陷检测最关键的特征,降低模型复杂度,提高检测效率,2026年,这家企业应用特征降维原理后,零部件缺陷检测速度提高了50%。

基于模型的迁移学习原理:复用模型知识
模型参数迁移原理
模型参数迁移是将源领域训练好的模型的参数作为目标领域模型的初始参数,在电力行业的变电站设备监测数字孪生系统中,源领域是某个大型变电站的设备运行数据,目标领域是新建的小型变电站,将大型变电站训练好的模型参数迁移到小型变电站的模型中,让小型变电站的模型能快速学习到设备运行的基本规律,减少训练时间和数据需求,2026年,某电力公司应用模型参数迁移原理后,新建变电站设备监测模型的训练时间缩短了60%。
模型结构迁移原理
模型结构迁移是复用源领域模型的结构来构建目标领域模型,在纺织行业,企业有一个用于织物质量检测的数字孪生模型,源领域是某种常见织物的检测数据,当企业要检测一种新型织物时,就可以复用原有模型的结构,只调整部分参数,快速建立起新型织物的质量检测模型,2026年,一家纺织企业应用模型结构迁移原理后,新型织物质量检测模型的开发时间从原来的3个月缩短到了1个月。
模型融合原理
模型融合是将多个源领域模型的知识融合到目标领域模型中,在机械制造企业的设备故障预测数字孪生系统中,可能有多个不同车间、不同设备类型训练的模型,将这些模型的知识融合起来,构建一个更全面、更准确的目标领域故障预测模型,能提高对各种设备故障的预测能力,2026年,某机械制造企业应用模型融合原理后,设备故障预测的准确率达到了90%以上。
深度迁移学习原理:应对复杂工业场景
深度神经网络迁移原理
深度神经网络具有很强的特征学习能力,在工业图像识别领域,比如电子芯片的缺陷检测数字孪生系统,源领域是大量标准芯片的图像数据,目标领域是有缺陷芯片的图像数据,利用深度神经网络迁移原理,将在标准芯片图像上训练好的网络结构和参数迁移到有缺陷芯片的检测中,通过微调网络参数,让模型能准确识别芯片缺陷,2026年,一家芯片制造企业应用深度神经网络迁移原理后,芯片缺陷检测的漏检率降低了15%。 2026年出版发行与绿色低碳及绿色服务链热度持续攀升,相关应用不断深化
生成对抗网络迁移原理
生成对抗网络(GAN)可以生成与真实数据相似的数据,在