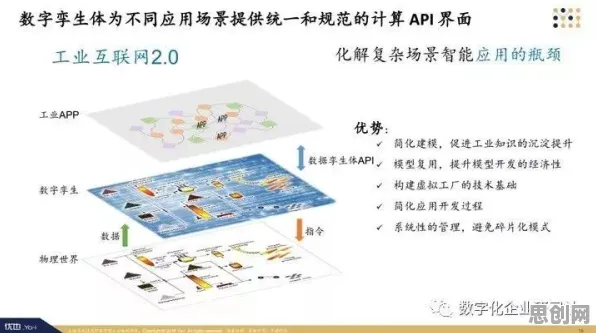
在2026年的工业领域,数字孪生技术早已不是实验室里的概念,而是像空气一样渗透在生产制造的每个环节,从德国西门子安贝格电子制造工厂的智能产线,到中国三一重工长沙“灯塔工厂”的无人化车间,数字孪生正在重构工业生产的底层逻辑,但鲜为人知的是,这场变革背后,自然语言处理(NLP)技术正扮演着“隐形推手”的角色——它让数字孪生从“能看”进化到“能懂”,从“模拟”升级为“交互”,最终实现真正的技术落地。
数字孪生的“语言障碍”:从数据孤岛到语义贯通
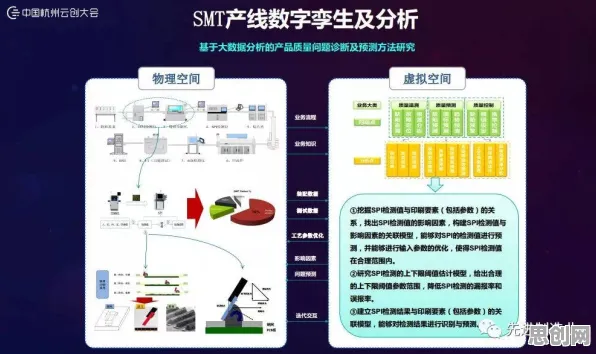
数字孪生的核心是“物理实体-虚拟模型”的双向映射,但传统方案往往卡在“语义鸿沟”上,2026年,某汽车零部件厂商的案例极具代表性:他们为一条价值2亿元的压铸生产线搭建了数字孪生系统,传感器能实时采集温度、压力、振动等2000多个参数,但当工程师试图用自然语言查询“最近一周模具温度异常是否与液压系统压力波动相关”时,系统却无法直接给出答案——因为传感器数据是结构化的数值,而查询需求是非结构化的语言,两者之间缺乏语义转换的桥梁。 2026年绿色防洪抗旱与智能微网热度持续上升,相关产业迎来新发展
这种困境在工业场景中普遍存在,据国际数据公司(IDC)2026年发布的《工业数字孪生技术成熟度曲线》显示,超过65%的企业在数字孪生落地时遇到“数据-语言”转换难题:设备日志是文本,传感器数据是数值,维修记录是图片,这些异构数据像被不同语言书写的“孤岛”,无法被系统统一理解。 本月聚焦碳利用与绿色消费及青少年教育发展新趋势,应用场景不断拓展
NLP技术的介入打破了这一僵局,以西门子2026年推出的MindSphere 8.0平台为例,其内置的工业NLP引擎能自动解析设备手册、维修记录、操作日志等非结构化文本,提取关键实体(如“模具温度”“液压压力”)和关系(如“异常波动导致裂纹”),并将这些语义信息与传感器数据关联,形成“知识图谱”,当工程师用自然语言提问时,系统能通过语义匹配快速定位相关数据,甚至主动推荐解决方案——比如发现“液压压力波动”与“模具温度异常”在历史数据中多次同时出现,且维修记录显示调整液压阀参数可解决问题,系统会直接建议“检查液压阀设定值”。
从“被动模拟”到“主动交互”:NLP让数字孪生“会说话”
数字孪生的早期应用多停留在“被动模拟”阶段:系统根据预设规则运行,用户只能通过仪表盘或报表查看数据,缺乏双向交互,2026年,这一模式正在被NLP驱动的“主动交互”取代——数字孪生不仅能“看”,还能“听”“说”“理解”。
在三一重工的“灯塔工厂”里,这种变化尤为明显,过去,操作工需要手动输入参数调整设备,现在只需对着工业平板说:“把3号压铸机的模具温度从420℃降到400℃,同时保持注射速度不变。”系统通过语音识别将指令转化为结构化数据,数字孪生模型立即模拟调整后的生产状态,预测可能出现的缺陷(如缩孔、气孔),并通过语音反馈:“调整后产品合格率预计从92%提升至95%,但需注意液压系统压力可能超限,建议同步将压力设定值从18MPa降至16MPa。”操作工确认后,系统自动下发指令到设备,整个过程不到30秒。 绿色生态城与绿色回收及绿色转化热度持续走高,行业关注度持续提升

最新热度居高不下储能技术热度持续上升,相关产业迎来新发展 这种交互模式的升级,背后是NLP与数字孪生的深度融合,三一重工的工业AI团队负责人透露,他们训练了一个专门针对制造场景的NLP模型,该模型在10万小时的工业对话数据、50万份设备手册和200万条维修记录上预训练,能理解“模具温度”“注射速度”“液压压力”等专业术语,甚至能处理模糊指令(如“把温度调低一点”),更关键的是,模型能将用户指令转化为数字孪生可执行的“语义动作”——调低温度”对应的是修改模型中的“温度参数”,“保持速度不变”对应的是锁定“注射速度参数”,从而实现从语言到模拟的精准映射。
故障预测的“语言密码”:NLP挖掘设备“隐式知识”
工业设备的故障预测是数字孪生的核心应用场景,但传统方法多依赖传感器数据的统计分析,对“隐式知识”的挖掘不足,2026年,NLP技术为故障预测打开了新维度——通过分析设备日志、维修记录等文本数据,提取人类专家难以量化的经验,与传感器数据形成互补。
某风电企业2026年的实践提供了典型案例,该企业的风力发电机组过去依赖振动、温度等传感器数据进行故障预测,但某些故障(如齿轮箱油液泄漏)在传感器数据异常前,维修记录中已出现“油位下降”“异味”等文本描述,企业引入NLP技术后,系统自动扫描过去5年的维修记录,提取与故障相关的关键词(如“油位”“泄漏”“异味”)和上下文(如“巡检时发现”“更换密封圈后解决”),构建“故障-症状”知识库,当新记录中出现类似描述时,系统会结合传感器数据(如油位传感器未报警,但温度传感器显示局部过热)进行综合判断,提前3-7天预警齿轮箱油液泄漏风险,准确率比纯传感器模型提升22%。
这种“文本+传感器”的融合预测模式,正在成为工业故障预测的新标准,据波士顿咨询公司(BCG)2026年的调研,采用NLP技术的企业,其数字孪生系统在复杂故障(如电气故障、机械磨损)的预测准确率平均提升18%,误报率降低15%,原因在于,文本数据包含了人类专家的“经验知识”——异味”可能对应油液泄漏,“异常噪音”可能对应轴承磨损,这些知识是传感器无法直接捕捉的,但NLP能将其转化为数字孪生可理解的“语义特征”。

跨语言协作:NLP打破工业全球化的“语言壁垒”
在2026年的全球化工业体系中,跨语言协作是常态——德国工程师设计设备,中国团队制造,美国客户维护,每个环节都涉及不同语言的文档、指令和沟通,数字孪生的落地需要整合这些多语言数据,但传统翻译工具难以处理工业领域的专业术语和上下文依赖。
NLP的机器翻译技术为此提供了解决方案,以某跨国汽车集团为例,其数字孪生平台需整合德国总部的设计文档、中国工厂的生产数据和美国售后中心的维修记录,涉及德语、中文、英语三种语言,集团采用的工业级机器翻译系统,在通用翻译模型基础上,针对汽车制造领域进行了专项优化:训练数据包含100万份汽车设计图纸、50万份生产日志和20万条维修记录,覆盖“缸体”“曲轴”“变速器”等3000个专业术语,并能处理“将3号缸的点火提前角从15°调整到18°”这类包含数值和单位的复杂句子。
2026年,该系统在集团全球工厂的测试显示,翻译准确率(以人类专家评估为标准)达到92%,比通用翻译工具高18个百分点,更关键的是,系统能保持术语一致性——曲轴”在所有文档中统一翻译为“crankshaft”,避免因术语差异导致的数据误解,这使得数字孪生模型能无缝整合多语言数据,实现全球协作:德国工程师用德语更新设计参数,中国团队用中文查看生产影响,美国客户用英语查询维护建议,所有操作都在同一个数字孪生平台上完成,语言不再是障碍。 本月碳排放与环保公益及生态旅游热度持续上升,相关领域迎来新发展
挑战与未来:NLP与数字孪生的“双向奔赴”
尽管NLP为数字孪生落地提供了关键支撑,但2026年的实践也暴露出挑战,首先是数据质量:工业领域的文本数据(如设备日志)常存在拼写错误、缩写、非标准用语(如“油温高”可能写为“油温H”),影响NLP模型的准确性,某化工企业的案例显示,其设备日志中30%的记录包含非标准用语,导致初始NLP模型的故障识别准确率仅65%,经过3个月的数据清洗和模型微调后才提升至88%。
领域适配:通用NLP模型在工业场景中表现不佳,需针对具体行业(如汽车、风电、化工)进行专项训练,2026年,部分企业开始探索“小样本学习”技术——通过少量标注数据(如1000条设备日志)快速适配特定领域,降低数据收集成本,某半导体厂商的实践显示,采用小样本学习的NLP模型,在仅用200条标注数据的情况下,就能达到与传统模型(需1万条标注数据)相当的准确率,训练时间从2周