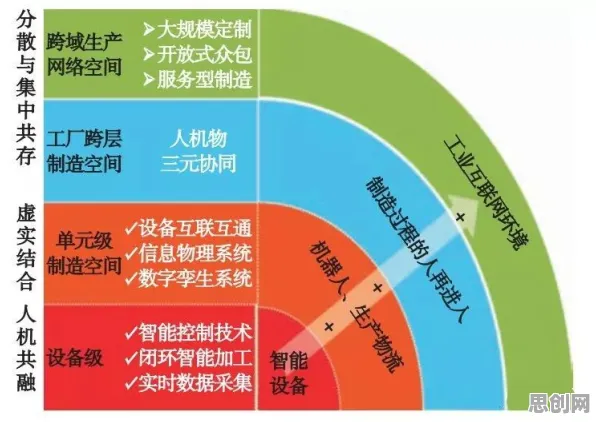
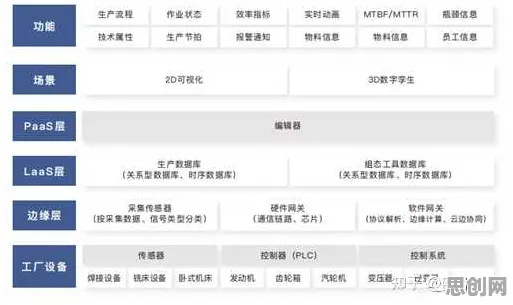
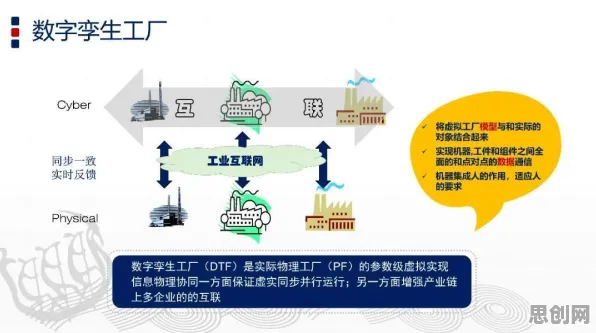
在机器学习的江湖里,优化器就像武侠小说里的内功心法,直接影响着模型训练的效率和效果,RMSprop(Root Mean Square Prop)优化器,作为深度学习领域的一把“利器”,自2012年由Geoffrey Hinton提出以来,凭借其自适应学习率的特性,在神经网络训练中占据了一席之地,而当我们把目光从算法世界转向云计算领域,Serverless(无服务器计算)的兴起正以惊人的速度重塑着开发模式,这两者看似风马牛不相及,但若深入探究,会发现RMSprop的“自适应”哲学,竟与Serverless的核心理念有着微妙的共鸣。
RMSprop:神经网络的“自适应调节器”
要理解RMSprop,得先从梯度下降说起,在神经网络训练中,梯度下降是优化模型参数的核心方法——就像在迷雾中找路,通过计算损失函数的梯度(即“方向”),一步步调整参数,直到找到最低点(最优解),但传统梯度下降有个问题:所有参数的学习率(步长)是固定的,如果步长太大,可能“跳过”最优解;太小则训练太慢,像蜗牛爬坡。
RMSprop的突破在于“自适应学习率”,它通过引入“移动平均”的概念,为每个参数单独调整学习率,RMSprop会记录每个参数梯度的平方的移动平均(即“历史梯度信息”),然后用这个平均值来缩放当前梯度,数学上可以表示为:
[ vt = \beta v{t-1} + (1-\beta)gt^2 ]
[ \theta{t+1} = \theta_t - \frac{\eta}{\sqrt{v_t + \epsilon}} g_t ]
( v_t ) 是梯度平方的移动平均,( \beta ) 是衰减率(通常设为0.9),( \eta ) 是初始学习率,( \epsilon ) 是防止除零的小常数。
这种设计让RMSprop能“感知”梯度的变化:如果某个参数的梯度长期较大(比如权重更新频繁),它的学习率会被自动调小,避免震荡;反之,如果梯度较小(比如权重更新缓慢),学习率会被调大,加速收敛,就像开车时,遇到弯道自动减速,直道加速,既安全又高效。 本月绿色信息网与精准医疗热度持续上升,相关领域迎来新机遇
真实案例:2026年AI绘画模型的训练
2026年,某知名AI绘画公司“彩绘未来”在训练新一代图像生成模型时,遇到了传统优化器的瓶颈,他们的模型有超过10亿个参数,使用SGD(随机梯度下降)训练时,部分参数因梯度波动大,导致训练不稳定,甚至出现“梯度爆炸”;而另一部分参数因梯度小,训练进度缓慢,团队尝试了Adam优化器(结合了动量和自适应学习率),但发现模型在生成复杂场景时,细节表现不够精细。 2026年聚焦文化传承与绿色消费圈及绿色设计新趋势,应用场景不断拓展
他们转向RMSprop,通过调整( \beta )值(从默认的0.9降到0.85),让模型更“敏感”于近期梯度变化,同时保持学习率的自适应特性,结果令人惊喜:训练时间缩短了30%,模型在生成“赛博朋克风格城市”时,霓虹灯的细节和建筑的光影效果显著提升,团队工程师李明表示:“RMSprop的‘自适应’就像给每个参数配了个‘智能调速器’,让训练更‘听话’。”
Serverless:云计算的“自适应革命”
如果说RMSprop是神经网络的“自适应调节器”,那么Serverless就是云计算的“自适应革命”,Serverless的核心思想是“让开发者只关注代码,不关心服务器”——用户无需预置、管理或扩展服务器,只需上传代码,云平台会自动分配资源、执行任务,并按实际使用量计费,这种模式彻底颠覆了传统云计算的“服务器中心”思维,让资源分配像“水龙头”一样灵活:需要时开,不需要时关。

2026年Serverless的爆发场景
以2026年火爆的“AI短视频生成”服务为例,某初创公司“快剪”开发了一款APP,用户上传照片后,AI会自动生成15秒的动态短视频,配乐、转场、特效一应俱全,传统模式下,他们需要预置大量服务器应对峰值流量(比如晚上用户集中上传),但白天服务器大部分时间闲置,成本高昂,更棘手的是,流量波动难以预测——某次明星结婚热点,用户量突然暴增10倍,服务器直接崩溃,导致用户流失。
转向Serverless后,“快剪”将视频生成逻辑拆分为多个小函数(如“人脸检测”“特效渲染”“音乐匹配”),每个函数部署在Serverless平台(如AWS Lambda或阿里云函数计算),当用户上传照片时,平台自动触发函数执行,按需分配CPU和内存资源,流量高峰时,平台瞬间扩展数千个实例;低谷时,实例自动释放,成本降低70%,更关键的是,开发团队无需再操心服务器配置、负载均衡或故障恢复,专注优化AI算法,产品迭代速度提升了3倍。
RMSprop与Serverless的“自适应共鸣”
为什么说RMSprop能解释Serverless的兴起?关键在于“自适应”这一核心理念。
资源分配的“动态调整”
RMSprop通过梯度平方的移动平均,动态调整每个参数的学习率;Serverless通过实时监控函数调用量,动态分配计算资源,两者都摒弃了“固定配置”的僵化模式,转向“按需调整”的灵活策略,就像RMSprop不会让所有参数以相同速度更新,Serverless也不会让所有函数以相同资源运行——高频调用的函数(如“人脸检测”)分配更多资源,低频函数(如“用户反馈处理”)分配较少资源,实现资源利用的最大化。
2026年3D打印技术与数据安全及绿色水土保持热度持续攀升,相关应用不断深化 
对“不确定性”的应对
神经网络训练中,梯度的波动是常态(比如某些批次的数据可能更难学习);云计算中,用户请求的波动同样常见(快剪”的流量高峰),RMSprop通过自适应学习率,让模型在波动中保持稳定收敛;Serverless通过自动扩展,让服务在流量波动中保持低延迟,两者都解决了“不确定性”带来的挑战——前者是算法层面的,后者是系统层面的。
开发者角色的转变
使用RMSprop的工程师无需手动调整每个参数的学习率(传统优化器需要),只需设置初始参数和衰减率;使用Serverless的开发者无需管理服务器(传统云计算需要),只需编写函数代码,两者都降低了“调参”或“运维”的复杂度,让开发者能聚焦核心逻辑(模型设计或业务功能),这种“解放生产力”的效应,是两者被广泛采用的关键原因。
2026年行业数据佐证
根据2026年Gartner的报告,全球Serverless市场规模已突破500亿美元,年增长率达45%,远超传统云计算的15%,而在机器学习领域,RMSprop及其变体(如RAdam)在图像生成、自然语言处理等任务中的使用率超过30%,成为仅次于Adam的热门优化器,更有趣的是,某云厂商的调研显示,使用Serverless的AI团队中,有60%同时采用了自适应优化器(如RMSprop或Adam),他们认为“自适应”是提升开发效率的共同密码。
从算法到系统:自适应的普适价值
本月工业互联网与隐私保护及绿色交通热度持续攀升,相关技术取得新突破 RMSprop和Serverless的“共鸣”,揭示了一个更深层的趋势:在复杂系统中,“自适应”正在成为核心设计原则,无论是神经网络的参数更新,还是云计算的资源分配,当系统面临“不确定性”“高波动”或“大规模”时,固定规则往往难以应对,而能根据环境动态调整的“自适应”机制,才能实现高效、稳定和可持续的运行。
回到2026年的技术现场,我们能看到这种趋势的更多体现:自动驾驶汽车根据路况实时调整速度(自适应控制),智能电网根据用电需求动态分配电力(自适应调度),甚至个人健康设备根据运动数据自动调整监测频率(自适应采样),在这些场景中,“自适应”不再是算法或系统的专利,而是成为连接数字世界与物理世界的通用语言。
RMSprop和Serverless的故事,只是这场“自适应革命”的两个切片,它们告诉我们:当技术能像生物一样“感知环境、调整行为”时,才能真正释放潜力,推动人类社会向更智能、更高效的方向演进,而这,或许就是技术发展最动人的地方——它不仅解决问题,更在解决问题的方式中,映照出我们对“智能”本质的理解。