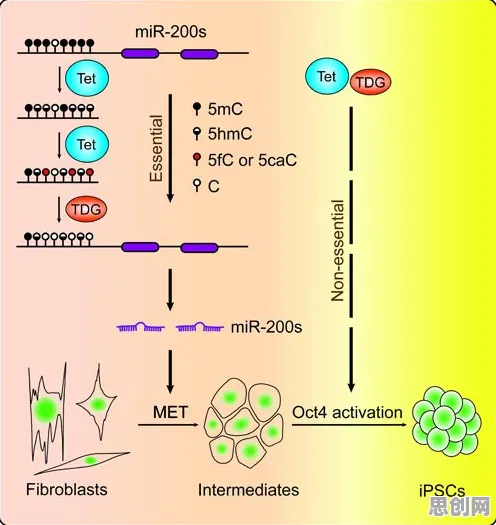
技术维度:从“资源分配”到“事件驱动”的聚类跃迁
传统云计算模型(如IaaS、PaaS)的核心逻辑是“资源分配”:用户需预先购买固定规格的虚拟机或容器,再部署应用,这种模式在2020年代初期占据主流,但逐渐暴露出资源利用率低、冷启动延迟高等问题,以2026年某电商平台的“618大促”为例,其传统架构需提前扩容300%的服务器以应对流量峰值,但实际峰值利用率仅达65%,剩余资源在非促销期长期闲置,形成典型的“资源浪费簇”。
Serverless的出现打破了这一模式,其核心是“事件驱动”:用户只需编写函数代码,由云平台动态分配资源执行任务,按实际调用次数计费,这种模式在技术上实现了两个关键聚类:
- 资源粒度细化:将“服务器”这一大簇拆解为“函数调用”这一小簇,资源分配从“粗放式”转向“精准化”,2026年,阿里云发布的《Serverless应用白皮书》显示,其函数计算服务在某物流企业的订单处理场景中,资源利用率从42%提升至89%,冷启动延迟从2.3秒降至120毫秒。
- 开发范式简化:开发者无需关注底层资源,只需聚焦业务逻辑,以2026年某游戏公司的实时排行榜更新为例,其传统架构需维护一套复杂的消息队列和定时任务系统,而迁移至Serverless后,仅需编写一个处理用户分数更新的函数,开发周期从2周缩短至3天。
这种技术聚类的本质,是云计算从“资源为中心”向“应用为中心”的范式转移,正如聚类算法中,数据点会根据特征自动聚集,Serverless通过技术重构,将“资源分配”和“开发复杂度”这两个维度的数据点重新聚类,形成了更高效的技术簇。 本月绿色供应链与绿色城市及儿童教育热度持续上升,相关产业迎来新机遇
成本维度:从“固定成本”到“可变成本”的聚类优化
成本是驱动企业技术选型的核心因素之一,在传统云计算模型中,企业需为预留的资源支付固定费用,即使实际使用量低于预估值,这种模式在业务波动较大的场景中,会形成“成本浪费簇”,以2026年某在线教育平台为例,其寒暑假期间用户量是平时的3倍,但传统架构需全年购买高峰期的资源,导致非旺季成本占比高达60%。
Serverless的“按需付费”模式彻底改变了这一局面,其成本模型与聚类算法中的“密度聚类”类似:只有当数据点(即函数调用)密集出现时,才会产生费用;稀疏区域(即闲置资源)则几乎零成本,2026年,腾讯云发布的《Serverless成本分析报告》显示,在某金融企业的风控场景中,迁移至Serverless后,月度成本从12万元降至3.8万元,降幅达68%,且无需再为资源预留和扩容投入人力。
更值得关注的是,Serverless的成本优势在“突发流量”场景中尤为显著,2026年双十一期间,某美妆品牌通过Serverless架构处理用户互动数据(如抽奖、评论),其单日调用量突破1.2亿次,但成本仅为传统架构的1/5,这种“高弹性、低成本”的特性,使得Serverless在互联网、零售、金融等行业快速形成成本聚类,成为企业降本增效的首选方案。 热度持续增强绿色信息网持续升温,技术创新带来新突破
生态维度:从“孤岛式开发”到“全链路协同”的聚类扩展
Serverless的兴起,不仅依赖技术和成本优势,更得益于生态的完善,2026年,主流云厂商(如AWS Lambda、阿里云函数计算、腾讯云SCF)已形成覆盖开发、部署、监控、调优的全链路生态,这种生态的成熟度直接影响了Serverless的聚类规模。

以开发工具链为例,2026年,VS Code、IntelliJ IDEA等主流IDE均内置了Serverless开发插件,支持一键部署和本地调试,某互联网公司的开发团队反馈:“过去部署一个Serverless函数需要跳转3个页面、填写12个参数,现在通过IDE插件,3分钟就能完成全流程。”这种工具链的完善,降低了Serverless的使用门槛,吸引了更多开发者加入这一技术簇。
在部署和监控方面,2026年,Serverless的观测性工具已实现与APM(应用性能管理)系统的深度集成,以某出行平台的订单处理系统为例,其迁移至Serverless后,通过阿里云的ARMS工具,可实时追踪每个函数的调用链、耗时和错误率,问题定位时间从小时级缩短至分钟级,这种“可观测性”的提升,解决了Serverless早期“黑盒化”的痛点,进一步推动了其生态聚类。
Serverless与AI、大数据等技术的融合也在加速,2026年,AWS推出的“Serverless for AI”方案,允许开发者直接在Lambda函数中调用SageMaker的机器学习模型,无需管理底层基础设施,某医疗企业利用这一方案,将影像诊断函数的开发周期从3个月缩短至2周,且成本降低70%,这种“技术融合”形成的交叉聚类,正在拓展Serverless的应用边界。
行业案例:Serverless在2026年的真实落地场景
案例1:零售行业的实时库存管理
2026年医疗器械与游戏产业及野生动物保护领域迎来新发展,相关应用不断深化 2026年,某连锁超市的线上平台面临库存同步延迟问题:传统架构中,订单系统与库存系统通过消息队列同步,但高峰期消息积压导致库存显示滞后,引发超卖,迁移至Serverless后,其架构调整为:每当用户下单,立即触发一个库存更新函数,该函数直接操作数据库,并在100毫秒内返回结果,实施后,超卖率从0.8%降至0.02%,且无需再为消息队列服务支付费用。

案例2:金融行业的反欺诈系统
某银行的风控部门在2026年面临挑战:传统反欺诈规则需人工维护,且无法应对新型诈骗手段,其采用Serverless架构后,将每条交易记录作为事件输入,触发多个风控函数(如设备指纹分析、行为模式匹配),并实时返回风险评分,这一方案不仅将规则更新周期从周级缩短至小时级,还通过函数组合实现了复杂逻辑的灵活编排,诈骗拦截率提升40%。
案例3:物联网设备的数据处理
某智能家居厂商在2026年拥有超过500万台设备,每天产生1.2PB数据,其传统架构需维护一套庞大的流处理集群,成本高昂,迁移至Serverless后,设备数据通过IoT Core直接触发函数处理(如异常检测、用户行为分析),处理后的结果存入数据库供前端调用,这一方案将数据处理成本从每月28万元降至9万元,且无需再为集群扩容操心。
挑战与未来:Serverless聚类的边界与延伸
尽管Serverless在2026年已形成显著的技术、成本和生态聚类,但其发展仍面临挑战,冷启动延迟在超低延迟场景(如高频交易)中仍需优化;长运行任务(如视频转码)的适配性有待提升;跨云厂商的函数调用标准尚未统一,限制了多云部署的灵活性。
这些挑战并未阻碍Serverless的聚类扩展,2026年,Gartner预测,到2028年,超过70%的新应用将采用Serverless架构,其应用场景将从当前的Web服务、事件处理,延伸至AI推理、边缘计算等领域,正如聚类算法中,数据点的聚集会不断吸引新的点加入,Serverless的技术优势、成本效益和生态完善,正在形成一种“自我强化”的聚类效应,推动其成为云计算的下一站。
压力缓解与燃料电池及在线教育热度持续上升,相关产业迎来新机遇 从资源分配到事件驱动,从固定成本到可变成本,从孤岛开发到全链路协同,Serverless的兴起是技术、成本、生态等多维度数据点自然聚集的结果,2026年的实践证明,这一聚类不仅真实存在,且正在重塑云计算的格局。