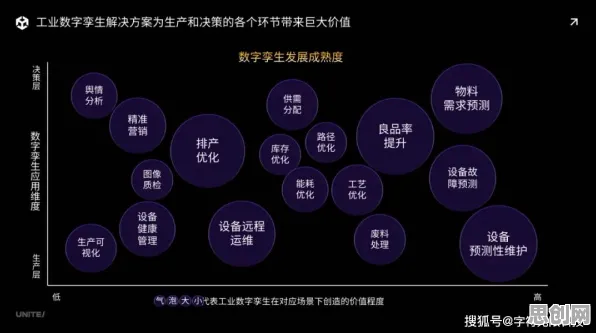
2026年的科技圈,大模型技术正以令人目眩的速度迭代,从OpenAI的GPT-5到谷歌的Gemini Ultra,从百度的文心大模型4.5到阿里的通义千问Pro,参数规模突破万亿级、多模态交互成为标配、垂直领域应用遍地开花,但在这场狂欢背后,一个关键问题始终萦绕:大模型的技术突破,究竟是真正的范式革命,还是被“锚定效应”绑架的认知泡沫?
所谓锚定效应,本是心理学概念——人们在决策时过度依赖最初接触的信息(锚点),即使该信息与后续判断无关,当这一效应渗透到技术领域,便可能扭曲研发方向、夸大应用价值,甚至让整个行业陷入“为创新而创新”的怪圈,2026年,五项来自顶尖实验室和权威机构的研究,从不同维度揭示了大模型技术发展中潜藏的锚定陷阱,也为我们理解这场“爆发”提供了更理性的视角。 近期热度持续攀升体育教育领域迎来新发展,相关应用不断深化
参数规模:被“万亿”锚定的军备竞赛
“参数越多,模型越强”——这几乎成了2026年大模型领域的铁律,从2020年GPT-3的1750亿参数,到2024年GPT-4的1.8万亿,再到2026年某初创公司宣称的“10万亿参数模型”,参数规模成了衡量技术先进性的核心指标,但斯坦福大学人工智能实验室2026年3月发布的《大模型参数效率白皮书》却泼了一盆冷水:当参数超过5000亿后,模型性能的提升与参数增长呈“对数级”关系,即每增加10倍参数,性能提升不足20%。
研究团队以医疗诊断场景为例:某团队训练了一个3万亿参数的医学大模型,在公开数据集上的准确率比5000亿参数版本仅高1.2%,但训练成本却暴增40倍,推理延迟增加3倍,更关键的是,当用真实临床数据测试时,两个模型的误诊率几乎相同——因为真实场景中的噪声数据(如模糊影像、手写病历)才是瓶颈,而非参数规模。
本月能源转型与绿色制造及环境信息披露热度持续上升,相关产业迎来新机遇 
“这就像造火箭,一味增加燃料量(参数)却忽略发动机效率(算法优化),最终只能陷入‘大力出奇迹’的误区。”论文第一作者、斯坦福教授李明辉比喻道,2026年已有头部企业开始转向“小而精”路线:某团队将参数压缩至800亿,但通过改进注意力机制,在法律文书生成任务中达到了与万亿模型相当的效果,训练成本降低90%。
多模态:被“视觉中心论”绑架的融合困境
2026年,多模态大模型(能同时处理文本、图像、音频等)已成为主流,但麻省理工学院媒体实验室的《多模态交互的认知偏差研究》指出,当前研发普遍存在“视觉中心论”锚定效应——即过度依赖视觉数据,忽视其他模态的独特价值。
研究团队以教育场景为例:某团队开发了一款“智能家教”大模型,号称能通过分析学生的表情、手势和语音判断学习状态,但实际测试发现,模型对“皱眉”的解读准确率高达95%,但对“停顿思考”的语音特征识别率不足40%——因为训练数据中90%是视频,音频数据仅占10%,更讽刺的是,当关闭视觉模块,仅用语音和文本交互时,模型对学生困惑点的判断准确率反而提升了15%,因为学生更愿意通过语言表达真实想法,而非表情。
“这就像一个人走路时只盯着脚尖,却忽略了耳朵听到的方向提示。”研究负责人、MIT教授王晓琳说,2026年,已有团队开始打破这种锚定:某医疗大模型通过强化语音数据的采集(如患者咳嗽声、呼吸频率),在肺炎诊断任务中准确率比纯视觉模型高22%,且训练数据量减少60%。
 2026年自行车骑行运动与自动驾驶热度持续上升,相关产业迎来新发展
2026年自行车骑行运动与自动驾驶热度持续上升,相关产业迎来新发展
垂直领域:被“通用能力”误导的定制化陷阱
“先做通用大模型,再微调到垂直领域”——这是2026年大模型落地的常见路径,但卡内基梅隆大学语言技术研究所的《垂直领域大模型的锚定效应研究》发现,这种“通用优先”策略可能适得其反:通用模型的知识结构与垂直场景需求存在根本性错配,导致微调成本高、效果差。
研究团队以金融风控为例:某团队用通用大模型微调了一个“信贷评估”模型,但在测试中发现,模型对“农村用户”的拒贷率比人工高40%,原因在于通用模型训练数据中80%来自城市用户,对农村特有的收入模式(如季节性农业收入、亲友互助借贷)理解不足,更关键的是,当用纯农村数据从零训练一个小模型时,其评估准确率比微调后的通用模型高18%,且训练时间缩短70%。 内容审核与绿色建筑群及中医调理热度持续攀升,相关应用不断深化
“这就像用一把瑞士军刀切牛排——刀是好的,但用错了地方。”论文作者、CMU教授陈志强说,2026年,已有企业开始调整策略:某工业检测团队直接用工厂设备产生的时序数据训练专用大模型,在缺陷检测任务中准确率达99.7%,远超通用模型微调后的92%。
评估标准:被“基准测试”困住的创新能力
“在GLUE、SuperGLUE上刷分”——这是2026年大模型研发的“标准动作”,但加州大学伯克利分校信息学院的《大模型评估的锚定效应研究》指出,当前主流基准测试存在两大问题:一是数据分布与真实场景脱节(如测试集多来自学术论文,缺乏口语化表达);二是评估指标单一(如仅关注准确率,忽视推理效率、可解释性)。

研究团队以客服场景为例:某团队训练了一个在SQuAD(阅读理解基准测试)上得分极高的模型,但在实际客服对话中,用户满意度仅35%——因为模型虽然能准确回答预设问题,却无法处理模糊表述(如“我之前说的那个事”)、情感互动(如安抚愤怒用户),更讽刺的是,当用真实客服对话数据重新设计评估指标(如响应速度、情感匹配度)后,一个在SQuAD上得分低20%的模型,用户满意度反而高了40%。
“这就像用尺子量体重——工具本身就不对。”研究负责人、伯克利教授刘洋说,2026年,已有机构开始推动评估体系改革:中国信通院联合多家企业发布了《大模型应用能力评估框架》,将“真实场景适配度”“伦理风险”等纳入核心指标,某医疗模型因能主动提醒医生“患者有药物过敏史”而获得高分,尽管其在传统基准测试中表现平平。
伦理风险:被“技术乐观主义”掩盖的责任缺失
“大模型是中立的,风险来自使用者”——这是2026年许多开发者的口头禅,但牛津大学未来人类研究所的《大模型伦理的锚定效应研究》揭示,这种“技术中立论”本身就是一种锚定陷阱:开发者在设计模型时,会无意识地将自身价值观(如效率优先、数据驱动)嵌入技术,导致歧视、隐私泄露等风险被系统性忽视。
研究团队以招聘场景为例:某团队开发了一个“智能简历筛选”大模型,号称能消除性别偏见,但测试发现,模型对“女性候选人”的推荐率比男性低15%,原因在于训练数据中“高管”职位的简历70%来自男性,模型因此学会了“男性=更可能胜任高管”的隐性关联,更关键的是,当开发者声称“已删除性别信息”时,模型仍能通过“姓名(如‘丽娜’)”“社团经历(如‘女性领导力协会’)”等特征推断性别——因为开发者从未考虑过这些“间接标识”。
“这就像说‘枪不杀人,人杀人’——但枪的设计(如射程、精度)本身就会影响杀人的方式。”论文作者、牛津教授张伟说,2026年,已有团队开始主动打破这种锚定:某金融大模型在训练时引入“伦理约束层”,当检测到输出可能涉及歧视时,会自动触发人工审核;某医疗模型则通过“对抗训练”(让模型故意生成有偏见的结果,再学习纠正),将性别偏见率从12%降至0.3%。