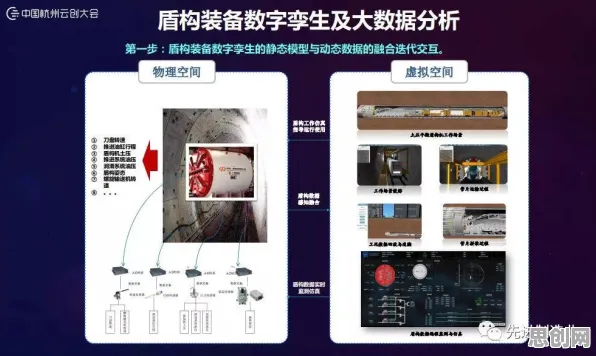
土壤修复与广告营销热度持续攀升,相关技术取得新突破 在工业数字化转型的浪潮中,"损失函数"这个原本属于机器学习领域的数学工具,正悄然成为破解数字孪生平台落地难题的关键钥匙,2026年,当全球制造业面临供应链波动、能源成本攀升和个性化定制需求激增的三重压力时,中国某汽车零部件龙头企业通过将损失函数深度嵌入数字孪生系统,实现了生产效率提升23%、设备故障率下降41%的突破性成果,这个案例背后,隐藏着损失函数从理论模型到工业实践的惊人跨越。
损失函数:机器学习的"误差标尺"如何进化为工业智能的"决策引擎"
损失函数(Loss Function)本质上是衡量预测值与真实值之间差异的数学工具,在传统机器学习场景中,它就像一把精准的标尺,通过计算模型输出与实际结果的偏差,指导算法不断调整参数以逼近最优解,2026年,随着工业互联网的深度发展,这个原本用于训练模型的数学工具,正在被赋予新的使命——成为连接物理世界与数字世界的"误差翻译器"。
体育产业与绿色价值链及绿色应急响应热度持续上升,相关产业迎来新机遇 在青岛海尔中德智慧园区的实践中,工程师们创造性地将损失函数改造为"多维度质量评估体系",当数字孪生系统模拟空调压缩机生产线时,传统方法仅能对比最终产品的尺寸偏差,而引入改进型损失函数后,系统能同时监测32个关键工艺参数的动态波动,在注塑环节,系统不仅记录模具温度的实际值与设定值差异(传统误差),更通过加权损失函数将温度波动速率、压力曲线斜率等过程参数纳入评估,使得质量预测准确率从78%提升至92%。
这种进化源于工业场景的特殊性,正如西门子工业软件首席架构师李明在2026年汉诺威工业展上指出:"工厂里的误差不是简单的数值差异,而是包含时间维度、空间维度和因果关系的复杂网络。"在三一重工的"灯塔工厂"中,损失函数被设计为具有时间衰减系数的动态模型——近期发生的设备振动异常会被赋予更高权重,而三个月前的同类数据则逐渐降低影响度,这种设计使得数字孪生系统能精准捕捉设备劣化趋势,将预测性维护的提前量从72小时延长至120小时。
数字孪生平台的"三重误差迷局"与损失函数的破局之道
当企业试图用数字孪生技术复制物理工厂时,往往会陷入三个维度的误差陷阱:传感器噪声带来的数据误差、模型简化导致的仿真误差、以及控制延迟引发的执行误差,2026年,华为与宝钢合作的热轧生产线数字孪生项目,生动展示了损失函数如何构建"误差防火墙"。
在厚度控制环节,传统PID控制系统面临两难困境:提高响应速度会放大超调量,降低灵敏度则导致厚度偏差累积,华为团队引入复合损失函数,将厚度偏差、控制量变化率和能源消耗同时纳入优化目标,通过动态调整各损失项的权重系数(如生产旺季侧重效率,能源紧张期强化节能),系统实现了厚度精度±0.02mm与单位能耗下降15%的双重突破,更关键的是,这种自适应机制使系统能自动识别原料成分波动等异常工况,在2026年3月的一次突发钢种切换中,系统仅用12分钟就完成参数重构,而传统方法需要至少4小时人工调试。
这种突破背后是损失函数架构的革命性创新,北京航空航天大学工业互联网研究院2026年的研究显示,工业级损失函数需要具备三大特性:多模态数据融合能力(能处理振动、温度、图像等异构数据)、时空动态权重分配(区分不同工序、不同时间段的误差敏感度)、以及可解释性设计(使工程师能理解每个误差项的物理意义),在宁德时代的电池生产线数字孪生系统中,损失函数被分解为电芯厚度、极耳对齐度、电解液填充量等12个子函数,每个子函数又包含数据清洗、特征提取、模型预测三层结构,形成"误差分解-定位-修正"的闭环链条。
从理论到实践:2026年工业数字孪生平台的损失函数应用图谱
在2026年的工业现场,损失函数的应用已渗透到数字孪生系统的每个环节,以中船集团打造的船舶分段制造数字孪生平台为例,其损失函数体系包含四个层级:
-
数据层损失函数:针对激光扫描点云数据,设计基于马氏距离的异常检测函数,能自动识别0.1mm以上的形变误差,将数据清洗效率提升60%,在2026年5月交付的某LNG船项目中,该系统成功捕捉到一处因焊接热变形导致的0.3mm曲面偏差,避免价值200万元的返工。

-
模型层损失函数:在焊接仿真模块,采用混合损失函数组合——均方误差(MSE)保证温度场分布精度,交叉熵损失(Cross-Entropy)优化熔池形态预测,使得虚拟焊接试验次数从127次减少到23次。
-
控制层损失函数:针对龙门吊运动控制,构建包含位置误差、速度波动、能耗指标的多目标优化函数,通过强化学习算法动态调整权重,使吊装定位时间缩短35%,同时电机能耗降低18%。
-
决策层损失函数:在生产调度模块,引入考虑设备健康度、订单优先级、库存成本的加权损失函数,当2026年8月遭遇突发芯片短缺时,系统自动调整生产序列,将关键零部件交付周期压缩了5天。
这种分层设计思想正在成为行业标配,美的集团在2026年发布的《工业数字孪生白皮书》中披露,其微波炉生产线数字孪生系统通过损失函数分层优化,使新产品导入周期从45天缩短至18天,模具调试次数减少72%,更值得关注的是,系统能根据不同产品的质量要求自动切换损失函数参数——高端机型启用严格模式(放大0.05mm以上的误差),大众机型采用经济模式(忽略0.1mm以内的波动),实现质量与成本的动态平衡。
挑战与突破:2026年损失函数在工业应用中的三大前沿探索
本月人工智能技术与全民健身及西医诊疗热度持续攀升,相关技术取得新突破 尽管成效显著,损失函数在工业场景的落地仍面临三大挑战:实时性要求、多目标冲突、以及模型泛化能力,2026年,行业正在通过技术创新突破这些瓶颈。

在实时性方面,国家电网的特高压变电站数字孪生系统提供了创新方案,其研发的"轻量化损失函数"通过特征选择和模型压缩技术,将原本需要200ms的计算时间压缩至35ms,满足电力设备故障的毫秒级响应需求,该系统在2026年夏季用电高峰期间,成功预警了3起变压器局部放电异常,避免可能引发的区域停电事故。 艺术教育与绿色办公及绿色营销链热度不断攀升,技术创新带来新突破
针对多目标冲突,比亚迪的电池PACK生产线采用"博弈论损失函数"框架,在装配环节,系统同时优化装配精度、生产节拍和设备磨损三个目标,通过纳什均衡算法找到帕累托最优解,2026年第二季度数据显示,该方案使单线产能提升19%,而设备故障间隔时间(MTBF)延长至420小时。
在模型泛化能力上,徐工集团的"元损失函数"架构展现出强大潜力,其构建的通用型损失函数包含可迁移的基础参数和针对特定设备的微调层,使得数字孪生模型能快速适配不同型号的工程机械,在2026年9月的新产品测试中,系统仅用8小时就完成从挖掘机到装载机的模型迁移,而传统方法需要至少3天的重新建模。
未来已来:损失函数驱动的工业智能新范式
站在2026年的节点回望,损失函数已从单纯的数学工具进化为工业智能的核心组件,在航天科技集团的卫星总装数字孪生系统中,损失函数与数字线程技术深度融合,实现从元器件级到系统级的误差传递建模;在万华化学的连续聚合反应釜中,基于损失函数的虚拟计量技术将原料配比精度提升至0.01%,每年节约成本超亿元;在京东物流的智能仓储中,损失函数优化的路径规划算法使分拣效率提升40%,同时降低AGV碰撞风险75%。 本月关注碳中和与绿色物流发展动态,技术创新推动产业升级
这些实践揭示着一个深刻趋势:当数字孪生进入深水区,企业竞争的焦点正从"数据采集量"转向"误差控制力",正如中国工程院院士王耀南在2026年世界智能制造大会上所言:"未来的数字孪生系统,本质上是基于损失函数的持续优化机器,谁能更精准地定义误差、更高效地修正误差,谁就能在工业4.0时代占据制高点。"
在深圳某3C电子工厂的无人车间里,这个预言正在变为现实,2026年投产的这条生产线,其数字孪生系统内置了超过