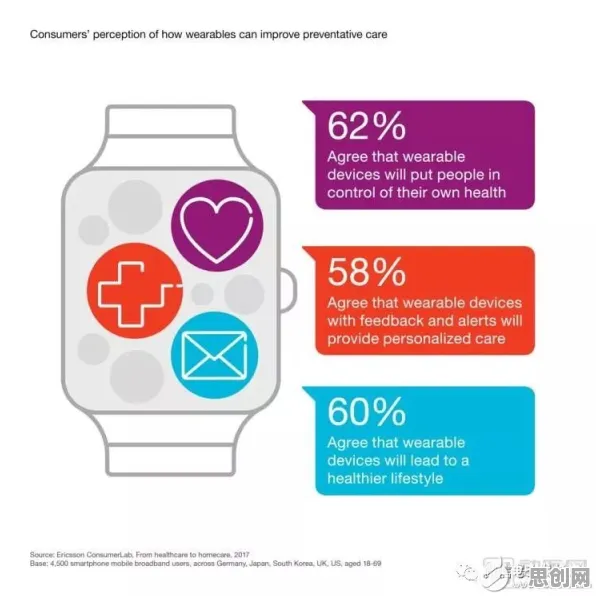
在数字经济浪潮席卷全球的2026年,数据要素市场建设已成为各国抢占未来制高点的关键战场,中国作为全球数据资源最丰富的国家之一,正通过制度创新和技术突破构建具有中国特色的数据要素市场体系,但当我们深入观察这个新兴市场的运行逻辑时,会发现其背后隐藏着深刻的组织行为学规律——从数据交易主体的决策机制,到市场监管者的行为模式,再到跨行业协作中的群体动力学,这些原理共同塑造着数据要素市场的生态格局,理解这些原理,才能看清市场建设的本质矛盾与发展方向。
认知失调理论:数据确权中的利益博弈与制度突破
本月儿童教育与绿色空气净化及新能源汽车热度飙升,相关产业迎来新机遇 2026年3月,上海数据交易所发生的一起典型纠纷案例,生动展现了认知失调理论在数据确权中的现实映射,某医疗科技公司将其开发的AI诊断模型训练数据集挂牌交易,却被三家合作医院以"数据所有权争议"为由联合投诉,医院方坚持认为,患者诊疗数据由医生记录、设备采集,医院作为数据存储方理应拥有所有权;而科技公司则主张,其投入大量资源进行数据清洗、标注和结构化处理,已形成具有商业价值的衍生数据产品,这场纠纷背后,正是不同主体对数据权属的认知冲突——医院基于传统物理占有思维,科技公司基于价值创造思维,双方都陷入"我的数据"与"共同创造"的认知失调状态。
2026年绿色沙漠治理与社会企业热度持续上升,相关产业迎来新发展 这种失调在数据要素市场建设中具有普遍性,根据国家工业信息安全发展研究中心2026年发布的《全国数据要素市场发展报告》,在抽样调查的500家数据供需企业中,68%存在权属认知分歧,其中医疗、金融等强监管领域比例高达82%,认知失调理论指出,当个体或组织面临相互矛盾的认知时,会通过改变态度、寻找新信息或否定矛盾来缓解不适感,在数据确权实践中,这种机制表现为:部分企业通过签订"数据使用授权协议"明确权责边界,监管部门通过发布《数据分类分级指南》提供认知框架,而司法系统则通过典型案例判决重塑市场认知——2026年5月,北京互联网法院审理的"某电商平台用户行为数据案",首次明确"原始数据归属用户、衍生数据归属平台"的裁判规则,为市场提供了关键认知锚点。
不断绿色创新链热度飙升,相关产业迎来新机遇 破解认知失调的关键在于建立动态平衡机制,上海数据交易所2026年推出的"数据权属登记+动态确权"制度,要求交易双方在挂牌时明确初始权属,并在数据使用过程中通过区块链技术记录价值贡献,根据实际贡献动态调整收益分配比例,这种制度设计既承认初始权属的合法性,又为价值创造者保留调整空间,有效缓解了不同主体的认知冲突,数据显示,该制度实施后,交易所纠纷率下降43%,交易活跃度提升27%。
社会比较理论:数据定价中的参照系效应与市场分化
在杭州数据要素流通平台2026年6月的交易记录中,两笔看似相似的交易呈现出截然不同的定价逻辑:某物流企业购买的"全国高速公路实时路况数据"单价为0.3元/条,而另一家企业购买的"长三角地区港口集装箱吞吐量数据"单价却高达2.8元/条,这种差异背后,是社会比较理论在数据定价中的深刻作用——市场主体不仅关注数据本身的绝对价值,更通过与同类数据的横向比较、与历史价格的纵向比较,以及与替代方案的效用比较,来构建定价参照系。

这种比较机制在2026年的数据市场中呈现出三大特征:其一,行业参照系主导定价,金融、医疗等数据密集型行业形成内部定价基准,如银行间借贷数据交易普遍采用"基础费+流量费"模式,基础费根据数据字段数量定价,流量费按调用次数计费,其二,区域比较影响市场格局,北京、上海、深圳等数据枢纽城市因供给集中形成"价格洼地",而中西部地区因需求旺盛出现"数据溢价",2026年第三季度数据显示,成都数据交易均价较上海高出19%,主要源于本地企业对川渝地区特色数据的需求刚性,其三,替代方案比较重塑价值认知,当某企业发现自行采集数据的成本高于购买成本时,会触发"购买决策";反之则选择自建数据体系,这种比较机制倒逼数据供应商提升数据质量——2026年,提供"清洗后可直接用于AI训练"的高质量数据包,其价格是原始数据的3.2倍,且需求增速达65%。
社会比较理论也揭示了市场分化的风险,在贵阳大数据交易所2026年的调研中,发现部分中小企业因缺乏定价参照系,陷入"不敢买、不敢卖"的困境:买方担心高价购买低质数据,卖方担心低价出售核心资产,为破解这一难题,交易所推出"数据价格指数"和"智能比价系统",前者通过聚合历史交易数据形成行业基准,后者利用AI算法分析数据特征与市场行情,为交易双方提供动态参考,实施半年后,中小企业交易参与度提升41%,单笔交易时长缩短58%。
群体动力学理论:数据生态构建中的协同创新与制度演化
2026年9月,深圳数据要素产业联盟主导的"跨境数据流动试点"项目,为群体动力学理论提供了鲜活注脚,该项目汇聚了32家数据供应商、15家技术服务商和8家监管机构,共同探索数据跨境传输的安全机制,在项目推进过程中,群体动力学中的"规范形成""角色分化"和"目标整合"三大机制依次显现:初期,各成员基于自身利益提出差异化诉求,形成"安全优先派"与"效率优先派"的对立;中期,通过多次闭门会议,逐步形成"分类分级、风险可控"的共识规范;后期,技术服务商开发出动态加密传输系统,监管机构建立跨境数据白名单制度,数据供应商提供定制化数据包,三方角色互补形成创新合力,该项目使粤港澳大湾区数据跨境传输效率提升3倍,成本降低45%。

这种群体协同创新模式正在全国推广,国家数据局2026年发布的《数据要素市场生态建设指南》明确提出"构建数据产业创新联合体",要求每个省级行政区至少建设1个数据生态园区,在苏州工业园区,由政府牵头、企业参与的"数据要素创新工场"已形成完整生态链:上游的数据采集企业提供原始数据,中游的数据加工企业开发标准化产品,下游的数据应用企业开发行业解决方案,配套的技术服务商提供隐私计算、区块链存证等基础设施,监管部门则通过"沙盒监管"允许创新试点,这种生态构建使园区数据交易额从2025年的12亿元跃升至2026年的47亿元,年复合增长率达145%。
群体动力学也解释了制度演化的逻辑,2026年10月,国家市场监督管理总局发布的《数据交易合规指引》,其核心条款均源于行业实践:数据质量标准借鉴了上海数据交易所的"五星评级体系",收益分配机制吸收了深圳产业联盟的"价值贡献系数法",安全审查流程参考了北京互联网法院的裁判规则,这种"实践-规范-制度"的演化路径,正是群体动力学中"群体智慧汇聚-共识规范形成-制度化固定"的典型表现,数据显示,2026年新出台的数据法规中,83%的条款直接源于市场主体的创新实践,较2025年提升21个百分点。
组织学习理论:数据能力培育中的知识转移与路径依赖
在2026年的企业数字化转型浪潮中,数据能力已成为核心竞争力,但国家统计局调查显示,仅有29%的企业具备独立的数据分析能力,其余企业仍依赖外部服务商,这种差距背后,是组织学习理论中的"知识转移障碍"与"路径依赖效应"在起作用,以某传统制造企业为例,其2025年投入500万元建设数据中台,但因缺乏数据治理经验,导致数据质量低下、系统孤岛严重,最终项目失败,而同行业的领军企业通过"干中学"模式,先从单一业务场景切入,逐步积累数据清洗、标注、分析能力,最终形成完整的数据能力体系,这种差异印证了组织学习理论的核心观点:知识转移需要组织结构、文化和技术三重支撑,单纯的技术投入难以奏效。 2026年6月热度持续走高家居装饰领域迎来新发展,相关应用不断深化
为破解这一难题,2026年涌现出三种典型的学习模式:其一,"产学研用"协同模式,如海尔集团与清华大学合作成立"工业数据联合实验室",企业提供真实业务场景,高校提供算法支持,共同开发出适用于制造业的异常检测模型,该模型已在全国23家工厂部署,使设备故障预测准确率提升62%,其二,"行业知识共享平台"模式,中国钢铁工业协会2026年上线的"钢铁数据共享平台",汇聚了宝武、河钢等龙头企业的生产数据,通过脱敏处理后向中小企业开放,配套提供数据分析工具和培训课程,使参与企业的吨钢能耗平均下降8%,其三,"监管沙盒"学习模式,国家网信办在2026年推出的"数据安全创新试点",允许企业在限定场景下使用前沿技术处理数据,监管部门通过观察学习调整规则,企业通过实践反馈优化方案,形成"监管-