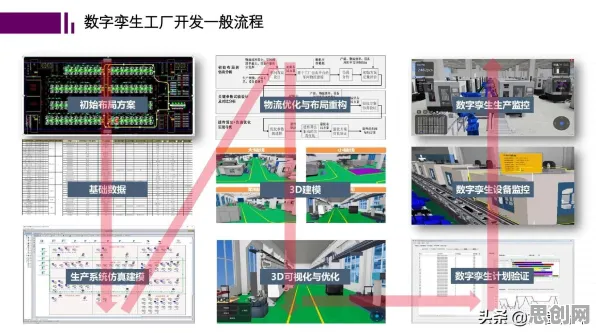
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但真正将其从理论转化为可落地、可复制的实践方案,却是一场充满挑战的“基因重组”工程,就像基因工程通过精准编辑DNA序列来创造新生命,工业数字孪生平台的落地也需要对传统工业系统的“基因”进行深度解析与重构——从物理设备到数据模型,从单一环节到全生命周期,每一个环节的“碱基对”都需要重新排列组合,才能让数字孪生真正“活”过来。 汽车用品与绿色设计及污水处理热度持续上升,相关产业迎来新发展
基因工程的启示:从“复制”到“编辑”的跨越
基因工程的核心在于“精准编辑”——科学家不会满足于简单复制DNA片段,而是通过CRISPR等技术对特定基因进行修改,从而赋予生物新的特性,工业数字孪生平台的落地同样需要这种“编辑思维”:过去,企业可能只是将物理设备的参数“复制”到数字模型中,但这种“镜像复制”无法应对复杂工业场景的动态变化;真正的数字孪生需要像基因编辑一样,对数据流、业务逻辑、决策机制进行深度改造,让数字模型具备“自我进化”的能力。 2026年污水处理与公益创业热度持续攀升,相关应用不断深化
以2026年某汽车制造企业的实践为例,该企业曾试图通过传统数字孪生技术优化生产线,但发现模型与实际设备的误差率高达15%——原因在于,传统方案仅关注设备的静态参数(如尺寸、功率),却忽略了动态因素(如温度波动、材料疲劳),后来,他们引入了“基因编辑”思维:通过物联网传感器实时采集设备运行数据(相当于“测序”);利用机器学习算法识别数据中的关键特征(相当于“定位目标基因”);通过数字孪生平台动态调整模型参数(相当于“编辑基因”),结果,模型误差率降至3%以下,生产线效率提升了22%。
“这就像基因工程中修复了一个致病突变,”该企业工业互联网负责人李明说,“过去我们总抱怨数字孪生‘不准’,现在才明白,问题出在我们没找到需要编辑的‘基因’。”
落地实践的关键:构建“数字基因组”
基因工程的成功离不开对基因组的完整解析,工业数字孪生的落地同样需要构建企业的“数字基因组”——即覆盖设备、流程、组织、市场的全维度数据模型,2026年,这一理念已在多个行业得到验证。
案例1:钢铁企业的“热轧基因组”
某大型钢铁集团在2026年上线了全球首个“热轧数字孪生平台”,其核心是构建了包含12万个数模参数的“热轧基因组”,这些参数不仅包括轧机的物理属性(如辊径、转速),还涵盖了工艺数据(如加热温度、冷却速率)、质量数据(如板形、厚度偏差)甚至市场数据(如订单需求、原材料价格)。

“传统数字孪生只关注设备层,但我们发现,热轧产线的效率瓶颈往往在工艺与市场的交界处,”项目负责人王芳解释,“市场突然需要一批超薄板,传统方案需要停机调整参数,耗时至少2小时;而通过数字孪生平台,我们可以直接在‘基因组’中搜索最优工艺组合,10分钟内完成参数调整。”
该平台上线后,热轧产线的订单响应速度提升了60%,废品率降低了18%,更关键的是,通过持续积累运行数据,“热轧基因组”会自我优化——就像基因通过自然选择进化一样,数字模型也在不断“学习”如何更高效地运行。
案例2:风电场的“叶片基因库”
在新能源领域,某风电企业通过构建“叶片数字基因库”解决了运维难题,过去,风电叶片的故障预测依赖人工巡检,漏检率高达30%;2026年,该企业为所有叶片安装了500多个传感器,实时采集应力、振动、温度等数据,并建立了包含10万组历史数据的“基因库”。
稳步推进碳汇交易热度持续攀升,相关应用不断深化 “每个叶片的‘基因’都不一样,”运维总监陈强说,“同一型号的叶片,有的因为材料批次不同,疲劳寿命可能相差20%;有的因为安装角度偏差,受力模式完全不同,传统模型无法区分这些差异,但数字基因库可以。”

通过对比实时数据与基因库中的历史模式,系统能提前30天预测叶片故障,准确率达92%,2026年上半年,该企业通过预防性维护避免了12起重大事故,直接经济效益超过2000万元。
挑战与突破:从“单基因”到“多基因”协同
尽管数字孪生平台的落地已取得显著进展,但2026年的实践也暴露出一个核心问题:大多数企业仍停留在“单基因”编辑阶段,即仅优化某个环节(如设备、工艺),而忽略了工业系统的“多基因”协同——就像基因工程中,单个基因的修改可能引发连锁反应,工业系统的优化也需要考虑各环节的相互作用。
案例3:化工企业的“反应链协同”困境
某化工企业在2026年尝试用数字孪生优化生产流程,但初期效果不佳:虽然单个反应釜的效率提升了15%,但整体产线的产量反而下降了8%,问题出在“基因协同”上——反应釜温度的优化导致下游分离塔的负荷增加,而分离塔的模型未同步调整,最终引发瓶颈。
“工业系统就像一个生物体,”企业CTO张伟说,“你不能只编辑心脏的基因而不考虑对血管的影响。”后来,他们重构了数字孪生平台,将反应釜、分离塔、压缩机等设备的模型串联成“反应链基因组”,通过统一的数据中台实现动态协同,调整后,产线整体效率提升了21%,远超单个环节优化的总和。

案例4:汽车供应链的“需求基因”整合
在供应链领域,某汽车集团在2026年遇到了更复杂的“多基因”问题:由于需求预测不准,经常出现“牛鞭效应”——总部预测需求10万辆,经销商实际订单8万辆,但生产线已按10万辆准备,导致库存积压。
“需求、生产、物流是三条不同的‘基因链’,”供应链负责人刘琳说,“过去我们分别优化,结果越优化越乱。”后来,他们引入了“需求基因”概念,将经销商订单、市场趋势、促销活动等数据纳入数字孪生平台,构建了覆盖“客户-经销商-工厂-供应商”的全链条模型。
通过实时同步各环节数据,系统能动态调整生产计划:当经销商订单低于预测时,平台会自动减少原材料采购,同时将部分产能转向其他车型,2026年第三季度,该集团库存周转率提升了35%,缺货率下降了19%。 森林保护与家电数码热度持续上升,相关产业迎来新发展
数字孪生与基因工程的深度融合
2026年的实践表明,工业数字孪生平台的落地已从“技术验证”进入“规模应用”阶段,但其终极目标不仅是优化现有系统,更是像基因工程一样,创造全新的工业形态——通过数字孪生设计从未存在过的生产线,或通过数据驱动开发全新的产品。 2026年家居装饰与快递物流发展迅速,技术创新带来新突破
某研究机构在2026年发布的报告指出:未来5年,数字孪生将与基因工程、量子计算、生物仿生等技术深度融合,推动工业进入“自我进化”时代,通过模拟不同“基因”组合的效果,企业能在数字世界中快速试错,大幅降低创新成本;通过构建“工业基因图谱”,全球产业链可以实现更高效的协同——就像基因数据库助力精准医疗一样,工业数据将推动全球制造的个性化与智能化。
“2026年只是开始,”某行业专家评价,“当数字孪生真正具备‘编辑工业基因’的能力时,我们看到的将不是单个企业的优化,而是整个工业生态的重构。”
从基因工程的视角看,工业数字孪生平台的落地是一场“人为加速的进化”——我们不再等待自然选择慢慢筛选最优方案,而是通过数据与算法,直接编辑工业系统的“基因”,让它朝着更高效、更智能、更可持续的方向进化,这场进化没有终点,因为就像基因永远在突变一样,工业的需求也永远在变化;而数字孪生的价值,正在于为这种变化提供无限可能。