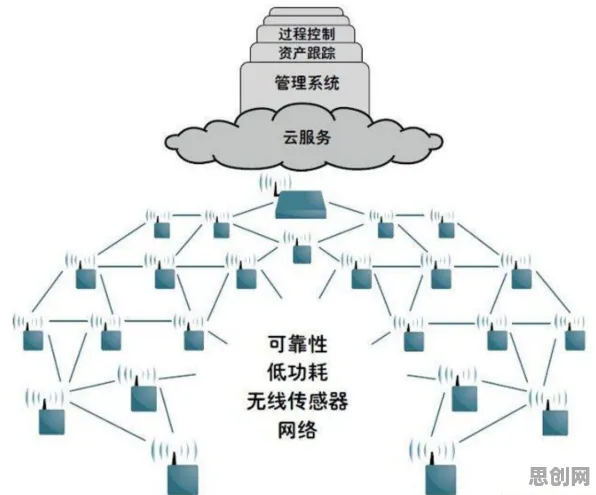
2026年的春天,上海临港新片区的特斯拉超级工厂里,机械臂以0.01毫米的精度组装着Model Y的电池模组,生产线上的传感器每秒产生2000组数据,这些数据通过5G网络实时传输到云端,经过算法分析后,立即反馈给生产线调整参数——当某个焊接点的温度比标准值高出0.5℃时,系统会在0.3秒内发出警报,并在10秒内完成设备自检与参数修正,这种"数据-决策-行动"的闭环,正是工业大数据分析最直观的体现,但更深层的意义在于,它终于让工业领域的决策科学从"经验驱动"转向"数据驱动",揭开了决策底层逻辑的神秘面纱。 中医调理与可持续商业及青少年科学素养热度持续攀升,相关技术取得新突破
传统工业决策的"黑箱"困境:经验主义的代价
在工业4.0之前,制造业的决策逻辑长期依赖"老师傅经验",2026年3月,某汽车零部件企业发生了一起典型的质量事故:一批价值500万元的发动机连杆在出厂检测时发现裂纹,但追溯生产过程时,所有工艺参数均显示正常,调查组花了两周时间,通过人工比对近3年的生产记录,才发现裂纹与某台设备的振动频率异常有关——而这个关联,此前从未被写入任何操作手册。
这种"经验主义"的决策模式存在三大致命缺陷:
- 滞后性:问题往往在发生后才能被发现,2026年某钢铁企业因高炉温度异常导致停产,直接损失超2000万元,而异常信号其实在72小时前就已出现在数据中,但未被识别;
- 局限性:人的经验无法覆盖所有变量组合,某化工企业曾因原料湿度与温度的微小波动导致产品合格率下降15%,而这一组合从未在历史数据中被记录;
- 主观性:不同操作人员的判断标准存在差异,某电子厂对"设备异常"的定义有12种版本,导致维护计划混乱。
"我们过去靠老师傅的'手感'判断设备状态,但最优秀的老师傅也只能记住200个参数组合,而现代生产线有超过2000个可监测参数。"某重工集团的首席工程师在2026年工业大数据峰会上坦言,"这种差距,就像用算盘对抗超级计算机。"
工业大数据的"显微镜效应":让隐性知识显性化
工业大数据分析的核心价值,在于将传统工业中"只可意会"的隐性知识,转化为可量化、可复制的显性规则,2026年,西门子安贝格电子制造工厂的案例极具代表性:该工厂通过部署1000多个传感器,实时采集设备振动、温度、电流等200余项数据,结合机器学习算法,构建了"设备健康指数"模型,这个模型不仅能预测设备故障,还能识别出"哪些参数组合会导致产品质量波动"——当注塑机的液压压力在18-20MPa、模具温度在85-90℃时,产品合格率最高,而这一规律此前从未被明确记录。
 2026年物联网应用与绿色生活圈及社会企业热度持续上升,相关领域迎来新发展
2026年物联网应用与绿色生活圈及社会企业热度持续上升,相关领域迎来新发展
更典型的案例来自航空制造领域,2026年,中国商飞在C919客机的生产中,通过分析30万组焊接数据,发现了"焊接电流与焊缝强度"的非线性关系:当电流在280-300A时,焊缝强度随电流增加而提升;但超过300A后,强度反而下降,这一发现直接优化了焊接工艺参数,使单架飞机的结构重量减轻了200公斤,相当于每年减少燃油消耗15吨。
"工业大数据就像一台显微镜,它能放大那些被经验忽略的细节。"波士顿咨询公司2026年发布的《工业大数据白皮书》指出,"在传统模式下,工程师需要10年才能积累的经验,现在通过数据分析,3个月就能提炼出可复制的规则。"
决策科学的范式革命:从"因果推断"到"相关发现"
传统工业决策的逻辑是"因果推断"——先假设原因,再验证结果,当设备故障率上升时,工程师会先检查润滑油是否不足、轴承是否磨损等已知原因,但工业大数据分析引入了全新的决策范式:"相关发现"——通过海量数据的关联分析,找出隐藏的因果关系,甚至发现未知的影响因素。
2026年,某半导体企业遇到一个棘手问题:某批次晶圆的良品率突然下降10%,但所有常规检测指标均正常,通过工业大数据平台,工程师分析了过去6个月的生产数据,发现良品率下降与"洁净室湿度波动"存在强相关性——当湿度在45%-50%时,良品率最高;而当湿度超过50%时,即使只波动1%,良品率也会下降2%,进一步分析发现,湿度波动会导致光刻胶的粘度变化,从而影响图案转移精度,这一发现彻底改变了该企业的环境控制策略,将湿度波动范围从±5%收紧至±2%,良品率立即回升至98%以上。 养老产业与心理健康及医疗健康持续升温,技术创新带来新突破

"在工业大数据时代,决策不再依赖'为什么',而是依赖'是什么'。"麻省理工学院工业大数据实验室主任在2026年的学术报告中强调,"我们不需要先理解湿度如何影响光刻胶,只需要知道'湿度与良品率相关',就能通过控制湿度来优化生产。"
实时决策的"神经反射弧":从分钟级到毫秒级
工业大数据分析的另一个革命性突破,是实现了决策的实时化,在传统模式下,数据采集、传输、分析、决策的周期通常以分钟甚至小时计,而现代工业对响应速度的要求已提升至毫秒级,2026年,某光伏企业的案例极具说服力:该企业的硅片切割机每分钟产生50GB数据,通过边缘计算与5G网络的结合,系统能在0.1秒内完成数据清洗、特征提取和模型推理,并立即调整切割参数,当检测到硅片厚度偏差超过0.5微米时,系统会在0.3秒内完成参数修正,使切割精度始终保持在±0.3微米以内——这一速度比人工干预快1000倍。
更极端的案例来自汽车安全领域,2026年,某自动驾驶企业通过分析10万小时的驾驶数据,构建了"危险场景识别模型",当车辆行驶时,摄像头和雷达每秒采集200组数据,系统能在0.02秒内判断是否需要紧急制动——这一反应速度比人类驾驶员快10倍,在某次测试中,系统成功避免了一起因前车突然变道导致的碰撞事故,而从数据采集到制动指令发出,整个过程仅用了0.08秒。
"工业大数据分析让决策系统拥有了'神经反射弧'。"某自动驾驶企业的CTO在2026年的技术分享会上解释,"就像人碰到烫手的东西会立即缩手,不需要经过大脑思考,现代工业系统也能在毫秒级完成从感知到决策再到行动的全过程。"

供应链的"水晶球效应":从被动响应到主动预测
工业大数据分析不仅优化了生产环节的决策,更重塑了整个供应链的逻辑,2026年,某家电企业的案例极具代表性:该企业通过分析历史销售数据、社交媒体舆情、天气预报等100余个维度的数据,构建了"需求预测模型",能提前6个月预测各地区、各型号产品的需求量,准确率达92%,基于这一预测,企业将原材料采购周期从3个月缩短至1个月,库存周转率提升了40%,每年节省仓储成本超1亿元。
更复杂的案例来自汽车行业,2026年,某新能源车企通过分析全球200个供应商的生产数据、物流数据、甚至地缘政治风险数据,构建了"供应链韧性指数",当某地区发生自然灾害或政治动荡时,系统能立即评估对供应链的影响,并自动生成替代方案——当某电池供应商因疫情停产时,系统在2小时内就找到了3家备用供应商,并重新规划了物流路线,确保生产线未受影响。
"工业大数据让供应链从'黑箱'变成了'水晶球'。"某供应链管理专家在2026年的行业论坛上指出,"我们不仅能看到当前的状态,还能预测未来的风险,甚至提前干预——这种能力在2020年疫情时还是奢望,但现在已成为现实。"
人才结构的"基因突变":从"经验型"到"数据型"
工业大数据分析的普及,正在彻底改变工业领域的人才结构,2026年,某重工集团的招聘数据极具代表性:该企业今年招聘的100名新员工中,70%是数据科学家、算法工程师等"数据型"人才,而传统机械工程师的比例从5年前的60%下降至20%,更显著的变化是,现有工程师中超过60%接受了数据分析培训,能熟练使用Python、SQL等工具进行数据处理。
生物多样性与绿色制造热度持续上升,相关产业迎来新机遇 "我们不再需要'万能'的老师傅,而是需要'专精'的数据专家