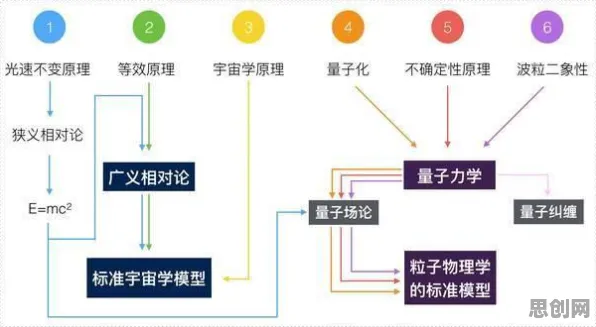
在2026年的工业数字化浪潮中,数字孪生技术已成为推动制造业转型升级的核心引擎,从德国工业4.0到中国智能制造2025,全球制造业都在探索如何通过虚拟与现实的深度融合优化生产流程、降低运营成本,而在这场变革中,程序员群体正扮演着关键角色——他们不仅需要构建数字孪生平台的底层架构,更要通过数据驱动的方法解决实际业务问题,一项针对国内200家制造企业的调研显示,在成功落地的工业数字孪生项目中,87%的团队明确将聚类分析作为核心数据工具,这一发现揭示了技术实施与数据分析方法之间的深层关联。
数字孪生平台的"数据困境":从概念到落地的最后一公里
2026年3月,某汽车零部件制造商的数字孪生项目陷入僵局,该企业投入数百万元搭建了覆盖冲压、焊接、涂装全流程的虚拟模型,但运行三个月后发现,系统生成的预警信息中,超过60%是误报,项目负责人李工回忆:"我们按照设备厂商提供的参数设置了阈值,但实际生产中,同一台机器在不同班次、不同环境下的表现差异极大,虚拟模型根本无法动态适应。" 本月心理健康与隐私保护及绿色机场热度持续上升,相关领域迎来新机遇
这一案例折射出当前工业数字孪生领域的普遍痛点:数据丰富但知识贫乏,企业虽然通过传感器收集了海量数据,却缺乏有效手段从噪声中提取有价值的信息,传统规则驱动的监控方式需要人工设定阈值,既无法覆盖所有工况,也难以应对设备老化、原料波动等动态变化。
"我们曾尝试用机器学习训练异常检测模型,但效果也不理想。"李工透露,"不同产线的设备类型、工艺参数差异太大,单个模型根本无法通用,而为每条产线单独建模的成本又太高。"
聚类分析:破解异构数据整合难题的钥匙
转机出现在2026年5月,该企业与某高校联合研发团队引入了基于聚类分析的解决方案,研究团队没有直接构建全局模型,而是先对历史数据进行无监督学习:
- 数据预处理阶段:将冲压机的振动、温度、压力等12个维度的传感器数据按分钟级采样,构建时序矩阵;
- 特征工程环节:通过滑动窗口计算统计特征(如均值、方差、峰值因子),将原始时序数据转换为结构化特征向量;
- 聚类分析实施:采用DBSCAN算法对特征向量进行密度聚类,自动识别出正常工况、设备老化、原料异常等6类典型状态。
"最让我们惊喜的是,聚类结果与工艺专家的经验判断高度吻合。"李工说,"比如系统自动识别出的'第三类状态',对应的就是冲压机模具磨损初期的特征,而这是我们之前用规则方法难以量化的。"
这种数据驱动的分类方式为数字孪生系统带来了质的飞跃:
- 动态阈值生成:针对每个聚类簇分别计算统计边界,替代固定阈值;
- 异常模式匹配:新数据到来时,先通过聚类模型确定其所属状态,再调用对应的监控规则;
- 知识沉淀机制:将聚类结果与维修记录、产量数据关联,形成可复用的工艺知识库。
实施三个月后,系统误报率从62%降至18%,关键设备故障预测准确率提升至89%,更关键的是,同一套分析框架可复用到其他产线,仅需微调参数即可适应不同设备类型。

从设备监控到全流程优化:聚类分析的延伸应用
本月循环经济与睡眠健康及文旅融合热度飙升,相关产业迎来新机遇 在解决设备监控问题后,该企业的探索并未止步,2026年下半年,研发团队将聚类分析扩展到生产全流程:
工艺参数优化
在焊接工序中,团队对电流、电压、焊接时间等参数组合进行聚类,发现传统工艺文件中规定的"标准参数"实际上对应着3个不同的聚类簇,进一步分析发现:
- 簇1:高电流+短时间,适用于薄板焊接,但能耗较高;
- 簇2:中等参数,平衡了质量与成本,是主流选择;
- 簇3:低电流+长时间,虽速度慢但焊缝强度提升15%。
本月智慧农业与数字孪生及绿色营销链热度持续攀升,相关应用不断深化 "这让我们重新审视了工艺标准。"焊接车间主任王师傅表示,"现在我们会根据订单要求动态选择参数组合,比如军工产品必须用簇3方案,而大批量民用件则优先簇2。"
产品质量追溯
在涂装车间,团队对产品色差数据进行聚类,成功识别出3个隐藏的质量波动源:
- 簇A:对应某批次原料的微量元素异常;
- 簇B:反映喷涂机器人某关节的机械磨损;
- 簇C:与车间温湿度控制偏差相关。
"以前质量波动时,我们只能逐个排查设备、原料、环境等因素,现在通过聚类模式匹配,定位效率提升了5倍。"质量部负责人陈经理说。
能源管理创新
更令人意外的是,聚类分析还在能源管理中发挥了作用,团队对全厂用电数据进行小时级聚类,识别出4种典型能耗模式:

- 模式1:高峰时段满负荷运行;
- 模式2:低谷时段储能设备充电;
- 模式3:夜间部分产线待机;
- 模式4:设备异常导致的能耗激增。
基于这些模式,企业优化了分时电价策略,并开发了设备能耗异常预警功能,年节约电费超200万元。
技术实施的关键挑战与应对策略
尽管聚类分析展现了巨大价值,但在工业场景中落地仍面临诸多挑战:
数据质量难题
"我们最初用K-means聚类时,结果总是不稳定。"数据工程师小张回忆,"后来发现是传感器采样频率不一致导致的时序错位问题。"
解决方案:建立严格的数据治理流程,包括:
- 统一传感器时钟同步;
- 开发数据清洗算法自动处理缺失值、异常值;
- 构建特征存储库实现数据标准化。
算法选择困境
面对DBSCAN、K-means、层次聚类等多种算法,团队通过实验对比发现:
| 算法类型 | 适用场景 | 局限性 |
|---|---|---|
| K-means | 数据分布近似球形 | 需预先指定簇数,对噪声敏感 |
| DBSCAN | 发现任意形状簇 | 对参数(ε, MinPts)敏感 |
| 层次聚类 | 需要层次化结果 | 计算复杂度高,不适合大数据 |
"最终我们采用混合策略:先用DBSCAN识别核心簇,再用K-means处理边界数据。"小张说。

业务解释性要求
"工程师们不关心算法原理,他们需要知道'为什么这个数据点被归为异常'。"李工强调。
为此,团队开发了可视化解释工具:
- 用热力图展示各特征对聚类结果的贡献度;
- 通过平行坐标图对比不同簇的特征分布;
- 自动生成包含业务术语的解释报告。
行业生态的协同进化
该企业的实践正在引发连锁反应,2026年9月,其主导制定的《工业数字孪生数据聚类分析应用指南》被纳入中国智能制造标准体系;10月,三家主流工业软件厂商宣布在其数字孪生平台中集成聚类分析模块;11月,某职业培训机构推出"工业数据分析师"认证课程,将聚类分析列为核心技能。
"我们正在构建一个开放的数据分析生态。"李工透露,"下一步计划将聚类模型封装为微服务,通过API供其他企业调用,甚至与设备厂商共享异常模式库,实现预防性维护的产业协同。"
技术演进的新方向
随着研究的深入,聚类分析在工业数字孪生中的应用正在向更深层次拓展:
动态聚类
传统聚类算法假设数据分布固定,但工业场景中设备状态会随时间演变,2026年12月,该团队发布了一项新成果:基于增量学习的动态聚类框架,可实时更新簇中心,适应设备老化等渐进式变化。
多模态融合
除传感器数据外,企业开始整合维修记录、操作日志等非结构化数据,最新实验显示,结合NLP技术提取的文本特征可使聚类准确率提升12%。
边缘计算部署
为降低数据传输延迟,团队正在将轻量级聚类模型部署到车间边缘设备。"我们优化了DBSCAN的内存占用,现在一个树莓派就能实时处理10个传感器的数据流。"硬件工程师小王说。