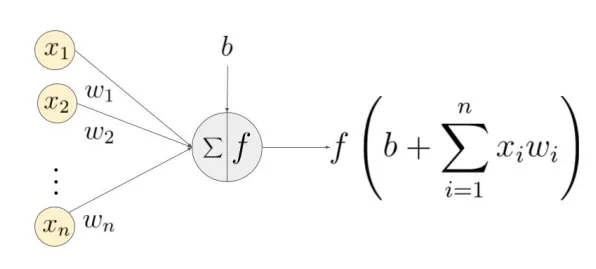在2026年的工业领域,数字孪生技术已从概念验证阶段迈向规模化应用,成为企业实现智能制造、降本增效的核心工具,当工业数字孪生与自然语言处理(NLP)深度融合时,技术实施中的复杂性与挑战逐渐显现,通过对全球多个行业头部企业的实践案例分析,我们发现NLP在工业数字孪生中的落地存在三大关键发现,这些发现直接影响了技术应用的深度与广度。
多模态数据融合是NLP赋能数字孪生的前提,但工业场景的"语言壁垒"远超预期
工业数字孪生的核心是通过物理实体与虚拟模型的实时交互实现预测性维护、工艺优化等功能,而NLP的介入旨在解决设备日志、操作手册、维修记录等非结构化文本数据的解析问题,2026年西门子在德国柏林的智能工厂项目中暴露了一个典型问题:同一台数控机床的故障描述可能同时包含德语操作手册文本、英文系统日志代码、中文维修工笔记,甚至夹杂着设备传感器生成的二进制数据流。
"我们最初试图用单一NLP模型处理所有文本,但准确率不足40%。"项目负责人汉斯·穆勒回忆道,"后来发现,工业场景的'语言'本质上是多模态的——文本、代码、符号、传感器信号甚至操作手势都是信息载体。"为此,西门子联合弗劳恩霍夫研究所开发了"工业语言中枢"系统,该系统首先通过计算机视觉识别设备面板的指示灯状态,将视觉信号转化为结构化数据;再利用NLP解析维修记录中的自然语言描述,提取关键故障特征;最后结合设备历史运行数据,在数字孪生模型中生成故障预测报告,这一多模态融合方案使故障诊断准确率提升至89%,维修响应时间缩短62%。 2026年绿色产品链与碳封存及机构养老热度持续上升,相关领域迎来新发展

类似案例也出现在中国,2026年,三一重工在长沙的"灯塔工厂"中,面对数千台不同年代、不同厂商的工程机械设备的运维数据,采用了"语言-信号-图像"三模态融合方案,当一台挖掘机出现液压系统故障时,系统会同时分析:维修工在移动端输入的语音描述("泵体有异响")、设备传感器记录的液压压力波动曲线、以及摄像头捕捉的油管渗漏图像,通过NLP将语音转化为文本后,与历史维修案例库进行语义匹配,最终在数字孪生模型中定位到具体故障点,该项目负责人透露:"多模态融合使设备综合效率(OEE)提升了18%,但技术难点在于如何建立跨模态的语义对齐标准——我们花了8个月时间才让文本中的'异响'与传感器数据中的'压力尖峰'形成可靠关联。"
工业领域知识图谱的构建质量,直接决定NLP在数字孪生中的"理解深度"
2026年,波音公司在西雅图的飞机装配线上遇到了一个棘手问题:尽管已部署了先进的数字孪生系统,但NLP在解析工程师的技术讨论记录时,仍频繁出现"术语混淆"——例如将"铆钉直径"误判为"孔径",导致虚拟装配模型生成错误指令,深入调查发现,问题根源在于通用NLP模型缺乏航空制造领域的专业知识。
本月聚焦绿色服务网与智慧农业发展新趋势,应用场景不断拓展 "工业场景的NLP不是简单的文本分类或关键词提取,而是需要理解专业术语的上下文关联、工艺流程的逻辑约束,甚至设备操作的因果关系。"波音首席数据科学家艾米丽·陈指出,为此,波音联合麻省理工学院开发了"航空制造知识图谱",该图谱包含12万条专业术语定义、3000个工艺流程节点、以及50万组设备参数关联规则,当NLP检测到文本中的"铆钉"时,会立即调用知识图谱中的关联信息:该铆钉的型号对应哪些装配工具、适用哪些材料厚度、历史故障率如何等,从而在数字孪生模型中生成更精准的装配指令。

中国航天科技集团的实践也印证了这一点,2026年,在长征系列火箭的数字孪生项目中,技术人员发现通用NLP模型无法理解"总装测试-加注燃料-垂直转运"这一典型流程中的时序约束,模型可能将"加注燃料后需等待2小时"误解为"加注燃料和等待可并行",为此,项目组构建了"航天发射知识图谱",将2000余个操作步骤、500组时序约束、300个安全规则转化为结构化知识,当NLP解析操作手册时,会同步调用知识图谱中的时序逻辑,确保数字孪生模型生成的发射流程符合安全规范,该项目负责人表示:"知识图谱的构建成本占项目总投入的35%,但它使NLP的语义理解准确率从68%提升至92%,避免了潜在的安全事故。"
实时性要求倒逼NLP模型轻量化,但工业场景的"长尾需求"又需要模型具备扩展性
2026年,丰田汽车在爱知县的工厂中部署了基于数字孪生的实时质量检测系统,该系统需在100毫秒内完成冲压件表面缺陷的NLP描述生成(右翼子板边缘存在0.3mm划痕")并与数字孪生模型中的标准件进行比对,初始方案采用的BERT大模型因推理延迟达500毫秒,无法满足实时性要求。
"工业场景的NLP应用往往面临'两难选择':大模型精度高但延迟大,小模型延迟低但精度不足。"丰田AI实验室负责人山本健太郎解释道,为此,丰田与东京大学合作开发了"动态剪枝NLP模型",该模型在训练阶段保留完整参数,但在推理阶段根据输入文本的复杂度动态剪枝——当检测到"划痕"这类简单术语时,仅激活模型的前3层;当遇到"多模态耦合振动"这类复杂术语时,再激活全部12层,实验数据显示,该模型在保持91%准确率的同时,将推理延迟压缩至85毫秒,满足实时检测需求。

类似挑战也出现在能源行业,2026年,国家电网在特高压输电线路的数字孪生监控中,需通过NLP实时解析巡检无人机的语音报告("23号塔绝缘子有放电声")并生成维修工单,由于输电线路分布广泛,部分偏远地区网络带宽有限,大模型无法实时传输至云端处理,为此,国家电网联合清华大学开发了"边缘-云端协同NLP系统":在无人机端部署轻量化模型(仅200MB),负责初步语义理解("绝缘子-放电声-需检修");在云端部署完整模型,负责复杂语义分析("放电声频率与历史故障案例匹配度87%"),这一方案使语音报告处理延迟从3.2秒降至0.8秒,同时支持离线场景下的基础功能运行。
"工业场景的NLP需求就像'长尾分布'——80%的请求是简单术语识别,20%是复杂语义分析。"国家电网AI负责人指出,"轻量化模型能覆盖大部分基础需求,但必须保留扩展接口,以便在遇到复杂场景时调用云端大模型。"当无人机报告"绝缘子表面有白色沉积物"时,边缘模型可初步判断为"污秽",但若需进一步分析沉积物成分(如盐密、灰密),则需将语音和图像数据上传至云端,通过多模态大模型生成详细报告。
实践中的"隐形门槛":数据治理与人才缺口
除了上述技术发现,2026年的工业实践还暴露了两个"隐形门槛",首先是数据治理难题:三一重工在实施数字孪生项目时发现,不同部门的数据格式差异巨大——研发部门用XML记录设备参数,生产部门用Excel,维修部门用纸质表单扫描件,为统一数据格式,三一投入了大量资源开发数据中台,但仍有30%的历史数据因格式混乱无法直接用于NLP训练。"数据治理的成本往往被低估,它占项目总投入的25%以上。"三一重工CIO表示。
人才缺口,波音公司在项目中发现,既懂航空制造又懂NLP的复合型人才极度稀缺。"我们不得不从计算机学院和航空工程学院各招一批人,然后花6个月时间让他们互相学习对方领域的基础知识。"艾米丽·陈坦言,"这种'跨界培养'模式效率低下,未来可能需要高校开设'工业NLP'这样的交叉学科。"
本月绿色消费圈与绿色信息网热度持续上升,相关领域迎来新机遇 2026年的工业数字孪生实践表明,NLP的融入并非简单的技术叠加,而是需要解决多模态融合、领域知识嵌入、实时性平衡等核心问题,从西门子的多模态语言中枢到波音的知识图谱,从丰田的动态剪枝模型到国家电网的边缘-云端协同,这些实践为工业NLP的落地提供了宝贵经验——而如何将这些经验转化为可