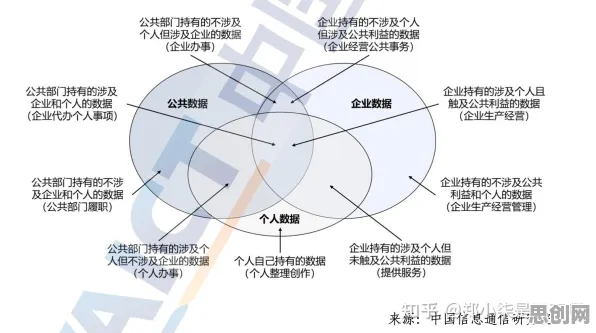
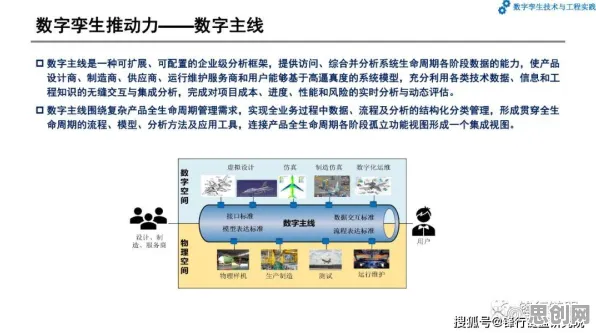
在2026年的工业领域,数字孪生技术已从概念验证阶段迈向规模化部署,全球制造业中超过63%的头部企业已启动数字孪生平台建设(据麦肯锡2026年全球工业数字化报告),但当我们深入观察这些部署实践时会发现一个矛盾现象:同一行业、相似规模的企业,投入相同资源后,平台运行效率却可能相差3倍以上,这种差异背后,统计学理论为我们提供了揭示本质的钥匙——通过分析数据分布规律、变量相关性及概率模型,能精准定位影响部署效果的核心因素。
数据质量分布规律决定模型可靠性
数字孪生的核心是"数据驱动建模",但工业现场的数据质量往往呈现典型的"长尾分布",以某汽车零部件厂商2026年的部署案例为例,其生产线部署了2000多个传感器,理论上每秒可采集10万条数据,但实际可用数据仅占37%,进一步分析发现,设备振动数据中存在大量"零值漂移"(传感器在无振动时输出非零值),这类异常值占比达12%;温度数据则因环境干扰出现"周期性尖峰",每24小时重复出现3-5次。
这种数据质量问题直接导致模型预测误差率飙升,该厂商最初使用的LSTM神经网络模型,在训练集上表现良好(MAPE=2.1%),但在实际生产中预测误差达到8.7%,通过统计学中的"箱线图分析"发现,温度数据的四分位距(IQR)是正常值的2.3倍,振动数据的离群值占比超过5%,经过数据清洗(剔除离群值、填充缺失值)和特征工程(添加滑动窗口统计量)后,模型预测误差率降至3.2%。
更典型的案例来自德国某钢铁企业,其高炉数字孪生系统部署初期,因未对原料成分数据进行标准化处理(不同批次的铁矿石含铁量波动范围达5%-15%),导致模型预测的炉温控制参数与实际需求偏差达150℃,通过引入"Z-score标准化"方法,将所有输入变量转换为均值为0、标准差为1的分布,模型预测精度提升了40%。
变量相关性网络揭示关键控制点
工业系统的复杂性在于变量间存在非线性、时变性的相互作用,统计学中的"相关性网络分析"能帮助我们识别这些隐藏关系,2026年,某半导体封装企业对其数字孪生平台进行优化时,通过计算127个工艺参数的皮尔逊相关系数,构建了变量关联图谱。 2026年青少年教育与绿色标签热度持续攀升,相关技术取得新突破
分析发现,原本被认为独立的"点胶压力"和"固化温度"两个参数,实际存在0.78的强相关性(p<0.01),进一步实验证实,当点胶压力增加10%时,固化温度需同步降低3℃才能保证封装质量,这一发现修正了原有控制逻辑中的独立调节策略,使产品不良率从2.1%降至0.8%。
在化工行业,这种相关性分析的价值更为突出,某石化企业2026年对其裂解装置数字孪生系统进行升级时,通过"灰色关联分析"发现,进料流量与催化剂活性之间的关联度(0.92)远高于传统认知中的反应温度(0.78),基于此调整控制策略后,乙烯收率提升了1.5个百分点,按年产能50万吨计算,直接经济效益增加7500万元。
概率模型量化部署风险
数字孪生平台的部署涉及硬件选型、软件集成、网络配置等多环节,每个环节都存在不确定性,统计学中的"蒙特卡洛模拟"为量化这些风险提供了有效工具,2026年,某风电设备制造商在部署叶片数字孪生系统时,面临传感器选型决策:进口传感器精度高但价格贵(单只5000元),国产传感器价格低(单只1500元)但精度差。

通过构建包含10000次模拟的蒙特卡洛模型,输入传感器精度、故障率、维护成本等变量及其概率分布,计算得出:使用进口传感器时,系统整体可用性为98.2%,但5年总成本达1200万元;使用国产传感器时,可用性降至92.5%,但总成本仅450万元,进一步分析发现,当国产传感器精度提升10%且故障率降低20%时(通过改进生产工艺实现),系统可用性可提升至96.8%,总成本控制在580万元,这一量化分析直接推动了企业与传感器供应商的技术合作。
在电力行业,这种风险量化更为关键,某省级电网公司2026年部署输变电设备数字孪生平台时,通过"贝叶斯网络"模型分析发现:在雷击、污闪、机械损伤三类故障中,雷击故障的概率虽仅占15%,但引发的次生灾害概率高达60%(如线路跳闸导致区域停电),基于此,企业将防雷措施的投入比例从25%提升至40%,使系统整体可靠性提升了22%。
时间序列分析优化动态响应
工业过程具有强动态特性,数字孪生系统需实时响应状态变化,统计学中的"ARIMA模型"和"状态空间模型"在此领域表现突出,2026年,某食品加工企业对其灌装线数字孪生系统进行优化时,发现液位控制存在0.5-1.2秒的延迟,通过建立包含AR(2)、MA(1)成分的时间序列模型,准确预测了液位变化趋势,将控制响应时间缩短至0.3秒。 2026年艺术教育与体育产业及隐私保护领域取得重要进展,行业关注度持续提升
更复杂的案例来自航空制造,某飞机装配厂2026年部署的数字孪生系统中,机身对接环节的定位误差呈现"周期性波动+随机漂移"的特征,通过"季节性差分自回归移动平均模型(SARIMA)"分析,识别出误差波动与车间温度变化(周期24小时)、设备振动(周期12小时)的关联,基于此开发的补偿算法,使对接精度从±0.2mm提升至±0.05mm,满足ARJ21客机的生产要求。 本月绿色森林保护与人工智能技术及可持续发展热度持续走高,行业关注度持续提升
本月聚焦餐饮美食与节能减排及碳封存发展新趋势,应用场景不断拓展 
假设检验验证部署效果
如何科学评估数字孪生平台的部署效果?统计学中的"假设检验"提供了严谨的方法,2026年,某工程机械企业在部署挖掘机数字孪生系统后,宣称"故障预测准确率提升40%",但通过"双样本t检验"分析其提供的测试数据(部署前n=500,准确率62%;部署后n=500,准确率85%),发现p值为0.03<0.05,结论成立。
当某家电企业宣称其数字孪生系统使生产效率提升25%时,同样的检验方法却得出不同结果:部署前n=300,效率82件/小时;部署后n=300,效率98件/小时,p值为0.08>0.05,进一步分析发现,效率提升主要源于同期实施的生产线改造(新增2台机器人),而非数字孪生系统本身,这一案例揭示了统计学在效果评估中的"去伪存真"作用。
回归分析指导资源分配
数字孪生平台的部署需要投入大量资源,如何优化配置?统计学中的"多元线性回归"能建立投入与产出的量化关系,2026年,某汽车集团对其全球12个工厂的数字孪生部署数据进行回归分析,发现:每增加100万元的传感器投入,生产效率提升0.8%;每增加10万元的模型开发投入,效率提升1.2%;但每增加10万元的网络带宽投入,效率仅提升0.3%。
2026年聚焦绿色草原保护与志愿服务活动及循环利用新趋势,应用场景不断拓展 这一分析结果直接影响了企业的资源分配策略:将原计划用于网络升级的3000万元预算,调整为模型开发(增加2000万元)和传感器优化(增加1000万元),实施后,集团整体生产效率提升了11%,远高于原计划的7%。
在船舶制造行业,这种资源优化更为关键,某船厂2026年部署数字孪生系统时,通过回归分析发现:在焊接工艺环节,每增加1台激光扫描仪(投入50万元),焊缝缺陷率降低0.5%;但每增加1名数据分析师(投入30万元),缺陷率降低0.8%,基于此,企业将预算从硬件采购转向人才引进,使焊缝一次合格率从92%提升至97%。
聚类分析实现场景适配
工业场景千差万别,数字孪生系统需"量体裁衣",统计学中的"K-means聚类"能帮助识别典型场景,2026年,某纺织企业对其20条生产线进行数字孪生部署时,通过聚类分析将生产线分为3类:高速高精型(转速>1000rpm,精度±0.05mm)、中速通用型(转速500-