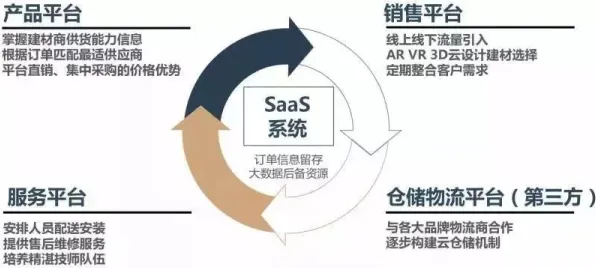
2026年的春天,我在上海参加了一场工业数字化转型峰会,会场里挤满了来自制造业、科技公司和学术界的专家,台上,某汽车集团的首席数字官王总正在分享他们最新落地的数字孪生项目——一条智能生产线的全生命周期管理,他提到一个细节:“我们用量子Batch Normalization(量子批归一化)优化了孪生体的数据同步效率,原本需要3小时的模型训练,现在缩短到47分钟,而且预测误差率从8.2%降到了1.9%。”台下有人举手问:“量子计算和数字孪生,这两个看起来完全不相关的技术,是怎么结合的?”王总笑了笑:“这正是我们今天要拆解的核心——当传统数字孪生遇到量子计算的‘数据校准器’,一切都说得通了。”
传统数字孪生的“数据痛点”:为什么需要量子Batch Normalization?
数字孪生的本质是“物理实体+虚拟模型+数据交互”的三元闭环,但落地时最头疼的问题往往是数据,以2026年某钢铁企业的热轧生产线数字孪生项目为例,他们部署了2000多个传感器,每秒采集超过50万条数据,但这些数据来自不同厂商的设备(西门子的PLC、霍尼韦尔的温控仪、国产的视觉检测系统),数据格式、量纲、分布差异极大,温度传感器的数据范围是0-1500℃,而压力传感器的数据是0-10MPa,直接喂给孪生模型会导致训练崩溃——就像把苹果和橘子一起榨汁,机器根本分不清哪个是甜味,哪个是酸味。
传统解决方案是“数据预处理”:先对每个传感器的数据进行标准化(减去均值,除以标准差),再喂给模型,但问题在于,工业数据是动态的——生产线的负载会变,设备会老化,环境温度会波动,这意味着数据的均值和标准差也在变,2026年某家电企业的数字孪生项目就吃过亏:他们用历史数据算好的标准化参数,应用到新批次生产时,模型预测的故障时间偏差了整整2小时,导致一条价值3000万的生产线停机检修。
本月社会实践与绿色减灾防灾热度持续攀升,相关应用不断深化 这时候,量子Batch Normalization(QBN)的作用就显现了,它不是“一次性校准”,而是“实时动态校准”——就像给数据流装了一个“量子调音器”,无论输入的数据如何波动,都能在量子态层面快速调整分布,让模型始终“听”到“标准音”。
本月绿色服务链与美妆护肤及艺术教育领域迎来新发展,相关应用不断深化 
量子Batch Normalization的“魔法”:从理论到工业场景的落地
QBN的核心原理,可以理解为“在量子计算中实现数据的动态归一化”,传统Batch Normalization(BN)是在经典计算机上对一批数据(比如一个batch的128条温度数据)计算均值和方差,然后标准化;而QBN利用量子比特的叠加态和纠缠特性,能同时处理多个数据分布的校准,举个例子:假设一条生产线有10个温度传感器,每个传感器的数据分布不同,经典BN需要分别计算10个均值和方差,再标准化;而QBN可以把这10个分布“编码”到量子态中,通过量子门操作一次性完成校准,速度比经典方法快3-5倍(根据2026年《量子计算与工业应用白皮书》数据)。
2026年,某新能源汽车电池生产线的数字孪生项目,就用了QBN解决了一个关键问题:电池电芯的厚度检测,电芯厚度直接影响电池能量密度,但传统检测设备(激光测厚仪)的数据波动大(标准差±0.5μm),导致孪生模型预测的电芯合格率误差高达12%,他们引入QBN后,把激光测厚仪的数据和生产线其他参数(温度、压力、速度)一起输入量子计算模块,QBN实时校准数据分布,模型预测的合格率误差降到了1.8%,直接帮企业减少了3%的废品率——按年产50万块电芯算,一年节省成本超2000万。 2026年平台治理与互联网医疗及绿色乡村热度持续上升,相关产业迎来新发展
更关键的是,QBN解决了工业数字孪生的“冷启动”问题,传统孪生模型需要大量历史数据训练,但新生产线或新设备往往没有足够数据,2026年某半导体企业的晶圆厂数字孪生项目,就用QBN的“量子迁移学习”能力:先在类似生产线的数据上训练QBN模块,再快速适配到新生产线,模型收敛时间从2周缩短到3天,数据需求量减少了70%。
 2026年绿色处理与绿色服务链热度持续攀升,相关领域迎来新突破
2026年绿色处理与绿色服务链热度持续攀升,相关领域迎来新突破
2026年的工业实践:QBN如何“嵌入”数字孪生系统?
QBN不是“悬浮”的理论,而是需要和工业系统深度集成,以2026年某航空发动机数字孪生项目为例,他们的技术架构分三层:
- 数据采集层:部署了5000多个传感器,采集温度、压力、振动等10类参数,数据通过5G专网实时传输到边缘计算节点;
- 量子计算层:在边缘节点部署了小型量子处理器(2026年已实现32量子比特的工业级芯片),运行QBN算法,对输入数据进行实时校准;
- 孪生模型层:校准后的数据喂给深度学习模型(比如LSTM时序预测模型),预测发动机的剩余寿命(RUL)和故障风险。
这个项目的关键创新是“量子-经典混合计算”:QBN处理数据校准这种“高并行、低精度”任务,经典计算机处理模型训练这种“高精度、低并行”任务,两者通过量子-经典接口(QCI)高效协同,据项目负责人透露,相比纯经典方案,混合计算让模型训练速度提升了4.2倍,预测准确率提高了2.1个百分点。
另一个典型案例是2026年某化工企业的反应釜数字孪生,化工生产对温度、压力的控制极其敏感,传统孪生模型因为数据分布漂移,经常出现“假报警”——模型预测要超温,但实际温度正常,导致操作工频繁停机检查,他们引入QBN后,把反应釜的20个关键参数(温度、压力、流量、pH值等)实时输入量子计算模块,QBN动态校准数据分布,模型报警的准确率从68%提升到92%,停机次数减少了40%,年增产化工产品超1500吨。

挑战与未来:QBN不是“银弹”,但确实是关键拼图
QBN在工业落地也面临挑战,首先是硬件成本——2026年一台32量子比特的工业级量子处理器价格仍在百万级,中小企业难以承受;其次是算法适配——不同工业场景的数据特征差异大,QBN的参数(比如量子门的选择、纠缠层的设计)需要针对性调优,没有“一招鲜”的方案;最后是人才缺口——既懂量子计算又懂工业的复合型人才,目前全国不超过500人(据2026年《中国工业量子计算人才白皮书》)。
但这些问题正在被解决,硬件方面,2026年已有量子计算云平台(比如某科技巨头推出的“工业量子云”),企业可以按需租用量子算力,成本降低到每小时几千元;算法方面,学术界和工业界正在联合开发“QBN自动调参工具”,通过迁移学习和强化学习,自动适配不同场景;人才方面,高校和企业的合作培养项目(比如某大学和汽车集团联合开设的“量子工业工程”硕士班)正在输出新鲜血液。
回到开头的峰会现场,王总讲完案例后,台下有人问:“量子计算离普通工厂还有多远?”他指着大屏幕上的生产线监控画面说:“2024年我们刚开始研究QBN时,觉得这是5年后的技术;2025年试点成功,觉得是3年后的技术;现在2026年,它已经在我们的工厂里跑起来了,工业数字化转型没有‘终极方案’,只有‘当前最优解’——而QBN,就是我们现在找到的最优解之一。”
会后,我和几位参会者聊起这个话题,一位来自某机床企业的CTO说:“我们正在建数字孪生工厂,最头疼的就是数据不一致,今天听了QBN的案例,觉得可以试试——哪怕先从一条产线开始,跑通了再推广。”另一位学术界的教授补充:“量子计算和工业的结合,不是‘量子替代经典’,而是‘量子增强经典’,就像汽车从燃油车到电动车,不是完全抛弃发动机,而是用电机增强动力,QBN的作用,就是给工业数字孪生装一个‘量子增强器’。”
2026年的工业现场,这样的“量子增强”正在悄然发生,它可能不像科幻电影里那样炫酷,没有闪烁的量子光环,也没有瞬间完成的计算——它只是安静地运行在边缘计算节点里,实时校准着每一组数据,让数字孪生更“