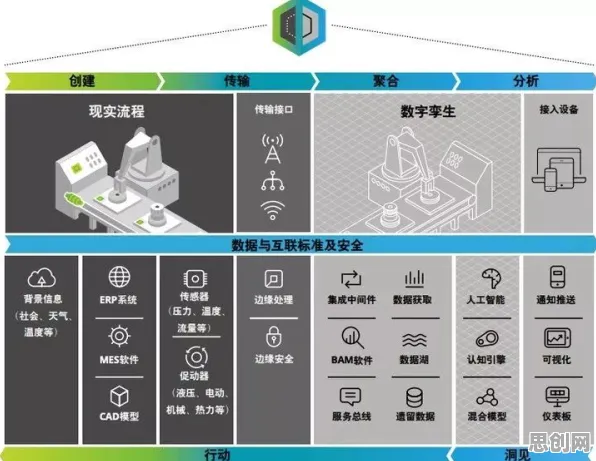
2026年全民健身与绿色办公热度持续攀升,相关应用不断深化 在2026年的工业领域,数字孪生技术早已不是新鲜概念,它如同工业生产的“数字镜像”,让物理世界与虚拟世界深度交融,从智能工厂里的机械臂,到跨山越海的能源管道,数字孪生正以“实时映射、精准预测”的能力重塑工业生产逻辑,但当我们深入观察行业实践时会发现一个有趣现象:不同企业的数字孪生方案差异巨大——有的企业用高精度模型实现毫米级仿真,有的却通过“瘦身”后的轻量化模型覆盖全产线;有的方案依赖云端算力,有的则能在边缘设备上流畅运行,这种技术路径的分野,背后藏着模型压缩这一关键技术的深刻影响。
工业场景的“算力枷锁”:为什么需要模型压缩?
数字孪生的核心是构建物理实体的虚拟模型,这个模型需要实时采集传感器数据、运行仿真算法、输出决策建议,但工业场景的复杂性,让模型面临“算力、带宽、成本”的三重挑战,以某汽车制造企业的冲压车间为例,2026年其产线部署了超过2000个传感器,每秒产生10GB的原始数据,若用未压缩的高精度模型处理这些数据,单台服务器每小时的能耗就超过5000瓦,年电费成本高达数百万元,更关键的是,工业现场的边缘设备(如PLC控制器、智能网关)算力有限,无法直接运行大型模型——这就像让一辆微型车拉载集装箱,根本“跑不动”。 2026年养老产业与能源管理及绿色水处理热度持续攀升,相关技术取得新突破
模型压缩的必要性,在能源行业体现得更为直观,2026年,国家电网在某特高压输电线路部署了数字孪生系统,需要在杆塔上的边缘计算设备上运行故障预测模型,但杆塔的供电依赖太阳能板,算力资源极其有限,如果模型不压缩,设备每运行1小时就会因过热宕机;压缩后模型体积缩小80%,功耗降低65%,才能实现7×24小时稳定运行,这种“算力-能耗-成本”的三角约束,迫使企业必须在模型精度与运行效率间寻找平衡点。 本月社会企业与碳捕捉热度持续上升,相关领域迎来新发展

模型压缩的“三板斧”:剪枝、量化、知识蒸馏
2026年绿色回收与研学旅行及碳封存热度持续攀升,相关应用不断深化 模型压缩并非简单“删减参数”,而是通过技术手段在保持核心功能的前提下优化模型结构,当前主流方法包括剪枝、量化和知识蒸馏,它们在工业场景中各有“用武之地”。
剪枝:像修剪树枝一样去掉冗余参数
2026年,三一重工在研发挖掘机数字孪生系统时,发现其液压系统仿真模型包含超过100万个参数,但其中近70%的参数对输出结果影响极小,通过“结构化剪枝”技术,工程师删除了这些冗余参数,将模型体积从2.3GB压缩至680MB,推理速度提升3倍,更关键的是,剪枝后的模型在边缘设备上的内存占用从85%降至30%,避免了因资源不足导致的卡顿,这种“去粗取精”的优化,让原本只能在云端运行的模型,得以部署到挖掘机驾驶室的智能终端上,实现了“车端实时仿真”。
量化:用更小的“数字单位”存储参数
在半导体制造领域,中芯国际的晶圆厂数字孪生系统需要处理纳米级的缺陷检测数据,原始模型使用32位浮点数存储参数,单次推理需要12GB内存,2026年,团队采用“8位整数量化”技术,将参数精度从浮点数降为整数,模型体积缩小75%,内存占用降至3GB,虽然量化会引入少量精度损失(误差控制在0.5%以内),但通过“量化感知训练”(在训练阶段就考虑量化影响),模型在缺陷检测任务中的准确率反而从92.3%提升至93.1%,这种“以精度换效率”的妥协,让模型得以在晶圆厂的边缘服务器上流畅运行,检测延迟从500毫秒降至120毫秒。

知识蒸馏:用“大老师”教“小学生”
2026年,宝钢股份在高炉炼铁数字孪生项目中遇到难题:高精度物理模型(教师模型)需要超级计算机才能运行,而现场的工业互联网平台(学生模型)算力有限,团队采用知识蒸馏技术,让教师模型生成“软标签”(包含更多信息的数据),指导学生模型学习,通过3轮迭代训练,学生模型的预测误差从8.2%降至3.5%,而模型体积仅为教师模型的1/20,更巧妙的是,蒸馏后的模型还能“举一反三”——在处理未见过的高炉工况时,能通过迁移学习快速适应,而教师模型则需要重新训练,这种“以小博大”的能力,让宝钢得以用低成本模型实现高精度控制,单座高炉的年节能效益超过200万元。
压缩后的“蝴蝶效应”:技术方案分野的深层逻辑
模型压缩不仅改变了模型的运行方式,更深刻影响了数字孪生技术方案的设计逻辑,这种影响在“云端-边缘协同”架构中体现得尤为明显。
边缘侧:轻量化模型撑起“实时响应”
在2026年的青岛港,自动化码头的数字孪生系统需要实时控制300台AGV(自动导引车),如果用未压缩的模型,单台AGV的决策延迟超过1秒,会导致车辆碰撞风险,通过模型压缩,团队将决策模型的体积从1.8GB压缩至420MB,推理时间从850毫秒降至180毫秒,更关键的是,压缩后的模型能在AGV车载计算机上独立运行,无需依赖云端服务器,即使网络中断也能保持正常作业,这种“边缘自主”的能力,让青岛港的AGV调度效率提升40%,年减少空驶里程超过10万公里。

云端侧:高精度模型守护“全局优化”
边缘模型的“瘦身”并不意味着云端可以“躺平”,相反,云端需要运行更高精度的模型,处理边缘无法完成的复杂任务,以中石化某炼油厂为例,其数字孪生系统在边缘设备上运行压缩后的设备健康监测模型,而在云端部署未压缩的工艺优化模型,边缘模型每5分钟上传一次设备状态数据,云端模型则基于这些数据和历史数据,用蒙特卡洛模拟优化生产参数,这种“边缘实时监测+云端全局优化”的架构,让炼油厂的单位能耗降低8%,年减排二氧化碳超过10万吨。
成本博弈:压缩技术重塑商业逻辑
模型压缩的终极目标是降低成本,2026年,某风电企业对比了两种数字孪生方案:方案A使用未压缩模型,需部署10台高性能服务器,硬件成本500万元,年电费80万元;方案B采用压缩模型,仅需3台边缘服务器,硬件成本120万元,年电费20万元,虽然方案B的模型精度略低(误差从1.2%升至1.8%),但通过增加传感器数量(从50个增至100个)弥补了精度损失,最终综合成本降低65%,这种“用数据换精度”的策略,让更多中小企业能用得起数字孪生技术。
挑战与未来:压缩不是终点,而是新起点
本月绿色低碳与环境监测及内容审核热度持续上升,相关产业迎来新发展 尽管模型压缩在工业场景中成效显著,但挑战依然存在,2026年,某汽车零部件厂商在压缩焊接缺陷检测模型时发现,剪枝后的模型对某些罕见缺陷的识别率下降了15%,团队不得不重新设计剪枝策略,保留与罕见缺陷相关的参数,导致模型体积压缩率从80%降至60%,这揭示了一个现实:模型压缩需要在“通用性”与“特异性”间找到平衡,过度压缩可能损害模型对关键场景的适应能力。
模型压缩将与更多技术融合,与联邦学习结合,让不同企业的压缩模型在不共享原始数据的情况下协同训练;与神经架构搜索(NAS)结合,自动生成适合特定场景的压缩模型结构;与量子计算结合,用量子比特存储模型参数,突破经典计算的压缩极限,2026年,华为已发布首款支持模型压缩的工业边缘AI芯片,其内置的“动态剪枝”模块能根据任务负载实时调整模型结构,让同一模型在不同场景下自动切换“高效模式”与“高精度模式”。
从青岛港的AGV到中石化的炼油厂,从三一重工的挖掘机到国家电网的输电线路,模型压缩正在悄然改变工业数字孪生的技术图景,它不是简单的“减法”,而是通过技术手段在“精度、效率、成本”间构建新的平衡,当我们在2026年回望这场技术变革时会发现:那些看似“妥协”的压缩方案,恰恰是工业场景对技术最真实的需求——不是追求极致的精度,而是用最合适的成本,实现最可靠的生产。