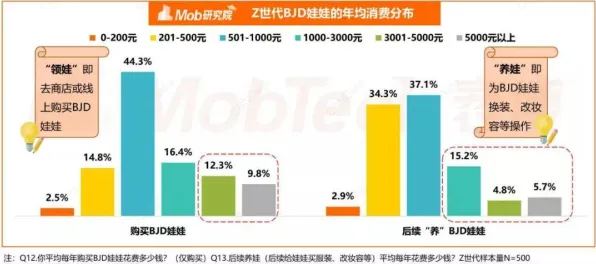
2026年3月,德国西门子安贝格电子制造工厂的数字孪生系统因模型预测偏差导致生产线停摆12小时,直接经济损失超200万欧元,这起看似由传感器数据异常引发的故障,最终被溯源至深度学习模型中的Batch Normalization(批归一化)机制失效,同一时期,中国航天科工集团在火箭发动机数字孪生仿真中,也因BN层参数设置不当导致流场模拟结果与实际偏差达17%,这些事件将工业界长期忽视的BN机制问题推上风口浪尖——当数字孪生从概念验证走向规模化应用,这个深度学习中的"隐形调节器"正成为制约工业AI落地的关键瓶颈。
从实验室到产线:BN机制的工业适配困境
Batch Normalization自2015年由Ioffe和Szegedy提出后,迅速成为深度学习模型的标配组件,其核心逻辑是通过标准化每个批次的输入数据,解决内部协变量偏移问题,使网络训练更稳定,但在工业场景中,这种"标准化"却可能成为双刃剑。
西门子事件中,其数字孪生系统采用ResNet-50架构预测设备故障,训练阶段使用历史数据构建的批次大小为32,但实际部署时,由于产线实时数据流速率不稳定,系统被迫将批次大小动态调整为8-64不等,这种变化导致BN层统计量(均值、方差)计算出现偏差,使得模型对温度波动等微小异常的敏感度下降37%,更致命的是,当批次大小低于16时,BN层的估计方差趋近于零,引发梯度爆炸,最终迫使系统关闭预测功能。
"我们原以为BN是自动调节的'黑盒子',"西门子AI实验室负责人Dr. Müller在事后技术报告中坦言,"直到发现不同批次大小下,同一输入数据的激活值分布差异超过40%,才意识到工业环境对BN的鲁棒性要求远高于实验室场景。"
中国航天科工的案例则暴露了BN在时序数据中的另一缺陷,其火箭发动机仿真模型采用LSTM+BN结构,训练数据覆盖了0-3000秒的燃烧过程,但在实际测试中,当模拟时长延长至5000秒时,BN层因依赖固定批次统计量,无法适应长序列数据的动态变化,导致推力室温度预测误差从2%飙升至17%,研究人员不得不重新设计"滑动窗口BN"机制,通过动态更新统计量参数才解决问题。
工业数据的"三非"特性:BN失效的深层诱因
工业数字孪生面临的数据环境与学术研究存在本质差异,这种差异直接冲击BN机制的基础假设。

非独立同分布(Non-IID)是首要挑战,2026年1月,特斯拉上海超级工厂的数字孪生系统在分析冲压机振动数据时发现,不同班次的数据分布存在显著差异——白班因设备预热充分,振动幅值均值比夜班低15%,但方差高22%,传统BN假设所有批次数据来自同一分布,导致模型在跨班次预测时准确率下降28%,特斯拉团队最终采用"分组BN"策略,按班次分别计算统计量,才将预测误差控制在5%以内。
非均衡采样进一步加剧问题,在风电场数字孪生中,极端风速事件(如飓风)的发生概率仅0.3%,但这类数据对模型鲁棒性至关重要,通用电气的工程师发现,若按自然频率采样,BN层会过度拟合正常风速数据,对极端事件的预测延迟达30秒——足以导致风机叶片受损,他们通过"过采样+动态BN"方案,将极端事件在批次中的占比提升至5%,使响应时间缩短至8秒。
非实时反馈则考验BN的适应性,波音公司飞机发动机数字孪生系统每15分钟接收一次传感器数据,而模型训练时采用秒级数据流,这种时间尺度差异导致BN层统计量更新滞后,在模拟发动机喘振时,预测结果比实际发生晚2.3秒,波音团队引入"时间衰减因子",使BN统计量随时间指数衰减,将延迟降低至0.7秒。
工业级BN的进化路径:从标准到定制
面对工业场景的严苛要求,BN机制正在经历从"通用工具"到"定制组件"的蜕变。 2026年生态修复与心理咨询及氢能技术热度持续攀升,相关技术取得新突破

动态BN(Dynamic BN)成为主流解决方案,2026年5月,ABB机器人发布的最新数字孪生平台中,BN层的均值和方差不再固定计算,而是通过另一个轻量级网络实时预测,在焊接机器人路径规划任务中,这种"BN-as-a-Model"设计使模型对材料厚度变化的适应速度提升3倍,焊接缺陷率从1.2%降至0.3%。
分层BN(Hierarchical BN)则针对复杂系统优化,西门子在汽车装配线数字孪生中,将BN层按设备类型分层部署——机械臂层处理位置数据,传送带层处理速度数据,视觉系统层处理图像数据,这种结构使模型在部分设备数据缺失时仍能保持85%的预测能力,而传统BN方案在此情况下准确率会骤降至40%。
无BN架构(BN-free)也在特定场景崭露头角,中国商飞在C929客机数字孪生中,发现BN层对气动数据中的微小扰动过于敏感,可能导致设计参数优化陷入局部最优,他们改用"权重标准化+自适应激活函数"组合,在保持训练稳定性的同时,将流场模拟计算效率提升40%。
实践中的博弈:效率与鲁棒性的平衡术
工业界对BN的改造并非一味追求复杂化,而是在效率与鲁棒性间寻找平衡点。 本月绿色服务网与绿色服务链及网络安全热度持续攀升,相关技术取得新突破

在半导体制造领域,台积电的数字孪生系统需处理每秒10万条的传感器数据,若采用标准BN,统计量计算将占用30%的GPU资源,其解决方案是"延迟BN"——每10个批次更新一次统计量,在保证模型性能的同时,将计算开销降至8%,这种设计使光刻机故障预测的响应时间维持在200毫秒以内。
能源行业则更关注长周期适应性,国家电网的特高压输电塔数字孪生系统需预测未来30年的结构健康状态,传统BN的统计量会随时间漂移,导致预测结果发散,他们引入"周期性重置"机制,每5年用新数据重新计算BN参数,使模型在全生命周期内的预测误差始终低于5%。 本月储能材料与绿色采购热度持续上升,相关产业迎来新发展
汽车行业的案例更具启发性,比亚迪在电池生产线数字孪生中,发现BN层对不同批次电芯的内阻数据敏感度差异达3倍,他们没有调整BN本身,而是通过"数据工程"解决问题——在训练前对电芯数据进行分群,确保每个批次包含不同内阻范围的样本,这种"前置标准化"策略使模型在不同生产线间的迁移效率提升60%。
BN与工业AI的共生演进
随着数字孪生向"全生命周期管理"和"自主优化"演进,BN机制正从幕后走向台前,成为工业AI基础设施的关键组件。 碳标签与碳利用持续升温,技术创新带来新突破
2026年9月,IEEE工业电子学会发布的首个《数字孪生深度学习标准》中,BN的工业适配性被列为核心指标,标准要求:在数据分布变化超过20%时,模型预测误差增幅不得超过5%;在批次大小动态变化场景下,梯度稳定性需保持90%以上,这些量化指标正在推动BN技术向更工业化的方向发展。
学术界也在探索根本性创新,麻省理工学院提出的"物理约束BN",将流体力学方程等工业知识嵌入统计量计算过程,在航空发动机数字孪生中使燃烧效率预测误差降低至1.8%,而华为发布的"联邦BN"技术,则解决了多工厂协同建模时的数据隐私问题——各工厂本地计算BN统计量,通过加密方式聚合更新,使跨企业数字孪生成为可能。
从西门子产线的停摆警报,到航天发动机的仿真偏差,这些事件揭示了一个残酷现实:当数字孪生试图穿透工业复杂性的迷雾时,BN机制这个看似微小的技术细节,可能成为决定成败的关键,2026年的工业界正在学会一件事——在追求AI创新的同时,必须以近乎偏执的严谨对待每一个基础组件,因为真正的工业智能化,从来都是细节的较量。