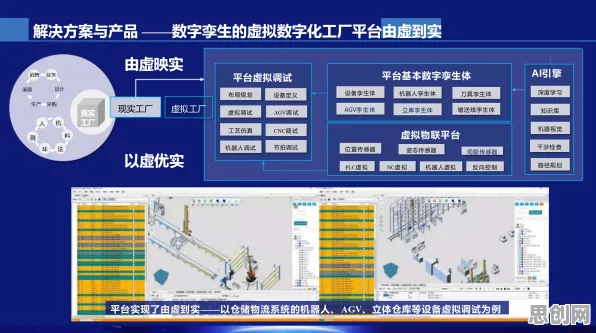
绿色创新链与碳利用热度持续上升,相关产业迎来新发展 2026年的工业领域,数字孪生技术正以惊人的速度改变着传统生产模式,从德国西门子安贝格电子制造工厂的智能产线,到中国三一重工长沙“灯塔工厂”的实时设备监控,数字孪生已不再是概念,而是成为企业降本增效的核心工具,但在这场技术革命背后,有一个关键角色始终隐于幕后——神经网络,它像数字孪生的“大脑”,让虚拟模型能精准映射物理世界,甚至预测未来,要理解工业数字孪生为何能落地生根,必须先拆解神经网络的技术逻辑。
神经网络:从生物模拟到工业智能的进化史
神经网络并非横空出世的新技术,它的灵感源于1943年麦卡洛克和皮茨提出的“人工神经元模型”,试图用数学公式模拟人类大脑神经元的工作方式,但真正让神经网络从理论走向实用的,是20世纪80年代的反向传播算法(Backpropagation)和2012年深度学习的突破——那一年,Hinton团队用卷积神经网络(CNN)在ImageNet图像识别竞赛中一战成名,错误率从26%降至15%,直接推动了AI技术的爆发。
本月节能减排与青少年科学素养及社区服务热度持续攀升,相关应用不断深化 到了2026年,神经网络已进化出更复杂的结构,以工业场景常用的时序神经网络(LSTM/GRU)为例,它能处理设备传感器产生的海量时序数据,捕捉设备运行中的微小异常,在施耐德电气的法国勒阿弗尔工厂,一条价值2000万欧元的自动化生产线,通过部署LSTM模型,能提前48小时预测电机轴承的磨损风险,将非计划停机时间减少了70%,这种能力,正是数字孪生“预测性维护”功能的核心支撑。
更值得关注的是图神经网络(GNN)的崛起,2026年,GNN已成为处理工业复杂系统关系的利器,以波音公司的飞机数字孪生为例,一架飞机有超过10万个零部件,每个零部件的故障都可能引发连锁反应,GNN通过构建零部件之间的关联图谱,能模拟故障传播路径,帮助工程师快速定位根本原因,2026年3月,波音发布的数据显示,应用GNN后,故障排查时间从平均12小时缩短至2小时,维修成本降低35%。
神经网络如何“驱动”数字孪生?三个关键场景解析
数字孪生的本质是“物理实体+虚拟模型+数据交互”的三元体系,而神经网络的作用,是让虚拟模型“活”起来——不仅能实时映射物理状态,还能通过学习历史数据预测未来,以下是2026年工业领域最典型的三个应用场景。
场景1:设备健康管理——从“被动维修”到“主动预防”
在工业领域,设备故障是最大的成本黑洞,据麦肯锡2026年报告,全球制造业每年因设备停机造成的损失超过5000亿美元,数字孪生结合神经网络,正在改变这一现状。
以西门子安贝格工厂的SMT贴片机为例,每台设备安装了200多个传感器,每秒产生10MB数据,这些数据通过边缘计算设备预处理后,输入到预训练的神经网络模型中,模型会实时计算设备的“健康指数”,当指数低于阈值时,系统自动触发维护工单,2026年5月,该工厂披露的数据显示,通过这种“预测性维护”模式,设备综合效率(OEE)提升了18%,年维护成本减少2200万欧元。
更复杂的是跨设备协同预测,在巴斯夫的德国路德维希港化工基地,数百台反应釜、泵机和阀门组成一个庞大系统,巴斯夫与IBM合作开发的数字孪生平台,用图神经网络(GNN)建模设备间的关联关系,2026年4月,系统成功预测了一起因阀门卡滞引发的连锁反应,提前12小时关闭相关设备,避免了可能的价值500万美元的生产事故。
场景2:生产优化——从“经验驱动”到“数据驱动”
数字孪生的另一大价值是优化生产流程,传统方式依赖工程师经验,而神经网络能从海量数据中挖掘隐藏规律,实现更精准的参数调整。

三一重工长沙“灯塔工厂”的焊接产线提供了一个典型案例,焊接质量受电流、电压、速度、气体流量等10多个参数影响,传统调试需要工程师花费数周时间,2026年,三一引入强化学习神经网络,让模型通过“试错”学习最优参数组合,系统在虚拟环境中模拟了10万次焊接过程,最终找到一组参数,使焊接合格率从92%提升至98.5%,单条产线年节约返工成本超300万元。
在流程工业中,神经网络的作用更显著,中石化镇海炼化的数字孪生平台,用LSTM模型分析历史生产数据,预测催化裂化装置的产物分布,2026年6月,该模型成功预测了一次因原料变化导致的产物波动,系统自动调整反应温度和压力,使轻质油收率提高了1.2个百分点,按年处理量计算,增收超8000万元。
场景3:供应链协同——从“局部优化”到“全局智能”
2026年教育公益与家居装饰热度持续上升,相关产业迎来新发展 数字孪生的应用不仅限于单个工厂,还能延伸至整个供应链,神经网络通过处理多源异构数据,实现需求预测、库存优化和物流调度的一体化。
宝马集团的供应链数字孪生项目是一个标杆,宝马在全球有3000多家供应商,每天处理超过10万条物流信息,2026年,宝马与谷歌合作开发的神经网络模型,整合了历史销售数据、天气数据、社交媒体情绪指数(用于预测车型热度)和供应商产能数据,能提前6个月预测区域市场需求,准确率达91%,基于这一预测,系统自动调整生产计划和物流路线,使库存周转率提升了25%,运输成本降低18%。
更复杂的是应对突发风险,2026年7月,东南亚一场台风导致宝马某关键零部件供应商停产,数字孪生系统迅速模拟供应链中断的影响,神经网络模型在2小时内推荐了3套替代方案:调整其他工厂产能、启用备用供应商、修改车型配置,宝马通过调整生产计划,将交货延迟从预计的3周缩短至5天,避免了数亿美元的合同违约损失。

挑战与突破:2026年的神经网络“进化论”
尽管神经网络在工业数字孪生中表现亮眼,但2026年的实践也暴露出三大挑战:数据质量、模型可解释性和计算资源。
挑战1:数据质量——工业数据的“脏乱差”难题
工业数据与互联网数据不同,它具有多模态(温度、压力、振动、图像)、高噪声(传感器误差、环境干扰)和低标签率(故障样本稀缺)的特点,2026年,通用电气(GE)在航空发动机数字孪生项目中发现,原始传感器数据中超过30%存在异常值,直接训练模型会导致预测误差高达40%。
GE的解决方案是构建“数据清洗流水线”:先用统计方法过滤明显异常值,再用自编码器(Autoencoder)神经网络重构数据分布,最后用少量标注数据微调模型,经过这一流程,模型预测误差降至8%,满足工程要求,这一案例也被写入MIT《2026年工业AI白皮书》,成为行业标杆。
挑战2:模型可解释性——“黑箱”如何赢得信任?
热度持续上升环保技术热度持续攀升,相关应用不断深化 工业场景对模型可解释性要求极高,工程师需要知道“为什么模型认为设备会故障”,而不是仅接受一个预测结果,2026年,可解释AI(XAI)技术取得突破,以SHAP值(Shapley Additive exPlanations)为代表的方法被广泛应用。
在西门子医疗的CT机数字孪生项目中,工程师用SHAP值分析模型预测结果,当模型判断某台CT机的球管需要更换时,SHAP值会显示:“过去24小时曝光次数(贡献度45%)”“冷却液温度(贡献度30%)”和“历史故障记录(贡献度25%)”是主要影响因素,这种解释让工程师能验证模型逻辑,甚至根据业务知识调整模型权重,2026年8月,西门子医疗发布的数据显示,应用XAI后,模型采纳率从62%提升至89%。
挑战3:计算资源——边缘端的“轻量化”革命
工业场景对实时性要求极高,但许多工厂的边缘设备算力有限,2026年,模型压缩技术成为关键突破口,以知识蒸馏(Knowledge Distillation)为例,它通过让小模型(学生)学习大模型(教师)的输出分布,实现模型轻量化。
在海尔青岛互联工厂的空调产线,