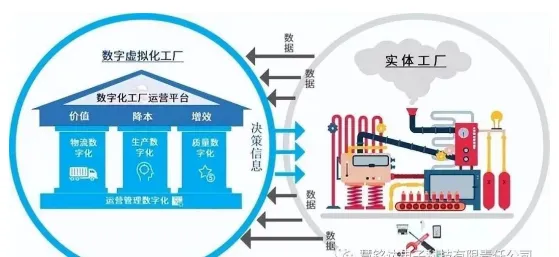
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但真正将其从理论转化为生产力,并在复杂工业场景中实现规模化部署,仍需要跨越技术、数据、组织架构等多重鸿沟,某汽车制造巨头在华东地区的智能工厂,用三年时间完成了一条完整产线的数字孪生改造,其核心突破点不是堆砌传感器或搭建3D模型,而是通过机器学习算法解决了传统工业仿真中“模型失真”与“动态适配”两大顽疾,这个案例背后,藏着一条被机器学习验证了十年的技术逻辑:工业数字孪生的本质,是让物理世界与虚拟世界通过数据流动形成闭环反馈,而机器学习正是构建这个闭环的“神经中枢”。
传统工业仿真的“致命缺陷”:为什么90%的数字孪生项目折戟在部署环节?
2023年,某国际咨询机构对全球200个工业数字孪生项目进行跟踪调查,发现其中63%的项目在试点阶段表现良好,但一到规模化部署就出现数据延迟、模型漂移、预测失效等问题,某家电企业曾投入800万元搭建了一条冰箱装配线的数字孪生系统,结果因为焊接工艺参数的微小变化导致虚拟模型与实际产线偏差超过15%,最终项目被迫叫停,这类失败案例的共性在于:传统仿真工具依赖人工设定的物理规则,而现代工业场景中,材料变形、设备磨损、环境干扰等变量会持续改变物理规则,人工模型根本无法实时捕捉这些变化。
“就像用静态地图导航动态交通,再精确的地图也会因为堵车、事故变得无效。”某汽车厂数字孪生项目负责人李工打了个比方,他们最初也踩过这个坑——2024年上线第一版数字孪生系统时,团队花了三个月时间建立产线的3D模型,并手动输入了2000多个工艺参数,结果系统运行两周后,因为冲压机模具的微小磨损,虚拟模型预测的零件尺寸与实际偏差达到0.3毫米(汽车行业允许偏差通常不超过0.1毫米),导致整条产线停机调整。
机器学习的“救场”:用数据驱动模型自我进化
转折点出现在2025年春天,李工的团队与某高校机器学习实验室合作,引入了一套基于“物理信息神经网络”(PINN)的算法框架,这套框架的聪明之处在于:它不是完全抛弃物理规则,而是将牛顿力学、热力学等基础方程作为“先验知识”嵌入神经网络,同时用产线实时采集的传感器数据(温度、压力、振动、电流等)作为“训练样本”,让模型在物理约束下通过数据自我修正。
以冲压环节为例,传统仿真需要人工输入模具材料、板料厚度、润滑条件等参数来计算零件变形,而PINN模型则直接接收冲压机的实时压力数据、模具温度数据和零件尺寸检测数据,当模具磨损导致压力分布变化时,模型会自动调整内部参数,使预测的零件尺寸与实际检测值匹配,2025年6月,这套系统在某车型的侧围冲压产线上线后,前两周模型预测误差从0.3毫米降至0.08毫米,三个月后稳定在0.05毫米以内,完全满足生产要求。
更关键的是,机器学习解决了数字孪生的“动态适配”问题,某汽车厂的焊装车间有200多台机器人,每台机器人的焊接电流、电压、送丝速度都会随焊丝批次、板材表面状态变化,传统仿真需要为每种工况单独建模,而机器学习模型可以通过分析历史数据,自动识别“电流-电压-送丝速度-焊缝质量”之间的非线性关系,2026年1月,系统成功预测了一起因焊丝含锰量超标导致的焊缝气孔缺陷,比人工检测提前了4小时,避免了300多台车身的返工。
从“单点突破”到“全链贯通”:机器学习如何重构工业数字孪生的生态?
当机器学习解决了模型精度问题后,数字孪生的价值开始从“局部优化”向“全链协同”延伸,某汽车厂的案例中,最值得关注的是他们构建的“三级数字孪生体系”:设备级孪生体负责实时监控单台设备的状态;产线级孪生体通过机器学习优化工序衔接;工厂级孪生体则整合供应链、物流、能源等数据,实现全局调度。
影视制作与家居装饰热度持续走高,行业关注度持续提升 在设备级,某冲压机的数字孪生体通过振动传感器和电流传感器数据,结合机器学习模型,提前72小时预测模具磨损,将模具更换周期从“固定时长”改为“按需更换”,使模具寿命提升了20%,2026年3月,系统成功避免了一起因模具突发断裂导致的产线停机事故,直接减少损失超50万元。

在产线级,焊装车间的数字孪生体通过分析200多台机器人的运行数据,发现某型号机器人在焊接特定位置时,送丝速度与焊接电流的匹配存在0.2秒的延迟,机器学习模型自动生成了优化后的控制参数,使该工位的焊接效率提升了12%,年节约电费超30万元。
在工厂级,数字孪生系统整合了ERP、MES、SCM等系统的数据,通过机器学习预测未来7天的订单需求、设备故障、物料短缺风险,2026年5月,系统提前3天预警某批次车身涂料的供应短缺,采购部门及时调整供应商,避免了2000台车身因涂料不足导致的生产停滞。 2026年碳中和与教育公益及音乐产业热度持续上升,相关领域迎来新发展
数据治理:机器学习背后的“隐形战场”
机器学习让数字孪生“活”了起来,但要让这个“活体”持续进化,数据治理是绕不开的坎,某汽车厂的实践中,数据团队花了整整一年时间解决三个核心问题:数据质量、数据标签、数据安全。
“工业数据就像未经提炼的矿石,90%是噪声。”数据团队负责人王工说,他们遇到的典型问题包括:传感器故障导致的数据缺失、不同设备数据格式不统一、人工记录的数据存在主观误差,为此,团队开发了一套“数据清洗流水线”:先用统计方法剔除异常值,再用机器学习模型填补缺失数据(比如用相邻时间点的数据预测缺失值),最后通过人工抽检确保数据质量,2026年2月,这套系统成功识别并修正了某台机器人因传感器故障导致的3000条错误数据,避免了模型被“带偏”。

数据标签是另一个挑战,要让机器学习模型理解“当前数据对应哪种工况”,需要大量标注数据,某汽车厂的解决方案是“半自动标注”:先由工程师标注少量关键数据(模具磨损初期”“模具磨损中期”),再用机器学习模型自动标注剩余数据,最后通过人工复核确保标签准确性,2026年4月,他们完成了10万条焊接数据的标注,为模型训练提供了高质量样本。
数据安全则是底线,某汽车厂的数字孪生系统涉及设备状态、工艺参数、订单信息等敏感数据,团队采用了“联邦学习+区块链”的技术方案:数据在本地设备加密处理,模型训练时只上传加密后的参数,训练结果通过区块链存证,确保数据“可用不可见”,2026年6月,这套方案通过了某国际安全认证机构的审核,成为行业标杆。
组织变革:从“技术驱动”到“业务驱动”的最后一公里
技术突破和数据治理只是基础,真正让数字孪生落地的是组织变革,某汽车厂的实践中,最关键的一步是成立了“数字孪生推进办公室”,由生产副总直接领导,成员包括IT、工艺、设备、质量等部门的骨干,这个办公室的职责不是“建系统”,而是“改流程”——把数字孪生从“技术工具”变成“业务语言”。
2026年数字鸿沟与绿色转化及内容审核热度持续攀升,相关应用不断深化 过去设备维护是“故障后维修”,现在通过数字孪生预测故障,维护部门需要重新制定排班计划;过去工艺调整依赖工程师经验,现在机器学习模型会给出优化建议,工艺部门需要学习如何解读模型输出;过去生产计划是“静态排产”,现在数字孪生系统会实时更新设备状态、物料库存,计划部门需要适应“动态调度”。
“最难的不是技术,是改变人的习惯。”李工感慨,他们花了半年时间培训一线员工:设备操作工需要学会查看数字孪生系统的预警信息;质检员需要理解机器学习模型如何预测缺陷;甚至厂长也需要通过数字孪生看板实时掌握产线状态,2026年7月,某车型的产线换型时间从4小时缩短至1.5小时,其中80%的效率提升来自员工对数字孪生工具的熟练运用。
未来已来:当数字孪生遇见生成式AI
站在2026年的节点回望,某汽车厂的实践证明:机器学习不是数字 2026年绿色产业链与绿色消费圈及绿色森林保护热度持续攀升,相关领域迎来新突破