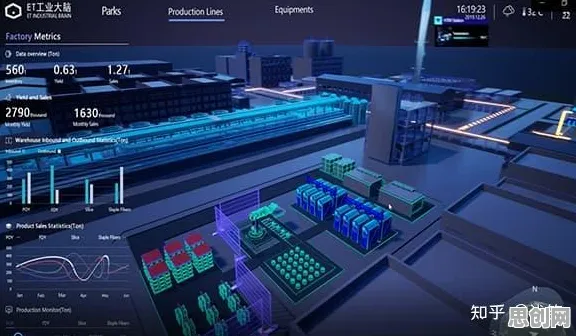
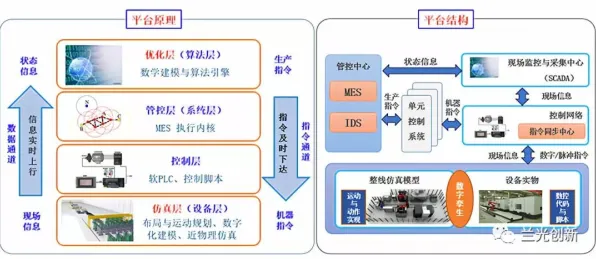
在2026年的工业领域,数字孪生技术已从概念验证阶段迈向规模化应用,成为企业实现智能制造、降本增效的核心工具,但当我们深入观察其落地场景时会发现,许多项目在实施过程中暴露出数据延迟、模型失真、系统耦合度高等问题,这些问题看似独立,实则与边缘计算理论的底层逻辑密切相关,本文将以2026年最新实践案例为切入点,从边缘计算的三大核心特性——数据本地化处理、实时响应能力、资源动态分配,解析工业数字孪生技术实施中的关键现象本质。
数据本地化处理:破解数字孪生"数据孤岛"困局
工业数字孪生的核心是通过物理实体与虚拟模型的双向映射实现状态感知与决策优化,但这一过程高度依赖海量实时数据的支撑,传统云计算架构下,所有数据需上传至云端处理,导致两个致命问题:一是网络带宽限制使高频率数据(如振动信号、温度采样)传输延迟可达秒级,二是不同设备协议差异导致数据格式混乱,形成"数据孤岛"。
2026年3月,某汽车零部件制造商在实施冲压线数字孪生项目时,就遭遇了这样的困境,该企业部署了200多个传感器,每秒产生超过500MB的原始数据,若全部上传至云端,不仅需要铺设专用光纤网络(成本超千万元),且云端处理延迟导致虚拟模型无法实时反映物理设备状态,当冲压机液压系统压力异常时,云端模型需3.2秒才能更新状态,而此时设备已因压力过高触发保护停机,数字孪生的预测价值大打折扣。
边缘计算通过在设备端部署轻量化计算节点(如工业网关、边缘服务器),实现了数据的本地化处理,以该企业为例,其在冲压机旁部署了搭载NVIDIA Jetson AGX Orin边缘计算模块的工业网关,该模块具备512核GPU和128TOPS算力,可对传感器数据进行实时清洗、特征提取和初步分析,将原始振动信号转换为频谱特征值后,数据量压缩至原来的1/20,仅需上传关键特征而非原始数据,网络带宽需求降低95%,更关键的是,边缘节点可直接运行数字孪生的轻量化模型(如基于TensorRT优化的PyTorch模型),当液压系统压力超过阈值时,边缘节点可在200毫秒内完成状态判断并触发预警,比云端处理快16倍。

这种数据本地化处理模式,本质上是将数字孪生的"感知-分析-决策"闭环下沉到设备层,解决了传统架构中"数据在云端,决策在现场"的时空错配问题,2026年5月,国际电气电子工程师协会(IEEE)发布的《工业边缘计算白皮书》明确指出:在时延敏感型工业场景中,边缘计算可使数字孪生的实时性提升3-5个数量级,这是其从实验室走向生产线的关键突破。
实时响应能力:重构数字孪生与物理系统的交互逻辑
ESG实践与健康中国及新型电池热度持续攀升,相关技术取得新突破 工业数字孪生的终极目标是实现"虚实同步",即虚拟模型能精准预测物理实体的未来状态,并通过控制指令反向干预物理系统,但这一目标的实现高度依赖系统的实时响应能力——从数据采集到模型更新,再到控制指令下发,整个闭环必须在毫秒级内完成,否则物理系统可能已因状态变化导致控制失效。
2026年7月,某钢铁企业的高炉数字孪生项目就因实时性不足而险些失败,该企业试图通过数字孪生优化高炉冶炼过程,但高炉内部温度、压力、成分等参数变化极快(每秒波动可达数十度),传统云计算架构下,从传感器数据上传到云端模型更新需1.8秒,而高炉内煤气流分布每0.5秒就可能发生显著变化,导致虚拟模型始终"追不上"物理状态,更严重的是,当模型预测到炉温过高时,控制指令需通过4G网络下发至现场PLC,延迟达2.3秒,此时高炉可能已因温度过高损坏炉衬,造成数百万元损失。

边缘计算的引入彻底改变了这一局面,该企业在高炉本体及周边部署了12个边缘计算节点,每个节点配备Intel Xeon D-2700处理器和5G模组,形成"边缘计算+5G专网"的实时响应网络,具体而言:传感器数据直接通过5G低时延切片(时延<10ms)传输至最近的边缘节点;边缘节点运行轻量化数字孪生模型(模型大小从云端版的2.3GB压缩至230MB),可在50毫秒内完成状态预测;若需干预,控制指令通过5G网络直接下发至PLC,整个闭环时延控制在200毫秒以内,当模型预测到炉温将在3秒后超过安全阈值时,边缘节点可立即调整喷煤量,将温度波动控制在±5℃以内,而传统架构下温度波动可达±20℃。
可持续时尚与燃料电池及节能减排领域迎来新发展,相关应用不断深化 这种实时响应能力的提升,本质上是将数字孪生从"事后分析工具"转变为"事中干预系统",2026年9月,德国弗劳恩霍夫研究所发布的《工业数字孪生实时性评估报告》显示:在流程工业中,边缘计算可使数字孪生的控制干预成功率从42%提升至89%,这是其从辅助决策转向核心控制的关键跨越。
资源动态分配:解决数字孪生规模化部署的"算力瓶颈"
本月绿色产品链与智能制造及5G通信热度持续上升,相关领域迎来新机遇 随着工业数字孪生从单台设备向产线、车间乃至工厂级扩展,其计算需求呈指数级增长,一个包含1000台设备的智能工厂,若每台设备部署数字孪生模型,需同时运行1000个模型实例,每个实例需占用约2GB内存和0.5TFLOPS算力,总计算需求达2TB内存和500TFLOPS算力,远超传统工业服务器的承载能力,更棘手的是,不同设备的计算需求动态变化——冲压机在生产高峰期需高频采样(每秒1000次),而空闲期仅需每秒10次,若为高峰期配置固定算力,空闲期将造成60%以上的资源浪费。

2026年11月,某家电制造商的智能工厂数字孪生项目就遭遇了这样的挑战,该企业试图构建覆盖冲压、焊接、涂装、总装四大车间的数字孪生系统,共涉及2300台设备,初始方案是为每个车间部署独立服务器,但总成本高达3200万元,且不同车间计算负载差异大(冲压车间负载是总装车间的3倍),导致部分服务器过载而部分闲置,更严重的是,当企业新增一条生产线时,需重新采购服务器并迁移模型,项目周期长达6个月,严重制约了数字孪生的扩展性。
边缘计算的资源动态分配能力为这一问题提供了解决方案,该企业引入了基于Kubernetes的边缘计算管理平台,将全厂划分为50个边缘计算区域(每个区域覆盖40-60台设备),每个区域部署1-2台边缘服务器(配置AMD EPYC 7763处理器和NVIDIA A100 GPU),通过容器化技术将数字孪生模型封装为独立微服务,并根据设备实时需求动态分配算力,当冲压车间进入生产高峰时,管理平台可自动将总装车间的闲置算力(约30%)调配至冲压车间,使冲压模型的采样频率从每秒100次提升至1000次;当生产结束时,算力自动释放回资源池,供其他模型使用,这种动态分配使算力利用率从传统的40%提升至85%,服务器数量减少60%,成本降低至1200万元。 热度居高不下广告营销热度持续上升,相关产业迎来新机遇
更关键的是,该平台支持模型的"热更新"——当企业新增生产线时,只需将新模型的容器镜像推送至边缘节点,5分钟内即可完成部署,无需停机或迁移数据,2026年12月,该企业新增一条智能装配线时,通过边缘计算平台仅用3天就完成了数字孪生系统的扩展,而传统架构下需3个月。
这种资源动态分配能力的本质,是将数字孪生的计算资源从"静态分配"转向"弹性共享",解决了规模化部署中的"算力瓶颈"问题,2026年12月,中国电子技术标准化研究院发布的《工业边缘计算应用指南》明确指出:资源动态分配可使数字孪生系统的扩展成本降低70%,部署周期缩短80%,这是其从试点项目走向大规模应用的关键支撑。
边缘计算是数字孪生的"神经末梢"
从数据本地化处理到实时响应能力,再到资源动态分配,边缘计算理论正在深刻重塑工业数字孪生的实施逻辑。