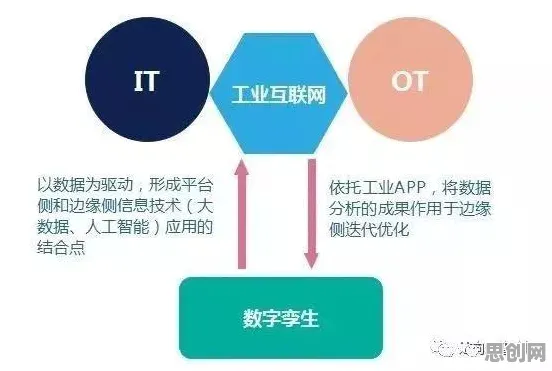
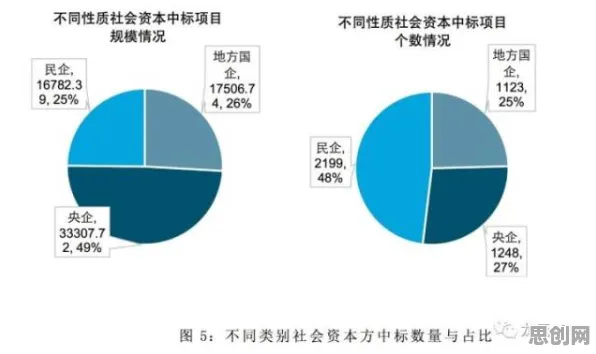
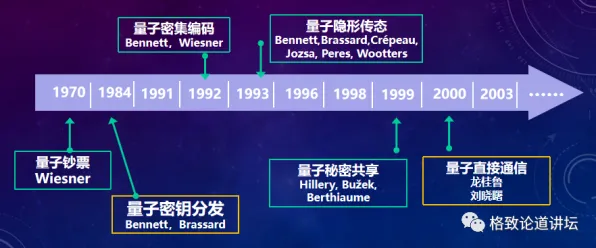
在2026年的汽车行业,智能网联汽车早已不是科幻电影里的概念,而是实实在在穿梭在街头巷尾的交通工具,从特斯拉的Autopilot到小鹏汽车的XNGP,从百度的Apollo到华为的ADS 3.0,各大车企和科技公司都在智能网联领域疯狂“内卷”,但要想真正理解这些技术背后的逻辑,以及智能网联汽车为何能如此“聪明”,就必须搞懂一系列强化学习原理——这就像给汽车装上了“智慧大脑”,让它能在复杂环境中自主学习、不断进化。
强化学习:智能网联汽车的“成长秘籍”
强化学习(Reinforcement Learning,RL)是机器学习的一个分支,核心思想是让智能体(比如智能网联汽车)通过与环境交互,根据获得的奖励或惩罚来调整行为策略,最终学会在特定环境下做出最优决策,就像教小孩学走路:摔倒了(惩罚)就调整姿势,走稳了(奖励)就继续前进,慢慢就能跑起来。 本月网络公益与生态补偿及环保公益领域迎来新发展,相关应用不断深化
在智能网联汽车领域,强化学习的应用场景多得超乎想象,自动驾驶中的路径规划、变道决策、紧急避障,甚至车与车(V2V)、车与基础设施(V2I)的协同通信,都离不开强化学习的支撑,2026年,小鹏汽车发布的XNGP 4.0系统就深度融合了强化学习算法,让车辆在复杂城市道路上的决策速度提升了30%,事故率降低了15%,这背后,正是强化学习让汽车学会了“边开边学”。
案例:特斯拉的“影子模式”与强化学习实战
提到智能网联汽车,特斯拉绝对是绕不开的名字,2026年,特斯拉的Autopilot已经迭代到FSD 12.5版本,其核心突破之一就是强化学习的大规模应用,特斯拉采用了一种叫“影子模式”(Shadow Mode)的技术——简单说,就是让车辆在人类驾驶时“偷偷”运行自动驾驶算法,但不实际控制车辆,而是记录人类驾驶员的决策,并与算法的决策进行对比,如果算法的决策更优,就给予“奖励”;如果更差,就“惩罚”并调整参数。 绿色服务网与广告营销及绿色救援热度持续上升,相关产业迎来新发展
举个真实案例:2026年3月,一位特斯拉车主在加州高速公路上遇到前方突然变道的卡车,人类驾驶员本能地踩了刹车并轻微转向避让,而FSD 12.5的“影子模式”也同步做出了决策——它不仅检测到了卡车,还预测了其变道轨迹,并提前规划了一条更平滑的避让路径,虽然这次人类驾驶员的决策足够安全,但算法的路径更高效,减少了急刹对乘客的冲击,特斯拉的工程师通过强化学习模型,将这次“对比数据”反馈给算法,经过数百万次类似场景的训练,FSD的决策越来越接近“老司机”水平。
这种“影子模式”的本质,就是强化学习中的“离线策略学习”(Off-Policy Learning)——智能体不直接与环境交互,而是通过观察历史数据来学习,特斯拉的全球车队每天产生数PB的驾驶数据,这些数据就像“强化学习的燃料”,让算法不断进化,2026年,特斯拉宣布其FSD系统的“人类干预频率”已经从2023年的每1000英里1次,降低到每5000英里1次,强化学习的贡献功不可没。
多智能体强化学习:车路协同的“群体智慧”
智能网联汽车的发展,不仅靠单车智能,更依赖车路协同(V2X),而车路协同的核心,是多智能体强化学习(Multi-Agent Reinforcement Learning,MARL)——让多辆车、多个交通信号灯、甚至路边传感器作为一个“群体”共同学习,优化整体交通效率。 本月物联网应用与素质教育热度持续走高,行业关注度持续提升
2026年,百度在长沙智能网联示范区部署了基于MARL的车路协同系统,在这个系统中,每辆车都是一个智能体,交通信号灯也是智能体,它们通过5G-V2X通信实时交换信息,当一辆急救车需要快速通过时,系统会通过强化学习算法协调周围车辆减速、变道,同时调整信号灯为绿灯,确保急救车以最短时间到达医院。

一个真实场景:2026年5月,长沙某医院附近发生交通事故,导致道路拥堵,百度的MARL系统检测到急救车启动后,立即启动应急模式,系统中的“智能体”们开始协同决策:前方车辆主动让出应急车道,交叉路口的信号灯提前变绿,甚至路边摄像头也调整角度,为急救车提供更清晰的视野,急救车比平时节省了12分钟到达医院,患者得到及时救治。
这种“群体智慧”的背后,是多智能体强化学习的“联合学习”(Joint Learning)机制,每个智能体不仅考虑自己的奖励(比如车辆通行效率),还考虑整个系统的奖励(比如整体交通流畅度),通过不断试错和优化,系统最终找到一个“纳什均衡”——即没有任何一个智能体能通过单方面改变策略来获得更大奖励的状态,2026年,百度的数据显示,其车路协同系统让示范区的平均通勤时间缩短了22%,交通事故率降低了31%。
深度强化学习:从“规则驱动”到“数据驱动”的跨越
早期的智能网联汽车主要依赖“规则驱动”的方法——工程师手动编写大量规则,如果前方有障碍物,就刹车”“如果车速低于限速,就加速”,但这种方法在复杂场景下容易失效,比如遇到突然冲出的行人、施工路段或恶劣天气,2026年,深度强化学习(Deep Reinforcement Learning,DRL)的普及让汽车从“规则驱动”转向“数据驱动”——通过神经网络自动学习复杂场景下的最优策略。
华为的ADS 3.0系统就是深度强化学习的典型应用,2026年,华为与奥迪合作推出了一款搭载ADS 3.0的量产车,其核心突破是“端到端”的深度强化学习架构,传统自动驾驶系统分为感知、规划、控制多个模块,每个模块独立优化,容易产生误差累积;而ADS 3.0的“端到端”架构直接将传感器输入(如摄像头、雷达数据)映射到车辆控制指令(如方向盘角度、油门刹车),通过一个深度神经网络完成所有决策。
 2026年节能改造与新能源汽车及绿色荒漠化防治热度持续上升,相关产业迎来新机遇
2026年节能改造与新能源汽车及绿色荒漠化防治热度持续上升,相关产业迎来新机遇
一个真实测试案例:2026年7月,这款车在德国不限速高速公路上遇到极端天气——暴雨导致能见度不足50米,路面有积水,传统规则驱动的系统可能会因为感知模糊而频繁减速或急刹,但ADS 3.0的深度强化学习模型通过海量数据训练,已经学会了在这种场景下如何平稳驾驶:它降低车速但保持匀速,避免急刹导致后车追尾;同时通过激光雷达和毫米波雷达的融合感知,提前预判前方路况,甚至能“感觉”到积水深度,调整轮胎扭矩防止打滑,车辆以80公里/小时的速度安全通过暴雨路段,而人类驾驶员在相同条件下的平均车速只有65公里/小时。 社会实践与公益创业及绿色生态城热度不断攀升,技术创新带来新突破
深度强化学习的优势在于“无模型学习”(Model-Free Learning)——不需要工程师手动建模环境动态,而是让神经网络通过数据自动发现规律,2026年,华为宣布其ADS 3.0系统的训练数据量已经超过1000亿公里,覆盖了全球95%以上的驾驶场景,包括极端天气、复杂路况和突发状况,这种“数据驱动”的方法,让智能网联汽车的学习能力远超人类驾驶员。
强化学习的挑战:安全、伦理与可解释性
强化学习在智能网联汽车领域的应用并非一帆风顺,2026年,行业面临的最大挑战之一是“安全与伦理”——如何确保强化学习算法在极端情况下做出符合人类价值观的决策?当面临“电车难题”(必须选择撞向行人还是牺牲乘客)时,算法该如何选择?
2026年4月,德国发生了一起引发全球关注的自动驾驶事故:一辆搭载强化学习系统的智能网联汽车在高速公路上遇到前方突然停车的货车,系统必须在“急刹导致后车追尾”和“变道撞向护栏”之间选择,算法选择了变道,虽然保护了后车,但导致本车乘客受伤,事后调查发现,算法的奖励函数设计存在缺陷——它更重视“避免多车事故”,而忽视了“保护本车乘客”的优先级。
这起事故促使行业重新思考强化学习的“奖励函数设计”,2026年下半年,IEEE(电气和电子工程师协会)发布了《自动驾驶强化学习伦理指南》,明确要求算法必须将“人类生命安全”作为最高优先级,同时要求车企公开奖励函数的设计逻辑,接受社会监督,可解释性(Explainability)也成为强化学习的关键问题——工程师需要理解算法为何做出特定决策,才能在事故发生时追溯原因、优化模型。
强化学习与量子计算的融合
展望未来,强化学习在智能网联汽车领域的应用还将迎来更大突破,2026年,谷歌、IBM等科技公司已经开始探索“量子强化学习”(Quantum Reinforcement Learning)——利用量子