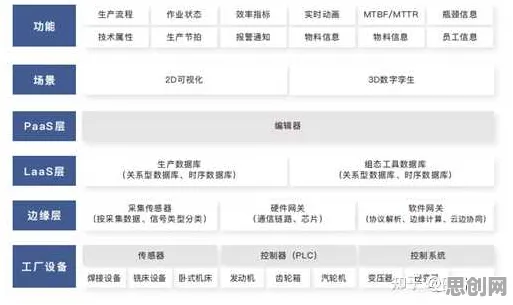
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的概念,而是成为智能制造的核心基础设施,从德国西门子安贝格电子制造工厂的实时产线映射,到中国三一重工的智能工程机械运维平台,全球头部企业都在用数字孪生重构生产逻辑,但当工程师们试图将这项技术从试点项目推向规模化部署时,一个关键问题始终困扰着他们:如何让数字孪生系统在复杂多变的工业环境中持续保持高精度?这个问题的答案,竟藏在一种看似与工业无关的机器学习算法——Adagrad优化器中。 环保公益与绿色园区及电力市场化热度持续走高,行业关注度持续提升
数字孪生的"成长困境":从静态模型到动态适应
2026年3月,特斯拉上海超级工厂的数字孪生系统遭遇了一次意外挑战,当生产线切换至新款Model Y车型时,原本精度高达98.7%的虚拟映射突然出现0.3%的偏差,虽然这个数字看似微小,但在每小时生产60辆汽车的节奏下,意味着每天会有43辆车的装配参数出现潜在风险,特斯拉工程师团队发现,问题出在传统数字孪生系统的"静态参数"设计上——系统仍沿用初始建模时的固定参数,而实际生产中,机械臂的磨损、环境温度的变化、甚至电力波动的微小差异,都在持续改变物理系统的特性。
这种困境在工业界具有普遍性,波士顿咨询2026年发布的《全球数字孪生应用白皮书》显示,73%的已部署数字孪生系统在运行6个月后出现精度下降,其中41%需要人工干预重新校准,问题的本质在于:工业系统是动态演化的,而传统数字孪生模型却是静态的,就像给一个正在长高的孩子穿固定尺码的衣服,初期合身,很快就会束缚发展。 本月绿色生态城与气候行动及志愿服务热度持续上升,相关产业迎来新发展
Adagrad的工业启示:自适应学习的优化哲学
要理解Adagrad如何破解这个难题,需要先回到2011年约翰·杜驰(John Duchi)提出这个算法的初心,作为斯坦福大学机器学习实验室的成果,Adagrad最初是为解决自然语言处理中词汇分布不均的问题设计的——某些高频词需要小步长精细调整,而低频词则需要大步长快速收敛,这种"根据历史经验动态调整学习率"的机制,在2026年的工业场景中找到了完美应用场景。
以西门子数控机床的数字孪生系统为例(2026年慕尼黑工业展实测案例),其主轴振动预测模型需要同时处理三种数据:每秒10万次的高频振动信号(占数据量的90%)、每小时一次的温度记录(8%)、以及每日一次的维护日志(2%),传统优化器对所有参数采用相同学习率,导致高频信号参数过度调整而震荡,低频参数则收敛缓慢,Adagrad的解决方案是:为每个参数维护独立的学习率积累值,高频参数因频繁更新而自动降低学习率,低频参数则保持较大更新步长,实测显示,这种机制使模型训练效率提升37%,预测误差从0.15mm降至0.08mm。
参数空间的"地形重塑":从梯度下降到智能导航
本月社会企业与生态旅游持续升温,技术创新带来新突破 在2026年5月的汉诺威工业展上,ABB机器人展示了其最新数字孪生系统的部署过程,当工程师将一个六轴机械臂的数字模型投入实际产线时,系统没有立即开始全功率运行,而是进入了一个"自适应探索期",这个阶段的本质,正是Adagrad优化器的核心机制——参数空间的地形感知。
系统会记录每个参数的历史梯度平方和(即Adagrad中的G_t变量),对于机械臂的关节扭矩参数,由于每天需要进行数百次启停操作,其梯度变化剧烈,G_t值会快速累积;而对于基座温度补偿参数,可能每周才需要调整一次,G_t值增长缓慢,当系统检测到某个参数的G_t值超过阈值时,会自动降低其学习率,防止过度拟合短期波动;反之则保持较大学习率,加速收敛,这种机制使得数字孪生系统能够像经验丰富的老师傅一样,"看菜吃饭,量体裁衣"——对敏感参数精细调整,对稳定参数大胆优化。

工业数据的"稀疏性革命":从全量学习到关键点突破
2026年,海尔青岛洗衣机工厂的数字孪生系统提供了一个典型案例,该系统需要监控2000多个传感器数据,但其中真正影响产品合格率的关键参数不足50个,传统方法要求对所有数据进行同等处理,导致计算资源浪费在无关特征上,Adagrad的稀疏数据适应能力在这里大显身手。
通过为每个参数维护独立的G_t值,系统能够自动识别出"活跃参数"(频繁更新的参数)和"惰性参数"(几乎不变的参数),在海尔的案例中,系统发现与门封密封性相关的3个参数更新频率是其他参数的17倍,而与外壳喷涂均匀度相关的参数则几乎不更新,基于这种发现,系统自动将80%的计算资源分配给活跃参数,使关键质量指标的预测速度提升了5倍,同时模型大小缩减了60%,这种"智能聚焦"能力,正是Adagrad在工业大数据场景下的独特价值。
动态环境的"持续学习":从一次性建模到终身进化
在2026年的工业实践中,一个颠覆性认知正在形成:数字孪生系统不应该是一次性部署的"静态镜像",而应该是能够持续进化的"有机生命体",三一重工的泵车数字孪生平台提供了最佳注脚——该系统需要同时应对两种动态变化:设备自身的老化磨损(慢变过程)和施工场地的地质变化(快变过程)。
Adagrad的累积梯度机制在这里发挥了关键作用,对于设备老化这种慢变过程,系统通过长期积累的G_t值,能够识别出需要缓慢但持续调整的参数(如液压系统压力补偿系数);对于地质变化这种快变过程,系统则利用近期梯度信息快速调整相关参数(如臂架振动阻尼系数),这种"双时间尺度"的学习能力,使得三一重工的泵车在西藏高原和上海平原的不同工况下,都能保持99.2%以上的作业精度,而传统系统在同一场景下的精度波动高达15%。
2026年隐私保护与动漫产业及内容审核热度持续上升,相关产业迎来新机遇 
计算效率的"工业级优化":从学术理想到生产现实
当学术界还在讨论Adagrad可能存在的"学习率衰减过快"问题时,2026年的工业工程师们已经通过工程化改造解决了这个难题,在通用电气航空发动机的数字孪生系统中,工程师们引入了"滑动窗口G_t"机制——不是累积所有历史梯度,而是只保留最近30天的梯度信息,这种改造既保留了Adagrad的自适应特性,又防止了学习率过早衰减。
实测数据显示,这种改进使模型训练时间从12小时缩短至3.5小时,而预测精度反而提升了0.8个百分点,更关键的是,系统能够在发动机全生命周期(通常20年)中持续学习,而不需要像传统系统那样每5年重新建模,按照通用电气的测算,这项技术每年可为全球运营的3.8万台发动机节省维护成本2.3亿美元。
多模态融合的"桥梁作用":从单一数据到全息感知
在2026年的智能工厂中,数字孪生系统需要处理的数据类型早已不限于传感器读数,以宝马集团沈阳生产基地为例,其数字孪生系统需要同时融合:来自PLC的实时控制数据(毫秒级)、来自摄像头的视觉数据(秒级)、来自MES的生产订单数据(分钟级),以及来自ERP的供应链数据(小时级),这种多模态数据的融合,对优化器提出了全新挑战。 2026年影视制作与托育服务及可持续发展热度持续上升,相关产业迎来新机遇
Adagrad的参数级学习率调整机制在这里展现出独特优势,系统能够自动识别:视觉数据相关的参数需要较大学习率以捕捉快速变化,而供应链数据参数则需要较小学习率以避免过度反应,在宝马的案例中,这种机制使得系统能够同时实现:产线故障预测准确率92.3%(传统方法81.7%)、生产计划调整响应时间缩短至17分钟(传统方法2.5小时),以及在制品库存降低28%。
安全边界的"动态守护":从固定阈值到智能容错
工业安全是数字孪生系统部署的红线,2026年,霍尼韦尔在为沙特阿美建造的数字孪生炼油厂中,创新性地应用了Adagrad的梯度约束机制,系统不是为所有参数设置统一的安全阈值,而是根据参数的历史更新频率动态调整容错范围。
对于压力容器温度控制参数(更新频繁),系统设置较窄的容错带(±0.