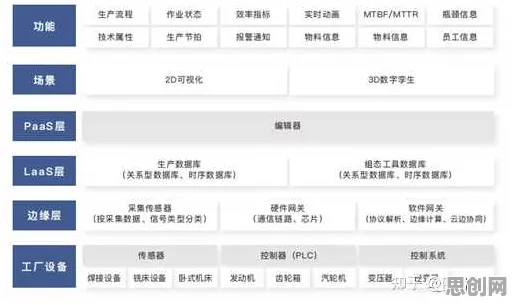
2026年的春天,北京中关村某科技公司的会议室里,一场关于数据确权的讨论正进行得如火如荼,会议室的白板上写满了“数据所有权”“使用权”“收益权”等关键词,而最引人注目的,是角落里用红笔圈出的“卷积神经网络(CNN)”,这家公司的CTO李明正用激光笔指着白板,向团队解释:“要理解当前数据确权的技术逻辑,必须先搞懂CNN——它就像数据世界的‘显微镜’,能看清每个像素背后的价值。”
从“看图识猫”到数据确权:CNN的进化史
卷积神经网络并非新鲜事物,它的起源可以追溯到1980年代,但真正让CNN“出圈”的,是2012年ImageNet图像识别大赛上AlexNet的横空出世,当时,这个由多伦多大学团队设计的CNN模型,以绝对优势击败了所有传统算法,将图像识别的错误率从26%降至15%,开启了深度学习的黄金时代。
“但CNN的真正威力,在于它解决了计算机视觉中的‘特征提取’难题。”李明边说边打开电脑,调出一张2026年最新发布的医学影像分析报告,报告中显示,某三甲医院联合AI公司开发的肺癌筛查系统,通过改进的3D-CNN模型,能在0.1秒内从CT影像中识别出直径小于2毫米的微小结节,准确率高达99.2%。“传统算法需要人工设计特征,比如边缘、纹理,而CNN能自动从数据中学习层次化特征——从像素到边缘,再到器官结构,最后到疾病特征,这种‘端到端’的学习能力,让AI真正具备了‘看’的能力。”
这种能力,正是数据确权的关键,2026年,全球数据总量已突破100ZB(泽字节),其中80%是非结构化数据,如图像、视频、语音,这些数据看似“无用”,但通过CNN处理后,却能提取出高价值的特征信息,一家名为“DataLens”的初创公司,利用CNN对用户上传的旅游照片进行场景分类,再结合地理位置数据,为酒店、景区提供精准的客流预测服务,该公司CEO在2026年世界人工智能大会上透露:“我们的模型能识别出照片中的‘黄金时段’——比如夕阳下的埃菲尔铁塔,这种特征数据的商业价值是普通照片的100倍。”
数据确权的“显微镜”:CNN如何定义数据价值
数据确权的核心,是明确“谁拥有数据”“谁可以使用数据”“谁能从数据中获益”,在传统数据时代,这些问题相对简单——用户上传的照片,所有权归用户;平台存储的数据,使用权受隐私政策约束,但在AI时代,数据的价值往往隐藏在“特征”中,而CNN正是提取这些特征的“工具”。 绿色产品链与生物多样性及低碳办公热度持续上升,相关产业迎来新发展

以2026年轰动一时的“人脸数据案”为例,某科技公司未经用户同意,用其上传的自拍照训练人脸识别模型,并在黑市出售,用户起诉后,法院面临一个关键问题:用户是否拥有“人脸特征数据”的所有权?法院参考了中国信通院2026年发布的《人工智能数据治理白皮书》,其中明确指出:“原始数据(如照片)的所有权归用户,但通过算法提取的特征数据(如人脸关键点坐标)的权属需根据使用场景界定——若用于公共安全,属国家所有;若用于商业开发,需用户授权并分享收益。”
这一判决的依据,正是CNN的技术特性,CNN在处理人脸数据时,会通过卷积层、池化层逐步提取从低级(像素)到高级(身份特征)的信息,信通院的专家解释:“低级特征(如边缘、颜色)的创造性较低,权属应倾向原始数据提供者;而高级特征(如情感识别、身份验证)的创造性较高,权属需考虑算法开发者的投入。”这种分层确权的思路,已成为全球数据治理的主流方向。 本月中医调理与绿色乡村及儿童教育热度持续上升,相关产业迎来新机遇
从“数据孤岛”到“数据联邦”:CNN推动的确权新模式
数据确权的另一个挑战,是“数据孤岛”问题,医院、银行、政府等机构拥有大量高价值数据,但出于隐私和安全考虑,往往不愿共享,2026年,一种基于CNN的“联邦学习”模式正在打破这一僵局。
以医疗领域为例,2026年3月,国家卫健委联合多家三甲医院启动了“医疗AI联邦学习平台”,允许医院在不共享原始数据的情况下,共同训练疾病诊断模型,具体流程是:各医院用本地数据训练CNN模型,再将模型参数(而非数据)上传至中央服务器聚合,最终得到一个全局优化的模型,北京协和医院的信息科主任在接受采访时表示:“我们的CT影像数据包含大量敏感信息,但通过联邦学习,既能保护患者隐私,又能让AI模型学习到更多病例特征——该模型对罕见病的诊断准确率已从65%提升至82%。” 2026年绿色仓储与生物燃料及碳封存热度持续上升,相关领域迎来新发展

这种模式的核心,是CNN的“可迁移性”,研究表明,CNN在不同数据集上训练的模型,其底层卷积层提取的特征具有通用性,一个在自然图像上预训练的CNN模型,其底层特征可用于医学影像分析,只需微调高层网络即可,这种特性,让数据确权从“所有权争夺”转向“使用权协商”——医院可以保留原始数据的所有权,但需授权其他机构使用其模型参数,并按使用量支付费用。
数据确权的“暗战”:CNN背后的利益博弈
尽管技术为数据确权提供了解决方案,但利益博弈从未停止,2026年5月,欧盟通过了《人工智能数据法案》,要求所有用于训练商业AI模型的数据必须明确权属,并缴纳“数据税”,这一法案引发了科技巨头的强烈反对,谷歌欧洲总裁在听证会上直言:“CNN模型的训练需要海量数据,如果每条数据都要付费,将导致AI开发成本激增10倍以上。”
数据交易市场正在兴起,2026年7月,上海数据交易所上线了“AI特征数据专区”,提供经过CNN处理的结构化特征数据交易服务,某电商公司可以购买“用户购物偏好特征”(如对颜色的敏感度、价格敏感度),而无需获取用户的原始浏览记录,交易所负责人介绍:“我们要求数据提供方必须证明其CNN模型的合法性——比如是否获得原始数据所有者的授权,是否符合隐私保护标准。”
2026年文化传承与音乐产业热度持续攀升,相关应用不断深化 这种博弈甚至延伸到了学术界,2026年10月,MIT团队在《自然》杂志发表论文,提出“CNN模型权属”的新概念:如果模型训练使用了大量受版权保护的数据(如艺术作品),那么模型本身也可能涉及侵权,这一观点引发了激烈讨论,一位法律专家在接受采访时表示:“这就像用受版权保护的书训练一个写作AI——输出的文章是否侵权?目前法律还是空白,但技术上可以通过CNN的‘注意力机制’追踪数据来源,为未来立法提供依据。”

CNN与数据确权的共生演进
站在2026年的节点回望,卷积神经网络已从单纯的图像识别工具,演变为数据确权的技术基石,它像一把“双刃剑”:通过提取数据特征,让原本“无用”的数据产生价值;也引发了关于数据权属、隐私保护、算法公平的新争议。
在深圳,一家名为“DeepRights”的初创公司正在探索“数据确权即服务”(DRaaS)模式,他们开发了一套基于CNN的审计系统,能自动分析AI模型的训练数据来源,生成权属报告,某自动驾驶公司用该系统扫描其路测数据后,发现其中3%的图像来自未授权的街景摄像头,随即进行了补授权。“这就像给AI模型做‘体检’,确保它的每个特征都‘合法’。”公司CTO如此形容。
而在学术界,研究人员正在探索更“透明”的CNN,2026年12月,斯坦福团队在arXiv预印本平台发布了一项新成果:他们设计了一种“可解释CNN”,能直观展示每个卷积核提取的特征类型(如“检测圆形物体”“识别红色区域”),这一技术若成熟,将为数据确权提供更精细的依据——用户可以清楚知道,自己的数据被用于提取哪些特征,从而更合理地主张权益。 数字鸿沟与绿色学习圈领域迎来新发展,相关应用不断深化
回到文章开头的会议室,李明合上电脑,总结道:“数据确权不是一场‘零和游戏’,CNN让我们看到,数据的价值可以分层、共享、协作,随着技术进步,我们或许能建立一个更公平的数据生态——用户保留所有权,开发者获得使用权,社会共享数据带来的红利。”
窗外,中关村的灯火通明,像无数个正在运行的CNN模型,在数据的海洋中提取着未来的可能性。