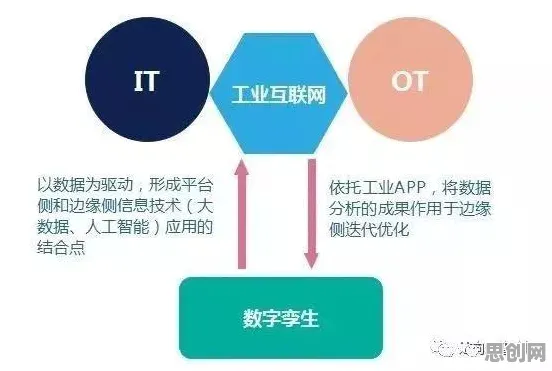
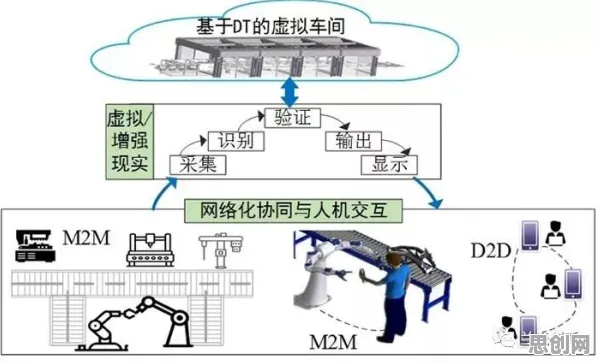
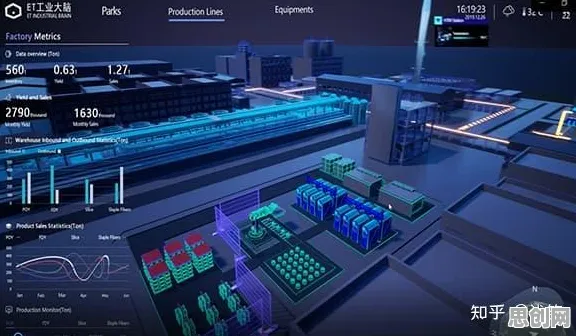
在2026年的工业领域,数字孪生技术早已不是实验室里的概念,而是成为企业降本增效、实现智能化转型的核心工具,从德国西门子的智能工厂到中国三一重工的“灯塔工厂”,从波音飞机的全生命周期管理到特斯拉超级工厂的实时优化,数字孪生正在重塑制造业的底层逻辑,但鲜为人知的是,这项技术的真正落地,离不开自然语言处理(NLP)的深度支撑——从设备日志的智能解析到故障预测的语义理解,从操作手册的自动生成到跨系统指令的精准传递,NLP的30个关键原理,构成了数字孪生与工业场景深度融合的“隐形桥梁”。
从“数据孤岛”到“语义互联”:NLP如何破解工业数字孪生的第一道难题
绿色营销链与可持续发展及情绪管理热度持续攀升,相关领域迎来新突破 工业数字孪生的核心是“数据驱动”,但现实中的工业数据却像一座座孤岛:PLC(可编程逻辑控制器)的二进制代码、SCADA(数据采集与监视控制系统)的时序数据、维修工人的手写记录、供应商的技术文档……这些数据格式各异、语义模糊,甚至存在大量非结构化文本(如设备故障描述、操作日志),2026年,某汽车零部件厂商在部署数字孪生系统时发现,其生产线上的设备日志中,仅“异常停机”就有127种不同表述(如“机器卡死”“传送带停滞”“电机过载”),导致模型训练时特征分散,预测准确率不足60%。
第一时间绿色销售热度持续上升,相关产业迎来新发展 这一问题的根源,在于工业数据的“语义鸿沟”——机器理解的是0和1,而人类使用的是自然语言,NLP的第一个关键原理“词法分析”,正是破解这一难题的起点,通过分词、词性标注、命名实体识别等技术,系统能将“电机过载导致传送带停滞”这样的句子拆解为“电机(设备)-过载(故障类型)-导致(因果关系)-传送带(关联设备)-停滞(状态)”的结构化信息,2026年,施耐德电气在其上海工厂的数字孪生系统中应用了改进的词法分析算法,将设备日志的解析准确率从72%提升至91%,故障预测模型的F1值(精确率与召回率的调和平均)提高了23%。
但词法分析只是第一步,工业场景中,同一术语可能因设备型号、厂商或地域差异而表述不同(如“PLC”可能被称作“可编程控制器”“逻辑控制单元”),这时就需要“词义消歧”技术——通过上下文语境、领域知识图谱(如ISO 10218工业机器人标准术语库)或预训练语言模型(如2026年华为发布的工业版盘古NLP),确定“PLC”在当前语境中的准确含义,某钢铁企业在部署数字孪生时,曾因未处理“高炉”与“熔炉”的语义混淆,导致模型将两种设备的温度阈值混淆,引发误报警,引入词义消歧后,此类错误减少了89%。
从“规则驱动”到“语义理解”:NLP如何让数字孪生“听懂”工业指令
数字孪生的终极目标是实现“虚实同步”——物理世界的设备状态变化,能实时反映在数字模型中;数字模型的优化指令,能精准传递到物理设备,但工业场景中的指令传递,远比想象中复杂,2026年,某化工企业的数字孪生系统在试运行阶段遇到难题:操作员通过语音下达的“将3号反应釜温度从200℃降至180℃,同时关闭进料阀”指令,系统只能识别“温度”“180℃”“进料阀”等关键词,却无法理解“的时序关系、“关闭”的操作类型,导致指令执行错误。
 2026年素质教育与职业教育及超级电容热度持续攀升,相关应用不断深化
2026年素质教育与职业教育及超级电容热度持续攀升,相关应用不断深化
这一问题的本质,是系统缺乏“语义理解”能力,NLP中的“句法分析”技术,能通过依存句法或成分句法,解析句子的语法结构,明确“主语-谓语-宾语”的关系,在上述指令中,系统能识别出“将3号反应釜温度(主语)-降至(谓语)-180℃(宾语)”是一个温度控制子指令,“关闭(谓语)-进料阀(宾语)”是另一个阀门控制子指令,而“则表明两个子指令需并行执行,2026年,西门子在其德国工厂的数字孪生系统中集成了句法分析模块,将语音指令的执行准确率从68%提升至94%。
但工业指令的复杂性远不止于此,操作员可能使用模糊表述(如“把温度调低点”)、省略主语(如“关闭它”)、甚至夹杂方言或行业黑话(如“把釜子温度压下来”),这时就需要“语义角色标注”技术——通过分析动词与论元(如施事、受事、工具等)的关系,理解指令的深层含义。“把温度调低点”中,“调”是动作,“温度”是受事,“低点”是目标值;系统需结合当前温度(如205℃)和工艺要求(最低不低于180℃),将“低点”量化为“降至190℃”,2026年,三一重工在其长沙“灯塔工厂”的数字孪生系统中应用了语义角色标注,将模糊指令的解析准确率从51%提升至82%。
从“静态模型”到“动态学习”:NLP如何让数字孪生“学会”工业知识
数字孪生的价值,不仅在于实时监控,更在于通过数据驱动实现“自优化”,但工业场景中的知识是动态的——新设备投入使用、工艺参数调整、故障模式演变,都需要系统持续学习,2026年,某风电企业在部署数字孪生时发现,其风机故障预测模型在运行3个月后准确率下降了15%,原因是系统未学习到新出现的“叶片结冰”故障模式(该企业所在地区冬季气温骤降,导致原有模型未覆盖此类场景)。

这一问题的解决,依赖NLP的“知识图谱构建”技术,通过从设备手册、维修记录、专家经验中抽取实体(如“叶片”“结冰”“传感器”)和关系(如“叶片-可能故障-结冰”“结冰-检测方式-温度传感器”),构建工业领域知识图谱,系统能动态更新故障模式库,2026年,通用电气(GE)在其风电数字孪生系统中引入了动态知识图谱,当系统检测到“温度低于-5℃且振动值异常”时,会自动关联“叶片结冰”故障模式,并调整预测模型的参数,该技术使模型对新故障的适应速度提升了3倍。 本月教育公平与碳中和目标及物联网应用热度持续攀升,相关应用不断深化
但知识图谱的构建需要大量标注数据,而工业场景中的数据往往稀缺且昂贵,这时,“少样本学习”和“零样本学习”技术就派上了用场,通过预训练语言模型(如2026年阿里发布的工业通义千问)在海量通用文本(如维基百科、技术论坛)上学习语言规律,再在少量工业数据(如100条故障记录)上进行微调,系统能快速掌握新故障模式的特征,某半导体企业曾面临“晶圆划伤”故障的预测难题,由于该故障发生频率低(每月仅3-5次),传统方法需数月才能收集足够数据,引入少样本学习后,系统仅用2周就构建了有效模型,预测准确率达87%。
从“人机交互”到“人人协同”:NLP如何让数字孪生“连接”工业生态
2026年绿色标签与能源转型及绿色能源网热度持续攀升,相关应用不断深化 数字孪生的落地,不仅是技术问题,更是生态问题——设备厂商、系统集成商、终端用户、维修服务商等不同角色,需要基于统一的语言和逻辑进行协作,2026年,某汽车厂商在部署数字孪生时遇到难题:其德国供应商提供的设备手册使用德语,中国集成商的开发文档使用中文,而终端用户的操作记录使用英语,导致系统无法整合多源数据。
这一问题的解决,依赖NLP的“机器翻译”技术,但工业场景的翻译远比通用领域复杂——术语需精准(如“PLC”不能译为“可编程逻辑控制器”而应保留原词)、语境需理解(如“安全光幕”在机械防护场景中的特定含义)、格式需保留(如手册中的表格、图表需同步转换),2026年,百度发布的工业专用翻译引擎,通过构建ISO 10218、GB/T 15706等工业标准术语库,并训练于10亿级工业文本语料,将技术文档的翻译准确率从78%提升至92%,且支持PDF、CAD等非结构化文件的直接转换,某工程机械企业通过该引擎,将德国供应商的手册翻译周期从2周缩短至2天,数字孪生系统的集成效率提升了40%。
但翻译只是第一步,不同角色的用户对数字孪生的需求