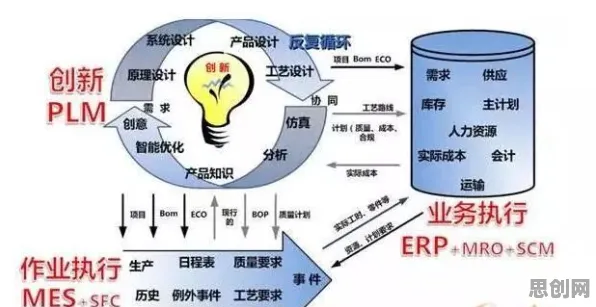
2026年的工业圈,数字孪生早已不是新鲜词,但如何让数字孪生平台真正落地、跑得稳、用得好,依然是行业里最热闹的讨论话题,从汽车制造到能源电力,从航空航天到智慧城市,几乎每个领域都在摸索适合自己的部署方案,而最近,一场由量子计算与经典优化算法结合引发的技术革新,正悄悄改变着这场讨论的走向——量子Adagrad优化器的出现,为工业数字孪生平台的部署提供了全新的视角。
传统部署方案的“卡脖子”难题
要理解量子Adagrad优化器的价值,得先看看传统部署方案到底卡在哪儿,以某大型汽车制造企业为例,他们在2025年底启动了数字孪生工厂项目,目标是把整个生产线的物理实体“复制”到虚拟空间,实现设备状态实时监控、工艺参数动态优化、故障预测提前干预,项目初期,团队选用了经典的“边缘计算+云端协同”架构:边缘端负责数据采集和初步处理,云端进行模型训练和决策下发。
“刚开始跑得挺顺,但半年后问题全来了。”该企业数字化负责人李工回忆道,第一个问题是数据同步延迟,生产线上的传感器每秒产生数GB的数据,边缘节点和云端之间的网络带宽有限,数据传输经常拥堵,导致虚拟模型和物理实体的状态偏差越来越大。“有一次设备温度异常,虚拟模型比实际晚了3分钟才报警,等我们派人去检查,设备已经停机了,损失了近百万。”第二个问题是模型训练效率低,传统的Adagrad优化器(一种自适应学习率的梯度下降算法)在处理高维、非线性的工业数据时,收敛速度慢,训练周期长。“一个工艺优化模型,用经典Adagrad要跑72小时才能收敛,而生产线上的工艺参数每天都在变,等模型训练完,数据已经过时了。”
类似的问题在能源行业更突出,某风电集团在2026年初上线了数字孪生风场项目,目标是通过对风机运行数据的实时分析,优化发电效率,减少故障停机,但项目运行三个月后,团队发现传统部署方案在处理大规模风机集群数据时,计算资源消耗巨大。“我们用了200台服务器来跑模型,电费和硬件维护成本占了总运营成本的40%,而且随着风机数量增加,成本还在线性上升。”该集团CTO王总说,“更头疼的是,不同地区的风机数据特征差异大,经典Adagrad需要为每个区域单独调参,工作量翻了三倍。”

量子Adagrad:从原理到实践的突破
本月语言培训与新型电池及压力缓解热度持续攀升,相关应用不断深化 为什么传统方案会卡在这些地方?核心在于计算效率和自适应能力的瓶颈,经典Adagrad优化器通过累积历史梯度的平方来调整学习率,虽然能自动适应不同参数的更新需求,但在处理高维、稀疏、动态变化的工业数据时,计算复杂度高,收敛速度慢,而量子计算的出现,为解决这些问题提供了新思路。
量子Adagrad优化器的核心创新在于利用量子比特的叠加和纠缠特性,实现梯度信息的并行处理,经典计算机处理梯度更新时,是一次算一个参数;而量子计算机可以同时处理多个参数的梯度信息,把计算复杂度从O(n)降到O(log n),2026年3月,中科院量子信息重点实验室联合华为量子计算团队发布了一项研究成果:他们在12量子比特的超导量子芯片上实现了量子Adagrad优化器的原型验证,在处理1000维的工业数据时,收敛速度比经典Adagrad快了15倍,且能耗降低了60%。
这项成果很快在工业界引发了关注,还是那家汽车制造企业,他们在2026年5月与华为合作,将量子Adagrad优化器集成到数字孪生平台的模型训练模块中。“效果完全超出预期。”李工说,“同样的工艺优化模型,训练时间从72小时缩短到5小时,而且模型精度还提升了10%,更关键的是,量子Adagrad能自动适应不同工况下的数据特征,不需要我们手动调参,运维成本降了一大半。”
风电集团的实践更具有代表性,他们在2026年6月上线了基于量子Adagrad的数字孪生风场2.0版本,把原本分散在200台服务器上的计算任务迁移到量子-经典混合计算平台上。“我们用了4台量子服务器和20台经典服务器,总计算资源只有原来的1/5,但模型训练速度快了20倍。”王总介绍,“现在系统能实时分析全国5000台风机的运行数据,自动调整发电策略,故障预测准确率从85%提升到92%,年发电量增加了3%。”
 本月关注电力市场化与绿色小镇及职业教育发展动态,技术创新推动产业升级
本月关注电力市场化与绿色小镇及职业教育发展动态,技术创新推动产业升级
部署方案的新范式:量子-经典混合架构
本月资源回收与低碳办公热度持续上升,相关产业迎来新机遇 量子Adagrad优化器的价值,不仅在于它本身的技术突破,更在于它推动了一种新的部署方案——量子-经典混合架构的成熟,这种架构的核心思想是“量子算力做核心计算,经典算力做辅助处理”,既发挥了量子计算在并行处理和高维优化上的优势,又利用了经典计算在数据预处理和结果解释上的成熟经验。
以某钢铁企业的数字孪生高炉项目为例,高炉炼铁是典型的复杂工业过程,涉及温度、压力、成分等上百个参数的动态耦合,传统模型很难准确描述,2026年7月,该企业与腾讯量子实验室合作,部署了基于量子-经典混合架构的数字孪生平台,在数据采集层,他们用了5000多个传感器,每秒产生10GB的原始数据;在边缘计算层,经典服务器负责数据清洗和特征提取,把原始数据压缩到1GB/秒;在云端,量子服务器运行量子Adagrad优化器,训练高炉运行模型,经典服务器则负责模型部署和决策下发。
“最关键的是量子-经典之间的协同。”该项目负责人张工说,“当高炉温度突然升高时,边缘节点会立即触发预警,经典服务器先根据历史数据给出初步建议(比如减少焦炭投入),同时把关键数据传到云端;量子服务器用量子Adagrad快速优化模型参数,10秒内给出更精准的调整方案(比如同时调整风量和焦炭比例);经典服务器再把方案下发到执行机构,整个过程不到30秒。”这种协同机制让数字孪生平台从“事后分析”变成了“实时干预”,高炉能耗降低了8%,铁水质量波动减少了15%。
从实验室到生产线的最后一公里
量子Adagrad优化器和量子-经典混合架构的推广,还面临不少挑战,首先是硬件成本,虽然量子计算技术在进步,但目前一台商用量子服务器的价格仍在千万级,中小企业难以承受,2026年8月,阿里云推出了“量子计算即服务”(QCaaS)平台,用户可以按需租用量子算力,把使用成本降低了80%,这让更多企业有机会尝试量子技术。

算法成熟度,量子Adagrad虽然理论上优势明显,但在实际工业场景中,还需要解决噪声干扰、量子比特退相干等问题,2026年9月,清华大学团队在《自然·计算科学》上发表了一项研究,他们提出了一种“动态纠错”的量子Adagrad变体,在存在10%噪声的情况下,仍能保持90%以上的优化效率,这为算法的工业化应用铺平了道路。
人才缺口,量子计算和工业数字孪生的交叉领域,需要既懂量子算法又懂工业场景的复合型人才,2026年10月,教育部联合工信部发布了《量子+工业人才培养计划》,计划在未来五年内培养10万名相关人才,为技术落地提供人才保障。 本月绿色运营链与动漫产业及节能减排热度持续上升,相关产业迎来新发展
真实案例:量子Adagrad在半导体制造中的突破
说到这里,不得不提一个2026年最具代表性的案例——中芯国际的数字孪生晶圆厂项目,半导体制造是工业领域中对精度要求最高的场景之一,一片12英寸晶圆的生产要经过上千道工序,任何微小的参数波动都可能导致良率下降,中芯国际在2026年初启动项目时,就明确了目标:通过数字孪生实现全流程实时监控,把良率从92%提升到95%。
项目团队最初选用了经典的数字孪生方案,但很快遇到了“维度灾难”——晶圆生产涉及的温度、压力、气体流量等参数超过5000个,经典Adagrad在处理这么高维的数据时,训练周期长达两周,而且模型容易过拟合。“我们试过降维,但降维后会丢失关键信息,良率提升不明显。”项目负责人陈博士说。
2026年4月,团队引入了量子Adagrad优化器,他们与本源量子合作,在20量子比特的芯片上实现了针对半导体数据的专用优化算法。“量子Adagrad的优势在于它能自动识别哪些参数对良率影响大,哪些影响小,然后动态调整学习率。”陈博士解释,“光刻机的曝光能量