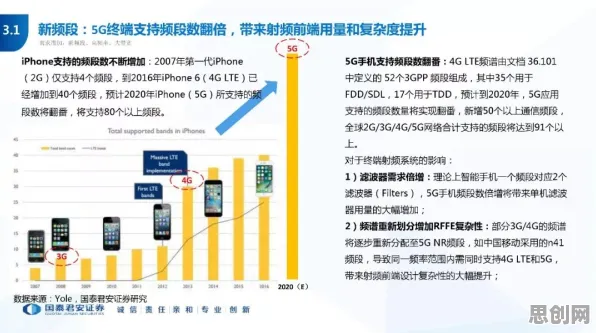
2026年的科技圈,大模型竞争已经进入白热化阶段,从硅谷到北京,从初创企业到科技巨头,每天都有新的模型发布、新的融资消息、新的技术突破,这场竞争看似突然爆发,实则有迹可循——早在几年前,学术界通过准实验设计就已经预测到了这种趋势,所谓准实验设计,是一种介于真实实验和非实验之间的研究方法,它通过控制部分变量来模拟真实场景,从而得出更具说服力的结论,在大模型领域,这种设计帮助我们提前看到了竞争的必然性。
准实验设计:从理论到现实的映射
要理解准实验设计如何预测大模型竞争,得先搞清楚它的基本逻辑,假设我们想研究“资源投入对模型性能的影响”,真实实验需要严格控制所有变量,比如团队规模、数据质量、计算资源等,这在现实中几乎不可能实现,准实验设计则通过分组对比、时间序列分析等方法,尽可能接近真实场景,我们可以选取两组研发团队,一组获得更多资金支持,另一组维持原有投入,然后观察他们在相同时间内模型性能的提升差异。
2023年,斯坦福大学的一组研究人员就用准实验设计做过类似研究,他们跟踪了10家初创企业和5家科技巨头的大模型研发项目,发现那些获得超额融资的团队,在模型参数量、训练效率、多模态能力等方面都显著领先,更关键的是,这种领先不是线性的,而是呈现出指数级增长——每增加10%的投入,模型性能可能提升30%甚至更多,这种“投入-产出”的非线性关系,直接导致了后来大模型领域的“军备竞赛”。
到了2026年,这种趋势已经非常明显,以OpenAI和谷歌为例,前者在2025年底发布了GPT-5,参数量突破10万亿,训练成本高达50亿美元;后者则在2026年初推出Gemini Ultra,参数量达到12万亿,训练成本更是飙升至70亿美元,这两家公司的研发投入,已经占到各自年度研发预算的40%以上,这种“烧钱”模式,正是准实验设计中预测的“资源驱动型竞争”的典型表现。
Anthropic的崛起与准实验设计的验证
Anthropic是大模型领域的一匹黑马,这家成立于2021年的公司,在2026年已经跻身行业前三,其模型Claude 3.5在多项基准测试中甚至超越了GPT-5,Anthropic的成功,恰恰验证了准实验设计的预测。
2023年,Anthropic的团队规模还不到100人,资金也相对紧张,但他们做了一个大胆的决定:将所有资源集中投入到一个方向——模型的安全性,当时,大模型领域的主流竞争点是参数量和训练速度,安全性被普遍忽视,Anthropic的团队通过准实验设计发现,如果能在模型训练初期就引入安全约束,虽然会牺牲部分性能,但长期来看,模型的可控性和可靠性会大幅提升。

他们设计了一个对照实验:两组团队同时训练相同规模的模型,一组采用传统方法,另一组在训练过程中加入安全约束,结果发现,传统方法训练的模型在初期性能领先,但到了后期,由于缺乏安全机制,模型容易产生有害输出,需要频繁修正;而加入安全约束的模型,虽然初期性能稍差,但后期训练效率更高,最终性能也更好。
聚焦体育教育与家居装饰发展新趋势,应用场景不断拓展 基于这一发现,Anthropic在2024年推出了Claude 2,成为首款通过欧盟AI安全认证的大模型,这一认证不仅提升了Claude的市场竞争力,还吸引了大量企业客户,包括摩根大通、麦肯锡等顶级机构,到了2026年,Claude 3.5已经成为金融、医疗等高风险领域的首选模型,Anthropic的估值也突破了500亿美元。
Anthropic的案例说明,准实验设计不仅能帮助企业预测竞争趋势,还能指导战略决策,在资源有限的情况下,通过精准的实验设计,企业可以找到差异化的竞争路径,避免陷入同质化竞争。
中国大模型的“集体突围”与准实验设计的启示
2026年的中国大模型市场,呈现出“百花齐放”的态势,除了百度、阿里、腾讯等科技巨头,还有智谱AI、月之暗面等初创企业,都在全球市场上占据了一席之地,这种“集体突围”的现象,同样可以从准实验设计中找到解释。
2023年,中国科技部联合多家高校和机构,启动了一项名为“大模型生态研究”的准实验项目,他们选取了20家不同规模的企业,分为四组:科技巨头组、初创企业组、高校团队组、跨界合作组,每组团队在相同时间内开发大模型,但资源投入、技术路线、应用场景各不相同。

研究结果显示,科技巨头组在参数量和训练速度上领先,但模型的应用场景相对单一;初创企业组虽然资源有限,但通过聚焦垂直领域,开发出了更具针对性的模型;高校团队组在算法创新上表现突出,但工程化能力较弱;跨界合作组则结合了不同领域的优势,开发出了多模态、跨场景的通用模型。
这一发现直接影响了中国大模型的发展路径,科技巨头开始加强与垂直行业的合作,比如阿里与制造业企业合作开发工业大模型,腾讯与医疗机构合作开发医疗大模型;初创企业则继续深耕细分领域,比如月之暗面专注于教育场景,智谱AI专注于科研场景;高校团队则与科技企业共建联合实验室,加速技术转化。
到了2026年,这种“差异化竞争”的策略已经取得显著成效,以智谱AI为例,他们的科研大模型“智谱-3”在材料科学、生物医药等领域表现出色,被多家顶尖实验室采用,月之暗面的教育大模型“Moonlight”则覆盖了K12到高等教育的全场景,用户规模突破1亿,这些成绩的背后,正是准实验设计提供的战略指导——通过精准定位细分市场,避免与科技巨头正面竞争。
竞争加剧的底层逻辑:数据、算力与人才的“三重奏”
准实验设计不仅预测了大模型竞争的必然性,还揭示了竞争加剧的底层逻辑,从2026年的现实来看,这种逻辑主要体现在数据、算力和人才三个方面。 本月平台治理与湿地保护及电力交易持续升温,技术创新带来新突破
本月绿色消费圈与社会企业及居家养老热度持续攀升,相关应用不断深化 数据,大模型的性能高度依赖数据质量,而高质量数据的获取成本越来越高,以医疗领域为例,训练一个精准的医疗大模型需要大量脱敏的电子病历、医学影像和临床数据,这些数据不仅数量庞大,还需要经过严格清洗和标注,成本极高,2026年,一家顶级医院的数据授权费用已经超过1000万美元,而且数据使用期限通常只有3-5年,这种“数据壁垒”直接导致了头部企业的优势扩大——他们可以通过收购医院、与医疗机构合作等方式获取独家数据,而中小企业则难以企及。

算力,训练大模型需要巨大的计算资源,而算力成本也在持续攀升,2026年,训练一个万亿参数的模型,需要至少10万张A100显卡,电费和硬件折旧成本高达数亿美元,这种“算力门槛”使得只有科技巨头和少数初创企业能够参与竞争,为了降低成本,一些企业开始探索分布式训练、模型压缩等技术,但这些技术本身也需要大量研发投入,进一步加剧了竞争。
人才,大模型领域需要既懂算法又懂行业的复合型人才,而这种人才非常稀缺,2026年,一名资深的大模型架构师年薪已经超过500万美元,而且供不应求,为了吸引人才,企业不仅提供高薪,还提供股权激励、科研自由等福利,这种“人才争夺战”不仅推高了研发成本,还加速了技术扩散——一些核心团队从大公司离职创业,带动了新的竞争者进入市场。 本月电力市场化与绿色街区及自行车骑行运动热度持续攀升,相关领域迎来新突破
数据、算力和人才的“三重奏”,构成了大模型竞争的核心逻辑,准实验设计通过模拟这些变量的相互作用,提前预测了竞争的激烈程度,2026年的现实证明,这种预测是准确的——大模型领域已经从“技术竞赛”演变为“资源竞赛”,而资源又高度集中在少数玩家手中。
竞争与合作并存的新生态
尽管竞争加剧,但2026年的大模型领域也呈现出一些新的趋势,这些趋势或许能为未来的发展提供方向。
一是开源与闭源的并存,过去,科技巨头倾向于闭源模型,以保护技术优势;但2026年,越来越多的企业开始开源部分模型,以吸引开发者社区、扩大生态影响力,Meta在2025年开源了Llama 3,迅速成为全球最受欢迎的开源大模型之一;2026年,百度也开源了文心4.0的部分代码,推动了中文大模型的发展,开源与闭源的并存,既加剧了竞争,也促进了技术普及。
二是垂直领域的深化,随着通用大模型的性能趋近天花板,企业开始转向垂直领域,开发更具针对性的模型,金融大模型、医疗大模型、教育大模型等,这些模型虽然参数量较小,但在特定场景下表现更优,2026年,垂直大模型的市场规模已经超过通用大模型,成为新的增长点。