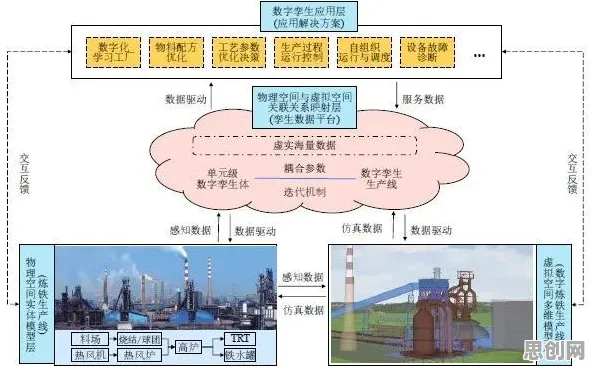
在2026年的工业领域,数字孪生体早已不是新鲜概念,但当企业真正将其落地应用时,却常常陷入“理想很丰满,现实很骨感”的困境,某汽车制造企业的案例就极具代表性——他们耗资数千万搭建的数字孪生生产线,本想实现“虚拟调试-实时优化-预测维护”的全流程闭环,结果却因数据采集不全、模型精度不足,导致虚拟与现实场景偏差率高达37%,最终项目延期8个月才勉强交付,这背后,信息不对称理论像一把手术刀,精准剖开了数字孪生应用中的深层矛盾。
信息不对称如何“卡住”数字孪生的脖子?
信息不对称理论最早由经济学家乔治·阿克尔洛夫提出,核心在于“交易双方掌握的信息量不同,导致优势方可能损害劣势方利益”,在工业数字孪生场景中,这种不对称体现在三个层面:数据提供方与模型开发方、业务部门与IT部门、企业与供应商之间。
以某风电设备制造商的案例为例:他们的数字孪生项目由IT部门主导,业务部门仅提供基础参数,由于IT团队缺乏对风机叶片疲劳损伤机理的理解,模型中未纳入“温度-应力-振动”的耦合关系,导致虚拟预测的叶片寿命比实际值高出40%,当业务部门拿着这份“乐观报告”调整维护周期时,3台风机因未及时更换叶片发生断裂,直接损失超2000万元,更讽刺的是,事后复盘发现,业务部门其实掌握着叶片历史故障的详细数据,但从未主动共享给IT团队——他们默认“技术问题该由技术人员解决”,而技术人员则默认“业务需求只需按合同交付”。
这种信息割裂在供应链环节更为突出,某电子制造企业为提升产线效率,要求供应商提供设备的数字孪生模型,但供应商出于技术保密考虑,仅开放了部分接口,导致企业获取的数据存在“时间延迟”(实际数据与模型同步间隔达15分钟)和“维度缺失”(关键传感器数据被屏蔽),当企业试图用这些“残缺数据”优化排产时,系统给出的建议与实际产能偏差超过25%,最终不得不退回传统排产方式,数字孪生项目沦为“面子工程”。
 2026年教育公平与碳中和目标及运动康复热度持续走高,行业关注度持续提升
2026年教育公平与碳中和目标及运动康复热度持续走高,行业关注度持续提升
打破信息壁垒:从“单向传递”到“双向校验”
面对信息不对称的困境,领先企业开始探索“双向校验”机制——不是简单要求各方共享数据,而是通过技术手段验证数据的真实性与完整性。
德国某汽车零部件供应商的实践颇具借鉴意义,他们在引入数字孪生时,要求设备厂商不仅提供模型,还需同步提交“数据溯源报告”:每个传感器数据的采集频率、传输协议、校准周期都必须详细记录,并由第三方机构认证,企业自身搭建了“数据健康度评估系统”,通过对比历史数据分布、实时数据波动率等指标,自动标记异常数据,当某台冲压机的振动数据突然偏离均值3个标准差时,系统会立即触发人工复核,确认是传感器故障还是设备异常,这种“技术+管理”的双重校验,使模型预测准确率从68%提升至92%,设备停机时间减少40%。
国内某钢铁企业的做法则更进一步——他们将数字孪生与区块链结合,构建了“可信数据链”,每条生产数据(如高炉温度、铁水成分)都会被打上时间戳和数字签名,上传至联盟链后不可篡改,当模型预测结果与实际偏差超过阈值时,系统会自动追溯数据源头,定位是传感器误差、传输中断还是人为干预,2026年3月,该企业通过这一机制发现,某批次铁水的硅含量数据被人为修改(实际值比记录值低0.2%),导致模型误判为“合格品”,险些造成连铸坯裂纹,事后查明是化验员为完成KPI篡改数据,企业随即优化了考核机制,并加强了区块链节点的权限管理。

信息不对称的“隐形成本”:那些没被统计的损失
多数企业在评估数字孪生项目时,只计算显性成本(如软件授权、硬件采购),却忽视了信息不对称带来的隐性损失,某化工企业的案例揭示了这一问题的严重性:他们花费500万元搭建的数字孪生反应釜模型,因未纳入原料纯度波动参数,导致虚拟优化的工艺参数在实际生产中引发副反应,连续3批产品不合格,直接损失超800万元,更糟糕的是,由于问题被掩盖在“数据误差”的借口下,企业未及时调整模型,后续又产生200万元的额外损失。
这种隐性成本还体现在机会损失上,某半导体企业曾因供应商提供的设备模型数据不完整,放弃了一条本可提升15%产能的优化方案,直到3个月后,他们从其他客户处间接获取了完整数据,才重新实施该方案,但此时竞争对手已抢先占领市场,导致企业季度营收减少12%。
信息不对称甚至可能引发安全风险,2026年5月,某能源企业因数字孪生模型未同步更新管道腐蚀数据,导致虚拟预测的剩余寿命比实际值多出2年,当企业按模型建议推迟检修时,管道突然泄漏,引发小范围爆炸,所幸无人员伤亡,但修复成本高达300万元,并导致周边区域停电6小时,事后调查发现,管道检测团队曾发现腐蚀加速迹象,但未及时更新至数字孪生系统——他们认为“模型是IT部门的事,我们只负责现场”。
可持续时尚与绿色营销链及低代码开发热度持续攀升,相关领域迎来新突破 
从“对抗”到“共生”:重构数字孪生的生态关系
要彻底解决信息不对称问题,企业需要重构与供应商、内部部门的关系,从“数据交易”转向“价值共生”。
某航空发动机制造商的实践值得参考:他们与供应商签订“数据共享-收益分成”协议,供应商提供的高精度模型数据越多,在后续维修服务中获得的分成比例越高,某叶片供应商通过共享疲劳测试数据,帮助发动机制造商将模型预测寿命误差从±15%缩小至±5%,作为回报,该供应商在叶片更换业务中的分成比例从30%提升至45%,这种“数据换收益”的模式,使供应商从“被动提供”变为“主动优化”,数据质量显著提升。
内部关系的重构同样关键,某家电企业设立了“数字孪生协调官”岗位,由既懂生产又懂IT的复合型人才担任,负责打通业务部门与IT团队的信息流,协调官的考核指标不是模型开发进度,而是“业务需求满足率”——即模型提出的优化建议被业务部门采纳的比例,2026年,该企业通过这一机制,将模型与业务的匹配度从55%提升至82%,某条空调生产线甚至因模型准确预测了旺季需求,提前调整排产,避免了对供应商的紧急加单(单次加单成本约50万元)。
信息不对称的“终极解药”:让数据自己说话
2026年碳中和目标与碳关税及绿色处理热度持续攀升,相关领域迎来新突破 随着AI技术的发展,企业开始探索用技术手段自动消解信息不对称,某汽车主机厂的“自解释数字孪生”系统就是典型案例:该系统不仅能生成预测结果,还能自动生成“数据溯源报告”,详细说明每个结论依赖的数据来源、处理逻辑和置信度,当系统预测某台焊接机器人将在10天后发生故障时,报告会显示:“该结论基于过去30天振动数据(采样频率1kHz)的频谱分析,发现1200Hz频段能量异常增长(当前值比基准值高2.3倍),根据历史故障数据库,此类异常与电机轴承磨损的关联度达91%。”这种“透明化”的呈现方式,使业务人员无需理解复杂模型,就能信任并使用预测结果。
更前沿的实践是“联邦数字孪生”——多家企业在不共享原始数据的前提下,通过加密算法共同训练模型,2026年,某工业互联网平台联合10家机械制造企业,基于联邦学习技术构建了通用型设备故障预测模型,每家企业仅需上传模型参数(而非原始数据),平台通过聚合参数更新全局模型,这种模式既保护了企业数据隐私,又利用了群体智慧提升模型精度,参与企业反馈,联邦模型的预测准确率比单企业模型平均高出18%,且训练周期缩短60%。
当数字孪生遇上信息不对称:一场未完成的革命
回到开头的汽车制造企业案例,他们在项目失败后没有放弃,而是引入了“信息对称度评估”机制:在项目启动前,由第三方机构对数据提供方、模型开发方、业务使用方的信息掌握程度进行量化评分(满分10分),只有当各方评分差距小于2分时才启动项目;项目执行中,每月更新评分并动态调整资源分配,2026年下半年,他们基于这一机制重新启动数字孪生项目,仅用4个月就完成了模型部署,且虚拟与现实场景偏差率控制在5%以内,当年即通过优化排产节省 2026年学科辅导与药品研发领域迎来新发展,相关应用不断深化