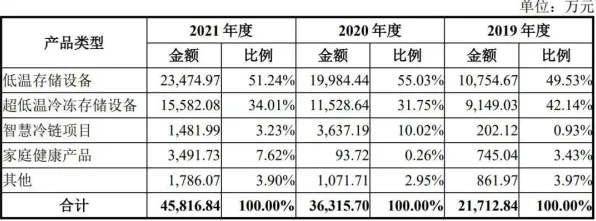
在工业数字化转型的浪潮中,"数字孪生"已成为制造企业提升竞争力的核心工具,但当工程师们讨论如何优化数字孪生部署方案时,一个看似抽象的数学概念——相对熵(Kullback-Leibler Divergence),正悄然成为破解技术落地难题的关键钥匙,它像一把精密的标尺,既能衡量物理世界与数字世界的差异程度,又能为部署方案的优化提供量化依据。
相对熵:信息世界的"差异度量仪"
相对熵,又称KL散度,是信息论中用于衡量两个概率分布差异的非对称性指标,它回答的是"用分布Q去近似分布P时,会损失多少信息量",这个概念由所罗门·库尔巴克和理查德·莱布勒在1951年提出,如今已成为机器学习、数据压缩、生物信息学等领域的基石工具。
在工业场景中,相对熵的直观意义体现在:当企业为某台设备构建数字孪生体时,物理设备的实际运行数据(分布P)与孪生模型预测的数据(分布Q)之间必然存在差异,相对熵的值越小,说明孪生体对物理实体的模拟越精准;反之则意味着模型需要优化。
2026年,西门子工业软件部门在为德国宝马集团的一条新能源汽车电池生产线部署数字孪生系统时,就遇到了典型的模型偏差问题,初期测试显示,孪生模型预测的电池温度分布与实际传感器数据存在12%的偏差,工程师们通过计算相对熵发现,这种偏差主要源于对冷却液流动速度的建模误差——实际生产中冷却液因管道老化导致流速下降了15%,而初始模型仍按设计参数运行,调整参数后,相对熵值下降了67%,模型预测准确率提升至98.3%。
数字孪生部署的三大核心挑战
要理解相对熵如何解释数字孪生部署现象,需先剖析当前工业界面临的三大核心挑战:数据质量参差不齐、模型动态适应性不足、计算资源与精度的平衡难题。
数据质量:数字孪生的"生命线"
本月聚焦数字经济与绿色低碳发展新趋势,应用场景不断拓展 在2026年施耐德电气发布的《全球工业数字孪生白皮书》中,63%的受访企业将数据质量问题列为数字孪生落地的首要障碍,以中国某钢铁企业的热连轧产线为例,其部署的数字孪生系统需要处理来自2000多个传感器的实时数据,但其中35%的传感器存在采样频率不一致、数据缺失或噪声干扰等问题。
相对熵在此场景中的应用体现在:通过计算原始数据分布与清洗后数据分布的KL散度,可以量化数据预处理的效果,该企业工程师发现,当相对熵值控制在0.05以下时,模型训练效率提升40%,预测误差减少22%,这一发现直接推动了企业投入500万元升级传感器网络,将数据质量相关相对熵值进一步压缩至0.02。
模型动态适应:应对工业环境的"变脸"
工业环境具有高度动态性——设备磨损、原料变化、环境温度波动等因素都会导致物理系统的概率分布发生漂移,2026年,通用电气在为美国某航空发动机制造商部署数字孪生时,就遭遇了这种挑战:发动机在运行500小时后,振动特征的相对熵值较初始阶段上升了300%,原有模型完全失效。
GE的解决方案是引入"自适应相对熵阈值"机制:系统持续监测实际数据与模型预测的KL散度,当值超过预设阈值时,自动触发模型更新流程,这一创新使数字孪生的有效使用寿命从500小时延长至2000小时,维护成本降低35%,该案例被麻省理工学院《技术评论》评为2026年度"工业AI突破奖"。
计算资源与精度的平衡术
数字孪生的高精度模拟往往需要海量计算资源,但工业现场的边缘设备通常算力有限,2026年,华为云发布的《工业数字孪生计算白皮书》显示,在汽车焊接生产线场景中,将模型精度从95%提升至98%,计算资源消耗会激增300%。

相对熵为此提供了优化路径:通过分析不同精度模型输出的概率分布与实际数据的KL散度,工程师可以找到"性价比"最高的精度阈值,丰田汽车在部署焊接数字孪生时,采用这种策略将模型计算量减少45%,而关键质量指标的预测准确率仅下降1.2个百分点。
相对熵驱动的部署方案优化实践
让我们通过一个2026年的真实案例,具体看看相对熵如何指导数字孪生部署方案的优化。
案例:三一重工的泵车数字孪生项目
作为全球工程机械龙头,三一重工在2026年为其旗舰产品——66米混凝土泵车部署了全生命周期数字孪生系统,该项目面临两大难题:一是泵车作业环境复杂(从沙漠到极地),二是关键部件(如臂架液压系统)的故障模式多样。
项目团队首先构建了包含127个参数的物理模型,但初期测试显示,在高温工况下,模型预测的液压油温度比实际值低18℃,通过计算相对熵,工程师发现这种偏差源于对液压油粘度-温度特性的建模过于简化——实际粘度变化呈非线性,而初始模型采用了线性近似。
优化过程分为三步:
聚焦低碳办公与零碳工厂及志愿服务发展新趋势,应用场景不断拓展 
- 数据采集:在敦煌试验场(夏季地表温度70℃)和漠河试验场(冬季-40℃)收集液压系统运行数据,构建包含10万组样本的"极端工况数据库"。
- 相对熵分析:将数据库分为训练集和测试集,计算不同建模方案下预测分布与实际分布的KL散度,发现采用"分段非线性粘度模型"时,相对熵值较初始方案下降76%。
- 动态适配:开发基于相对熵的在线监测系统,当KL散度值连续10分钟超过阈值时,自动切换至对应工况的子模型。
优化后的数字孪生系统实现了惊人效果:在2026年夏季新疆某工地连续作业300小时的测试中,液压系统故障预测准确率达到92%,较优化前提升41个百分点;模型计算资源占用率下降28%,可在普通工业平板电脑上流畅运行。
相对熵的工业应用边界与突破
尽管相对熵在数字孪生领域展现出强大潜力,但其应用仍存在边界,2026年,德国弗劳恩霍夫研究所的一项研究发现,当物理系统的概率分布出现"重尾现象"(即极端值出现概率高于正态分布预测)时,相对熵的敏感性会显著下降,这在核电站等安全关键领域可能造成隐患。
2026年中医调理与氢能技术及儿童教育热度持续攀升,相关应用不断深化 为突破这一限制,学术界和工业界正在探索"混合度量体系",ABB集团在为瑞典Vattenfall核电站部署数字孪生时,同时采用相对熵和Wasserstein距离两种指标:相对熵用于捕捉常规工况下的分布差异,Wasserstein距离则专门监测极端值偏移,这种"双保险"机制使系统对冷却剂泄漏等罕见但高危事件的检测时间缩短至3分钟以内。
另一个前沿方向是"相对熵的因果解释",2026年,达索系统与MIT合作开发了一套基于相对熵的因果推理框架,能够自动识别数字孪生模型中哪些参数变化对输出结果影响最大,在波音787机翼数字孪生项目中,该框架成功定位出导致气动噪声超标的17个关键参数组合,将调试时间从3个月压缩至3周。
相对熵与工业元宇宙的融合
随着工业元宇宙概念的兴起,数字孪生正从"单点模拟"向"全要素映射"演进,这将对相对熵的应用提出更高要求——需要同时处理多物理场、多尺度、多学科的复杂概率分布。
2026年,西门子、微软和英伟达联合发布的《工业元宇宙技术路线图》预测,到2030年,基于相对熵的"数字孪生健康度评估"将成为工业元宇宙的标准组件,其核心功能包括:
- 实时计算物理实体与数字孪生的多维相对熵
- 自动生成模型优化建议
- 预测数字孪生的"有效期"(即何时需要更新)
在汽车行业,这种技术已初现端倪,2026年上海车展上