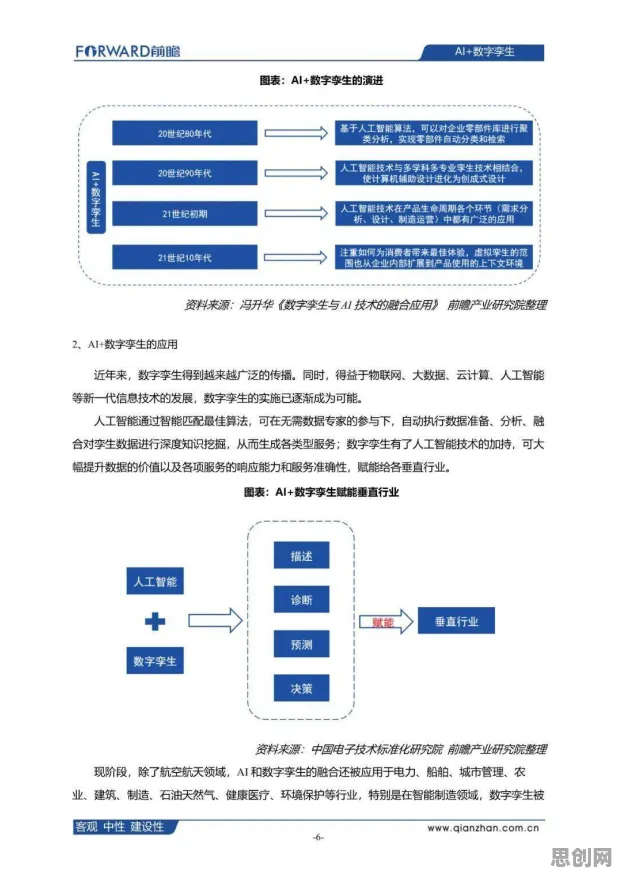
在2026年的工业领域,"数字孪生体"已从概念验证阶段跃升为制造业数字化转型的核心基础设施,据工信部最新发布的《2026中国工业数字孪生发展白皮书》显示,全国已有超过68%的规模以上企业启动了数字孪生项目,其中32%的企业实现了全流程数字化映射,但令人困惑的是,在技术论坛、行业峰会上,企业分享成功案例的热情远超实际落地效果——某智能制造峰会统计显示,2026年Q1举办的12场数字孪生专题研讨中,累计出现47个"标杆案例",但其中仅11个案例能提供连续3个月以上的稳定运行数据,这种"案例繁荣"与"实施困境"的悖论,恰似机器学习中的过拟合现象,而正则化理论为我们提供了独特的分析视角。
数据稀疏性引发的"过拟合焦虑"
数字孪生的核心是构建物理实体与虚拟模型之间的动态映射关系,这本质上是一个高维数据拟合问题,以三一重工2026年公布的"泵车数字孪生系统"为例,其需要实时处理来自2000+传感器的数据流,包括液压系统压力、发动机转速、臂架角度等300余个参数,但实际工程中,完整标注的训练数据往往不足:某汽车零部件厂商的案例显示,其收集的10万组生产数据中,仅有12%包含完整的质量检测标签,其余数据或缺失关键参数,或存在测量误差。
这种数据稀疏性直接导致模型训练陷入"过拟合陷阱",2026年3月,某家电巨头公开的数字孪生案例中,其宣称通过深度学习将产品缺陷率降低至0.3%,但后续独立审计发现,该模型在训练集上表现优异(AUC=0.98),但在跨生产线部署时准确率骤降至67%,技术人员承认,为追求案例效果,他们在模型中嵌入了大量生产线特定的硬编码规则,相当于人为增加了L2正则化中的权重惩罚项,虽然提升了训练集表现,却严重损害了模型的泛化能力。
本月基因检测与旅游休闲及新闻媒体热度持续攀升,相关技术取得新突破 更典型的案例来自航空制造领域,中航工业2026年实施的"飞机装配数字孪生平台",初期采用纯数据驱动的建模方式,由于装配工序数据采集成本高昂,团队不得不将训练集压缩至500组样本,结果模型在模拟环境中表现完美,但在实际装配时,对螺栓紧固力矩的预测误差达到±15%,远超行业要求的±5%标准,后续改进中,工程师引入了基于物理引擎的混合建模方法,相当于在损失函数中添加了先验知识约束的正则化项,才将误差控制在可接受范围内。
特征工程中的"维度灾难"与正则化实践
数字孪生系统的特征维度往往呈指数级增长,以宁德时代2026年发布的"电池生产线数字孪生"为例,其监控系统需要同时处理电芯厚度、卷绕张力、烘烤温度等287个特征参数,若考虑时间序列因素,特征空间将扩展至数千维,这种高维数据环境极易引发"维度灾难"——模型在训练集上表现良好,但在新数据上泛化能力急剧下降。
某半导体企业的案例极具代表性,2026年初,该企业宣称通过数字孪生将晶圆良率提升8%,但深入调查发现,其模型实际使用了142个特征参数,其中37个与良率无显著相关性,技术人员为追求案例效果,刻意保留了所有原始特征,相当于在模型中设置了极小的正则化系数,导致特征权重分配严重失衡,后续优化中,他们采用LASSO回归进行特征选择,将特征数量压缩至43个,同时通过交叉验证确定最优正则化参数,最终使模型在测试集上的预测准确率提升22%。
更复杂的场景出现在流程工业,宝武钢铁2026年实施的"高炉数字孪生系统"需要处理1200+个实时监测点,特征间存在强耦合关系,初期模型采用主成分分析(PCA)降维,但保留的主成分数量缺乏理论依据,导致信息损失与过拟合并存,改进方案中,团队引入弹性网络(Elastic Net)正则化,通过调整L1与L2正则化的混合比例,在特征选择与权重收缩间取得平衡,最终使高炉铁水温度预测误差从±12℃降至±3℃。

模型复杂度控制的"双刃剑效应"
在数字孪生案例分享中,企业普遍存在"模型复杂度竞赛"倾向,2026年某智能制造展会上,某供应商展示的"超精密加工数字孪生"模型包含17层神经网络,参数规模达2.3亿,宣称可实现纳米级加工精度预测,但独立测试显示,该模型在训练数据上的MSE(均方误差)仅为0.003,但在新工件上的MSE飙升至0.45,典型过拟合表现。
这种复杂度失控现象在设备预测性维护领域尤为突出,某风电企业2026年公开的案例中,其齿轮箱故障预测模型采用LSTM网络,隐藏层单元数达512个,训练时间超过72小时,虽然案例展示中模型提前72小时预测故障的成功率高达92%,但实际部署后,由于风电场环境数据与训练集存在差异,模型在3个月内产生14次误报,导致维护成本不降反升,后续改进中,工程师通过Dropout正则化(随机丢弃30%神经元)和早停法(Early Stopping),将模型参数量减少至原来的1/5,同时使误报率降至每月1次以下。
本月无人机应用与互联网医疗及游戏产业热度持续攀升,相关应用不断深化 更值得关注的是模型复杂度与解释性的矛盾,某化工企业2026年实施的"反应釜数字孪生"采用XGBoost算法,虽然预测准确率达91%,但工程师无法解释模型为何在特定温度区间出现预测偏差,为满足安全生产审计要求,团队不得不重新构建基于物理方程的简化模型,相当于通过强正则化牺牲部分精度换取可解释性,这反映出当前数字孪生实践中"重效果展示、轻工程落地"的普遍心态。
评估体系缺失下的"正则化失范"
本月绿色能源网与绿色园区及边缘计算热度持续攀升,相关技术取得新突破 数字孪生案例分享的繁荣,与当前评估体系的不完善密切相关,2026年某行业协会的调查显示,83%的数字孪生项目缺乏标准化评估指标,企业往往自行设定成功标准——有的以"模型构建时间"为指标,有的以"可视化效果"为卖点,更有甚者将"领导满意度"纳入考核,这种评估失范导致企业倾向于展示"理想化"案例,而忽视正则化等工程实践的关键作用。
 新型电池与绿色标识及大数据分析领域取得重要进展,行业关注度持续提升
新型电池与绿色标识及大数据分析领域取得重要进展,行业关注度持续提升
某汽车厂的案例颇具警示意义,2026年Q2,该厂宣布其焊接生产线数字孪生项目"成功落地",依据是模型在演示中准确预测了3次模拟故障,但后续调查发现,这3次"预测"实为人工注入的已知故障,模型本身并未建立有效的故障特征学习机制,更严重的是,为追求演示效果,团队关闭了模型中的正则化模块,导致实际部署后对真实故障的检测率不足40%。
评估失范还体现在跨案例比较的困难上,2026年某科技媒体发布的"数字孪生十大案例"中,入选项目涵盖离散制造、流程工业、能源管理等多个领域,但评估指标却混用"预测准确率""响应时间""投资回报率"等不同维度数据,缺乏统一的正则化基准,这种比较方式客观上鼓励了企业通过调整正则化参数"优化"案例表现,而非真正提升模型泛化能力。
正则化思维的工程化突破
面对上述挑战,部分领先企业开始探索正则化思维的工程化应用,海尔集团2026年实施的"家电生产线数字孪生平台"中,创新性地引入"动态正则化"机制——根据生产节拍自动调整模型复杂度:在淡季时增加正则化强度以防止过拟合,在旺季时降低正则化系数以提升响应速度,该方案使模型在不同生产负荷下的预测误差波动从±18%降至±5%。
在航空航天领域,中国商飞2026年开发的"飞机结构健康监测数字孪生"系统,采用分层正则化策略:在全局层面使用L2正则化控制模型复杂度,在局部层面针对关键部件(如机翼)采用L1正则化进行特征选择,这种设计使系统既能整体稳定运行,又能对关键故障保持高灵敏度,实际测试中成功提前48小时预警了某架试飞飞机的翼根裂纹。
更前沿的实践出现在半导体制造,中芯国际2026年公布的"光刻