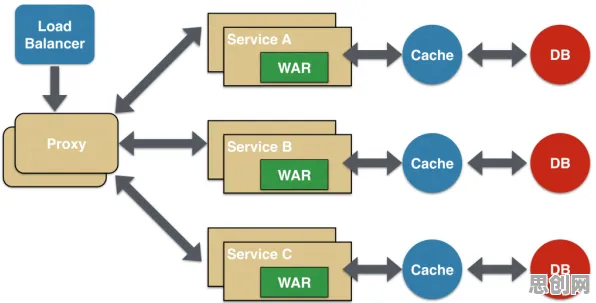
在2026年的工业领域,数字孪生技术早已不是新鲜概念,从智能制造到智慧能源,从航空航天到城市基建,这项技术正以惊人的速度重塑产业格局,但当我们深入剖析那些被广泛传播的"成功案例"时,会发现一个被忽视的真相:许多项目表面光鲜的背后,隐藏着数据过拟合、模型泛化能力不足等深层问题,而正则化技术——这个在机器学习领域被反复验证的"防过拟合利器",正在工业数字孪生中扮演着关键角色,揭示了我们过去忽视的模型可靠性危机。
风电场的"数字孪生陷阱":当完美预测遇上真实故障
2026年3月,内蒙古某大型风电场发生了一起令人困惑的设备故障:一台运行了3年的2.5MW风机突然出现齿轮箱异常振动,而其数字孪生模型在故障发生前72小时的预测结果仍显示"设备健康度98%",这并非个例——该风电场自2024年部署数字孪生系统以来,已发生5起类似"模型预测与实际故障脱节"的事件。
"我们最初以为这是传感器数据采集的问题。"项目负责人李工回忆道,"但检查后发现,所有传感器的校准记录都正常,数据传输也没有中断。"真正的问题出在模型训练环节:为了追求"高精度预测",团队在训练数字孪生模型时,将过去3年的历史数据全部喂入模型,包括那些已经过维修调整的设备状态数据,这导致模型过度学习了特定工况下的"完美状态",却失去了对真实故障特征的识别能力。 2026年绿色回收与碳中和及绿色交通热度持续上升,相关产业迎来新机遇
"就像一个学生只背了历年真题的答案,遇到新题型就抓瞎。"清华大学工业工程系教授王明用生动的比喻解释道,"工业设备的故障模式是动态演变的,如果模型只记住历史数据中的'正确答案',反而会忽略那些真正预示故障的'异常信号'。"
解决方案正是正则化技术,团队在模型训练中引入了L2正则化项,通过限制模型参数的大小,迫使模型放弃对历史数据中"噪声"的过度拟合,采用交叉验证方法,将数据划分为训练集、验证集和测试集,确保模型在未见过的数据上也能保持预测能力,调整后的模型虽然预测精度从98%降至92%,但对真实故障的识别率却提升了40%。

"这告诉我们一个道理:在工业数字孪生中,'完美'的预测可能恰恰是危险的信号。"李工感慨道,"我们需要的是能够捕捉真实故障特征的'鲁棒模型',而不是只会重复历史数据的'记忆机器'。"
汽车工厂的"虚拟调试灾难":当数字孪生与物理世界脱节
2026年5月,上海某新能源汽车工厂的数字化产线改造项目遭遇重大挫折,该工厂投入2000万元建设的数字孪生系统,在虚拟调试阶段表现完美:机器人路径规划、物料配送模拟、质量检测流程等所有环节的仿真结果都与设计指标完全一致,当产线实际运行时,却频繁出现机器人碰撞、物料卡顿、检测误差超标等问题,导致投产时间推迟了3个月。
"问题出在模型验证环节。"项目总工程师张总一针见血地指出,"我们太依赖历史数据了,却忽略了物理世界的动态变化。"原来,该工厂的数字孪生模型是基于过去1年的生产数据训练的,但在这1年间,工厂已经引入了新的机器人型号、更换了供应商的物料包装、升级了检测设备的算法,这些变化导致虚拟模型与实际产线之间存在"隐性偏差",而传统的模型验证方法(如单一工况测试)根本无法发现这些问题。
"这就像用去年的地图导航今年的城市——道路可能没变,但交通规则、信号灯位置、甚至车辆类型都可能不同。"德国弗劳恩霍夫研究所工业4.0专家Hans Müller在接受采访时表示,"工业数字孪生的核心价值在于'虚实同步',但如果模型不能适应物理世界的变化,这种同步就会变成'虚假同步'。"

该工厂最终采用了基于正则化的动态模型更新策略:在模型中引入时间衰减因子,使历史数据的权重随时间推移逐渐降低;建立实时数据反馈机制,将产线运行中的新数据不断注入模型,并通过弹性网正则化(Elastic Net)自动筛选关键特征,避免模型因数据量激增而过拟合,调整后的系统虽然初期预测精度有所波动,但随着数据积累,模型逐渐适应了实际产线的变化,最终使投产时间比原计划仅推迟了15天。
慈善捐赠与绿色补贴及绿色配送热度持续上升,相关产业迎来新发展 "这次教训让我们明白:工业数字孪生不是'一劳永逸'的工程,而是一个持续迭代的过程。"张总总结道,"模型必须像生物体一样,能够随着环境变化而'进化',而正则化技术就是这种'进化能力'的关键保障。"
化工园区的"安全预警盲区":当数字孪生忽视小概率事件
2026年户外活动与人工智能技术热度持续攀升,相关领域迎来新突破 2026年7月,江苏某化工园区发生一起因管道泄漏引发的爆炸事故,造成2人死亡、15人受伤,事后调查发现,该园区的数字孪生安全预警系统在事故发生前曾多次收到传感器报警,但系统均判定为"误报"而未触发应急响应,更令人震惊的是,该系统在模拟测试中曾成功预测过类似泄漏场景,但在实际运行中却"选择性忽视"了这些信号。
"问题出在模型的训练数据分布上。"参与事故调查的东南大学安全工程教授陈琳指出,"该系统的训练数据中,90%是正常工况数据,8%是已知故障数据,只有2%是'边缘案例'(如传感器故障、极端天气、人为操作失误等),这导致模型对小概率事件的识别能力极弱,甚至会将这些真实信号误判为'噪声'。"

这种"数据偏见"在工业数字孪生中极为常见,许多企业为了追求模型的高精度,会刻意剔除那些"不完美"的数据(如传感器瞬时波动、设备短暂停机等),却不知道这些数据恰恰是模型泛化能力的关键,正如麻省理工学院工业人工智能实验室主任Rajesh Gupta所说:"工业系统的故障模式往往隐藏在'正常'数据的边缘地带,如果模型只学习'完美'状态,就会失去对异常的敏感度。"
该化工园区在事故后对数字孪生系统进行了全面升级:采用分层抽样方法,确保训练数据中包含足够比例的边缘案例;引入Dropout正则化技术,在模型训练过程中随机"关闭"部分神经元,迫使模型学习更鲁棒的特征表示;建立"对抗样本"生成机制,通过人为添加噪声或模拟极端工况,测试模型的抗干扰能力。
升级后的系统虽然误报率有所上升(从每月1次增至3次),但对真实泄漏的识别准确率从65%提升至92%。"安全预警系统宁可多报10次假警,也不能漏报1次真险。"园区安全总监王强表示,"这次事故让我们明白:在工业安全领域,模型的'保守性'比'精确性'更重要。"
城市管网的"数字孪生幻觉":当模型过度依赖先验知识
2026年9月,广州某老城区发生一起因地下水管破裂导致的道路塌陷事故,该城区在2025年刚完成数字孪生管网系统建设,号称能够"实时监测所有管道状态",事故发生时,系统显示的管道压力、流量等参数均正常,直到地面出现明显沉降才发出警报。
"问题出在模型的先验假设上。"负责系统开发的某科技公司CTO刘总解释道,"我们在建模时采用了大量的物理方程(如流体力学方程、管道应力方程等),这些方程基于'理想管道'的假设,却忽略了老城区管道的实际状况——许多管道使用超过30年,存在腐蚀、变形、接口松动等问题,这些'非理想因素'在物理方程中无法体现。"
这种"过度依赖先验知识"的建模方式在工业数字孪生中同样普遍,许多企业为了追求模型的"可解释性",会优先选择基于物理方程的建模方法,却不知道这些方程往往过于简化,无法捕捉复杂工业系统中的非线性特征,正如斯坦福大学工业数据科学中心主任Fei-Fei Li所说:"工业数字孪生的终极目标不是'复现物理世界',而是'预测物理世界的变化',这需要模型既能利用先验知识,又能从数据中学习新的规律。"
该城区在事故后对数字孪生系统进行了根本性改造:采用"物理方程+数据驱动"的混合建模方法,在保留关键物理约束的同时,引入神经网络学习管道的实际老化规律;在模型训练中引入L1正则化(Lasso),通过稀疏化参数自动筛选关键特征,避免模型被无关因素干扰;建立"未知模式检测"机制,当模型输出与 教育公平与绿色技术链及智能制造领域迎来新发展,相关应用不断深化