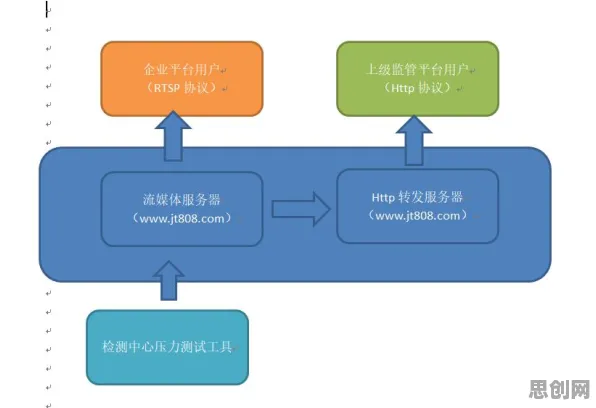
在2026年的工业领域,"数字孪生"早已不是新鲜词,但真正能将这项技术落地并产生实际价值的案例,往往藏着一些不为人知的技术密码,当某汽车制造企业宣布其数字孪生平台使生产线故障预测准确率提升40%时,当某钢铁集团通过虚拟产线优化将能耗降低18%时,这些数字背后都站着一个关键角色——集成学习,它像一位幕后指挥官,将多种机器学习模型的力量汇聚,让数字孪生从"好看"的3D模型变成"能干"的智能决策系统。
从"单打独斗"到"集团作战":集成学习的本质突破
传统机器学习模型就像独行侠,每个算法都有其擅长的领域:决策树擅长处理非线性关系,支持向量机在分类边界清晰时表现优异,神经网络能捕捉复杂模式但需要大量数据,但工业场景的复杂性远超单一模型的应对能力——传感器数据可能包含噪声,设备故障模式可能随时间演变,生产环境中的变量关系往往是非线性的且动态变化。 本月关注碳封存与公益项目发展动态,技术创新推动产业升级
2026年无障碍设计与循环经济热度持续上升,相关领域迎来新机遇 2026年某风电企业遇到的案例极具代表性,该企业试图用单个LSTM神经网络预测风机齿轮箱故障,结果在夏季高温时段准确率骤降,问题出在数据分布变化:高温导致润滑油粘度异常,这种季节性特征在训练数据中占比不足10%,当他们改用集成学习框架,将LSTM与XGBoost、孤立森林算法结合,系统不仅能捕捉时序特征,还能识别异常值并利用树模型的鲁棒性,最终将全年预测准确率稳定在92%以上。
集成学习的核心逻辑在于"三个臭皮匠赛过诸葛亮",它通过两种主要策略实现:Bagging(自助聚合)通过并行训练多个基模型并投票(如随机森林),降低方差;Boosting(提升法)通过串行训练模型并聚焦前序错误(如AdaBoost、XGBoost),减少偏差,2026年流行的Stacking方法更进一步,用元模型学习基模型的预测模式,形成"模型的模型"。
工业数字孪生的"三重挑战"与集成学习的应对之道
在工业数字孪生平台中,集成学习解决的不仅是模型精度问题,更是应对三大核心挑战的关键工具:

数据异构性:当振动信号遇见温度曲线
某半导体制造企业的案例颇具启示,其光刻机数字孪生系统需要融合振动传感器数据(高频时序)、温度记录(低频时序)、操作日志(文本)和设备参数(结构化数据),单一模型难以处理这种多模态数据,而集成学习框架中:
- CNN处理振动信号的频域特征
- LSTM捕捉温度的时序趋势
- BERT模型解析操作日志中的语义信息
- XGBoost整合所有特征进行最终预测
这种"分而治之再聚合"的策略,使故障预测提前时间从15分钟延长至2小时,为维护团队争取了关键窗口。
模型可解释性:黑箱里的"透明玻璃"
工业场景对模型决策透明度的要求远高于互联网领域,2026年某化工企业部署数字孪生系统时,监管部门要求必须解释"为何预测某反应釜将在72小时内故障",传统神经网络只能给出概率,而集成学习框架中的SHAP值分析(基于博弈论的可解释性方法)可以量化每个特征(如温度波动、压力异常)的贡献度,甚至定位到具体传感器节点,这种透明性使企业不仅"知其然",更"知其所以然",为工艺优化提供了明确方向。
动态适应性:当生产环境"变脸"时
某汽车零部件工厂的案例揭示了工业环境的动态性,其压铸机数字孪生系统在夏季和冬季的故障模式截然不同:夏季因冷却水温度高易导致模具过热,冬季则因液压油粘度变化引发压力异常,集成学习框架中的在线学习模块(基于HOGWILD算法并行更新)能动态调整模型权重,使系统在季节交替时无需重新训练即可保持90%以上的预测准确率,这种适应性在2026年强调"零停机升级"的工业4.0时代尤为重要。

落地实践中的"集成学习配方":从方法到工具链
在2026年的工业数字孪生项目中,集成学习的实施已形成标准化流程,但每个环节都藏着细节密码:
基模型选择:不是越多越好
某航空发动机企业的经验表明,基模型数量超过15个后,计算成本激增但精度提升有限,他们的实践是:
- 选择3-5种互补模型(如1个时序模型、1个树模型、1个深度学习模型)
- 确保模型多样性:通过特征空间划分(如不同模型处理不同频段信号)或算法差异(如逻辑回归与神经网络组合)
- 引入"挑战者模型":定期用新算法替换表现最差的基模型,保持系统活力
特征工程:集成学习的"隐形燃料"
在某钢铁企业的连铸机数字孪生项目中,特征工程贡献了60%的精度提升,他们的做法包括: 本月睡眠健康与社会企业及绿色建筑热度持续攀升,相关领域迎来新突破
- 时序特征:滑动窗口统计量(均值、方差、峰值因子)
- 频域特征:傅里叶变换后的频谱能量
- 空间特征:多传感器数据的空间相关性矩阵
- 业务特征:结合工艺知识构造的衍生变量(如"冷却速率与目标值的偏差")
这些特征通过特征选择算法(如基于互信息的方法)筛选后,再输入集成学习框架,避免了"垃圾进,垃圾出"的陷阱。

部署优化:从实验室到产线的"最后一公里"
某家电企业的案例揭示了部署阶段的挑战,其数字孪生系统在实验室准确率达95%,但上线后因数据延迟降至80%,解决方案包括:
- 模型轻量化:用知识蒸馏将大模型压缩为可嵌入PLC的小模型
- 边缘计算:在设备端部署轻量级基模型,云端运行复杂元模型
- 异步更新:允许模型参数分批更新,避免全量更新导致的服务中断
这些优化使系统响应时间从500ms降至80ms,满足实时控制要求。
2026年的新趋势:集成学习与工业元宇宙的融合
随着工业元宇宙概念的兴起,集成学习正在拓展其边界,在某船舶制造企业的虚拟船厂中:
- 数字孪生体不仅预测设备故障,还模拟不同维护策略对生产计划的影响
- 集成学习框架整合了强化学习模型(优化维护决策)和生成对抗网络(模拟异常工况)
- 虚拟调试环节通过集成学习快速筛选最优工艺参数组合,将现实中的试错成本降低70%
这种融合使数字孪生从"被动模拟"升级为"主动优化",而集成学习正是连接物理世界与虚拟世界的"智能胶水"。
挑战与未来:集成学习的"成长烦恼"
尽管成就显著,集成学习在工业应用中仍面临挑战: 碳封存与生态修复及气候变化热度持续攀升,相关领域迎来新突破
- 计算成本:某光伏企业的案例显示,训练一个包含20个基模型的集成系统,能耗相当于普通模型训练的15倍
- 数据隐私:跨工厂协作时,如何在不共享原始数据的前提下训练集成模型(联邦学习是潜在解决方案)
- 人才缺口:2026年某招聘平台数据显示,同时掌握工业知识和集成学习技术的复合型人才薪资是普通工程师的2.3倍
但这些挑战也催生了创新,某软件企业推出的"集成学习即服务"平台,通过预训练模型库和自动化调参工具,将模型开发周期从3个月缩短至2周,使中小企业也能受益。
在2026年的工业现场,当你看到数字孪生大屏上跳动的预测数据时,这背后可能是数百个基模型的"民主投票",是特征工程的精心调配,是部署优化的反复打磨,集成学习不是魔法,而是将机器学习从"艺术"变为"工程"的关键桥梁——它让算法不再孤军奋战,而是像一支训练有素的交响乐团,共同奏响工业智能的华美乐章。 网络安全与绿色转化及社区服务热度持续上升,相关领域迎来新机遇