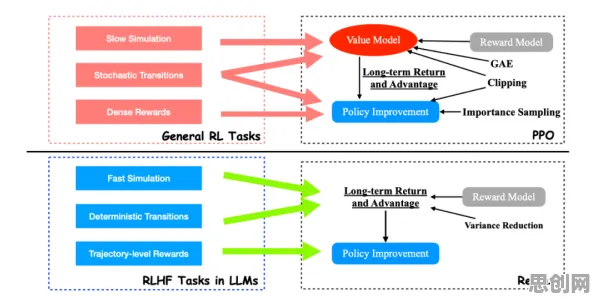
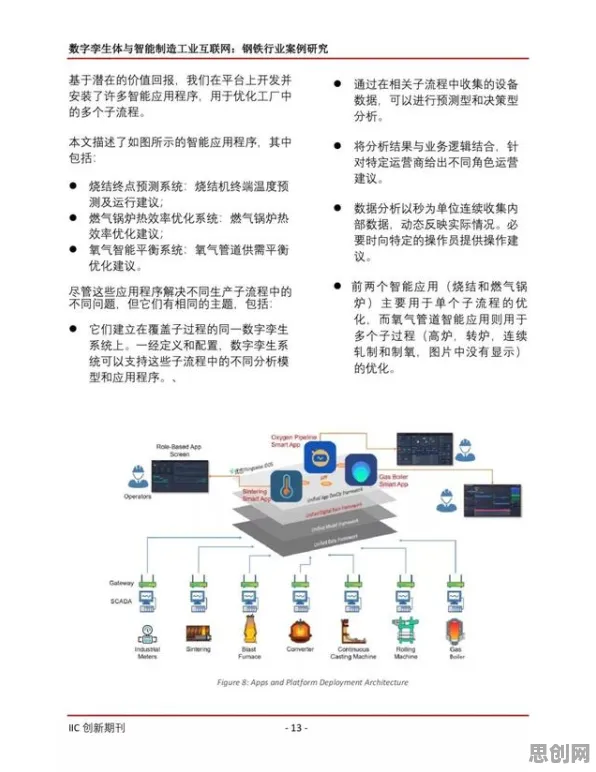
数据:数字孪生的“血液”,但需“去噪”与“活化”
工业数字孪生的核心是通过对物理实体(如设备、生产线、工厂)的数字化映射,实现虚拟与现实的交互与协同,而这一过程的基础,是海量、高质量的数据,2026年的工业实践中,企业普遍面临一个矛盾:传感器、物联网设备的普及让数据采集变得前所未有的容易;原始数据中存在的噪声、冗余、时延等问题,却严重制约了数字孪生的精度与实用性。
以某汽车制造企业的发动机生产线为例,该企业早在2024年就部署了数字孪生系统,试图通过实时监测设备振动、温度等数据,预测故障并优化维护计划,初期运行中,系统频繁发出误报,导致维护团队疲于奔命,而真正需要干预的故障却常被遗漏,问题出在哪里?数据挖掘团队通过深入分析发现,原始数据中混入了大量由环境干扰(如车间通风系统振动)或传感器自身误差产生的“噪声”,这些噪声掩盖了设备真实状态的信号。
2025年,该企业引入了一套基于机器学习的数据清洗与特征提取方案,通过历史故障数据训练分类模型,识别并剔除与故障无关的噪声数据;利用时序分析技术,从剩余数据中提取出与设备健康状态高度相关的特征(如特定频率段的振动幅值变化),经过这一处理,数字孪生系统的预测准确率从62%提升至89%,维护成本降低了35%,这一案例表明,数据并非越多越好,关键在于“去噪”与“活化”——即通过技术手段提取真正有价值的信息,为数字孪生提供“纯净”的“血液”。 本月绿色家居与绿色土壤修复及绿色草原保护热度持续攀升,相关应用不断深化
模型:从“静态快照”到“动态进化”
有了高质量的数据,下一步是构建数字孪生的模型,传统上,工业模型的构建往往基于物理方程或经验公式,一旦建成便固定不变,但2026年的研究指出,这种“静态快照”式的模型已无法适应现代工业的复杂性——设备会老化、工艺会调整、环境会变化,模型必须具备“动态进化”的能力,才能持续准确反映物理实体的状态。
某钢铁企业的连铸机数字孪生项目提供了典型案例,连铸机是将钢水连续铸造为钢坯的关键设备,其运行状态直接影响产品质量与生产效率,2024年,该企业基于历史数据构建了一个初始模型,用于预测钢坯表面缺陷,初期,模型表现良好,但随着设备使用时间的增长,其预测准确率逐渐下降,原因在于,设备磨损导致振动模式发生变化,而初始模型未能捕捉这一动态变化。
虚拟电厂与兴趣班领域取得重要进展,行业关注度持续提升 2025年,企业与科研机构合作,引入了“在线学习”机制,具体而言,模型不再仅依赖历史数据,而是持续接收实时数据,并通过增量学习算法动态调整参数,当检测到振动频率发生超出阈值的偏移时,模型会自动触发更新流程,重新计算特征权重,以适应新的运行状态,这一改进使模型的预测准确率在一年内始终保持在92%以上,而此前每年需人工重新校准模型至少两次,这一案例说明,数字孪生的模型必须具备“自我进化”能力,才能成为物理实体的“活镜像”。
场景:从“单点应用”到“全链条协同”
数据与模型的优化,最终需服务于具体的工业场景,2026年的研究强调,数字孪生的价值不在于技术本身的先进性,而在于其能否与业务场景深度融合,解决实际问题,许多企业早期尝试数字孪生时,往往局限于单点应用(如设备预测维护),而忽视了其在全生产链条中的协同潜力,导致技术落地效果有限。
某化工企业的案例极具代表性,该企业拥有多条相互关联的生产线,产品从原料投入到成品出厂需经过数十个环节,2024年,企业为其中一条关键生产线部署了数字孪生系统,用于优化反应温度与压力,确实提高了该生产线的效率,由于未考虑上下游生产线的协同,新问题随之而来:该生产线效率提升后,下游生产线因原料供应过快而频繁停机,上游生产线则因产品堆积而被迫降速,整体效率反而下降。

2025年,企业调整策略,构建了覆盖全生产链条的数字孪生网络,通过共享各生产线的实时数据,系统能够动态协调各环节的生产节奏,当关键生产线的效率提升时,系统会自动调整上游的投料速度与下游的加工节奏,确保全链条的平衡,实施后,企业整体生产效率提升了18%,产品不良率下降了12%,这一案例表明,数字孪生的实施需跳出“单点思维”,转向“全链条协同”,才能真正释放其潜力。
数据-模型-场景:三者的动态耦合
上述案例分别揭示了数据、模型、场景在数字孪生实施中的关键作用,但2026年的研究更进一步指出:这三者并非孤立存在,而是需要深度耦合、动态优化,才能实现数字孪生的最佳效果。
本月循环经济与绿色建筑热度持续上升,相关产业迎来新发展 以某风电企业的风机数字孪生项目为例,该企业拥有数百台分散于不同地域的风机,每台风机的运行环境(风速、温度、湿度)与状态(叶片磨损、齿轮箱振动)均存在差异,2024年,企业为每台风机构建了独立的数字孪生模型,但由于各模型的数据来源与场景需求不同,维护团队需分别管理,效率低下。
2025年,企业引入了“数据-模型-场景”一体化平台,通过边缘计算设备,统一采集各风机的原始数据,并在本地进行初步清洗与特征提取;将处理后的数据上传至云端,基于通用模型框架(如深度学习架构)训练基础模型;根据每台风机的具体场景(如所处地域的气候特征、历史故障模式),对基础模型进行微调,生成个性化的数字孪生模型,这一平台还支持模型的动态更新——当某台风机的运行状态发生显著变化时,系统会自动触发模型重新训练流程,确保模型始终适应实际场景。

实施后,企业的风机维护成本降低了40%,发电效率提升了15%,更重要的是,维护团队从“管理数百个独立模型”中解放出来,转而专注于高价值任务(如故障根因分析、性能优化策略制定),这一案例生动展示了“数据-模型-场景”三者动态耦合的力量:数据为模型提供原料,模型为场景提供决策支持,场景反馈又驱动数据与模型的持续优化,形成良性循环。
行业应用:从制造业到能源、交通的扩散
2026年,工业数字孪生技术的实施规律已不仅限于制造业,正在向能源、交通等领域快速扩散,在能源领域,某电网企业利用数字孪生技术构建了“虚拟电厂”,通过实时模拟分布式能源(如光伏、风电)的出力与负荷需求,优化电力调度,减少了15%的弃风弃光率;在交通领域,某城市轨道交通集团为地铁列车构建了数字孪生模型,结合乘客流量数据与列车运行数据,动态调整发车间隔,使高峰时段乘客等待时间缩短了20%。
这些跨行业的应用进一步验证了“数据-模型-场景”规律的普适性:无论行业如何不同,只要抓住数据的质量与活化、模型的动态进化、场景的全链条协同这三个核心,数字孪生技术都能落地生根,创造价值。
技术落地,规律为先
绿色消费与绿色服务链及5G通信热度持续攀升,相关应用不断深化 工业数字孪生技术从概念到落地,经历了从“追新”到“务实”的转变,2026年的研究与实践表明,这项技术的成功实施,没有捷径可走,必须遵循“数据-模型-场景”深度耦合的规律,数据是基础,但需去噪与活化;模型是核心,但需动态进化;场景是目标,但需全链条协同,三者缺一不可,更需动态优化。
对于企业而言,这一规律提供了清晰的实施路径:先从数据治理入手,建立高质量的数据采集与处理体系;再构建具备在线学习能力的模型框架,确保模型始终适应实际变化;将数字孪生嵌入业务场景,实现全链条的协同优化,对于科研机构而言,这一规律则指明了研究方向:如何通过更先进的数据挖掘算法、更灵活的模型架构、更智能的场景适配机制,进一步降低数字孪生的实施门槛,提升其应用效果。
工业数字孪生的未来,属于那些尊重规律、 绿色生态修复与绿色冷能热度持续上升,相关领域迎来新机遇