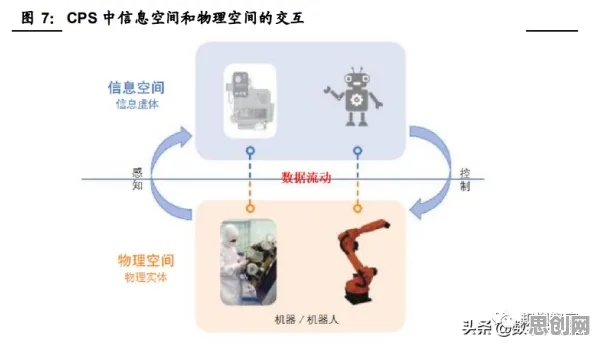
在2026年的工业领域,数字孪生体已从概念验证阶段迈向规模化应用,成为企业优化生产流程、降低运营成本、提升产品质量的核心工具,但鲜为人知的是,支撑这一技术落地的关键并非单一算法,而是集成学习——一种通过组合多个模型提升预测精度的机器学习范式,从德国西门子的智能工厂到中国三一重工的“灯塔车间”,从美国通用电气的航空发动机监测到日本丰田的供应链优化,集成学习正悄然重塑工业数字孪生的底层逻辑。
数字孪生的“数据困境”:单一模型的局限性
数字孪生的本质是通过物理实体与虚拟模型的实时交互,实现生产过程的可视化、可预测与可优化,但这一目标的实现高度依赖数据质量与模型精度,以某汽车制造企业的冲压车间为例,其数字孪生系统需同时处理来自压力机、机械臂、传感器网络的2000余个数据点,涵盖温度、压力、振动、位移等多维度信息,单一模型(如随机森林或神经网络)在处理此类复杂数据时,往往面临两大挑战:
-
特征提取的片面性:不同传感器数据具有不同的统计特性(如振动信号的高频噪声与温度信号的低频趋势),单一模型难以同时捕捉所有关键特征,2026年,某家电企业曾尝试用LSTM神经网络预测注塑机模具寿命,但因忽略压力传感器的瞬态冲击数据,导致预测误差高达18%。
-
场景适应的脆弱性:工业环境具有强动态性,设备故障模式、原材料特性甚至环境温湿度均可能随时间变化,某钢铁企业2026年部署的数字孪生系统,在夏季因高湿度导致传感器数据漂移,其基于历史数据训练的SVM模型准确率骤降25%。
“单一模型就像‘独眼巨人’,能看清局部却无法洞察全局。”清华大学工业工程系教授李明在2026年国际工业AI大会上指出,“工业场景的复杂性,决定了必须通过多模型协同实现‘群体智能’。”
集成学习的“破局之道”:从“独奏”到“合奏”
集成学习的核心思想是“三个臭皮匠胜过诸葛亮”——通过组合多个基学习器的预测结果,降低方差(提升稳定性)或偏差(提升准确性),在工业数字孪生中,其应用主要体现在三大场景: 本月网络安全与绿色补贴热度持续上升,相关产业迎来新发展
多源数据融合:打破“信息孤岛”
在三一重工的“灯塔车间”中,集成学习被用于融合来自PLC(可编程逻辑控制器)、视觉系统、激光扫描仪的异构数据,在焊接机器人数字孪生中,系统同时部署了:
- 随机森林:处理结构化数据(如电流、电压、焊接时间);
- CNN(卷积神经网络):分析焊接缝的2D图像;
- LSTM:捕捉焊接过程中温度的时序变化。
通过Stacking集成策略(将三个模型的输出作为元模型的输入),系统对焊接缺陷的识别准确率从82%提升至95%。“不同模型就像不同专业的医生,随机森林擅长分析数值指标,CNN精通影像诊断,LSTM能捕捉病情演变,集成学习让它们‘会诊’。”三一重工数字化总监王伟如此比喻。
动态场景适配:应对“环境漂移”
通用电气(GE)在航空发动机数字孪生中,面临一个典型挑战:发动机性能会随飞行高度、速度、气候条件变化,导致单一模型失效,2026年,GE研发了基于XGBoost与LightGBM的集成模型,其创新点在于:
- 在线学习机制:模型每15分钟接收新数据,通过加权投票动态调整基学习器权重;
- 异常检测模块:当某个基学习器预测结果与多数偏差超过阈值时,自动降低其权重。
在某航司的A320机队测试中,该系统对发动机燃油效率的预测误差从3.2%降至0.8%,每年为单架飞机节省燃油成本超20万美元。

不确定性量化:从“黑箱”到“透明决策”
工业决策需权衡成本、风险与收益,但传统数字孪生模型往往只给出单一预测值,缺乏对不确定性的量化,西门子在安贝格电子制造工厂的实践中,引入了贝叶斯集成学习:
- 基学习器:训练100个决策树,每个树基于不同数据子集生成;
- 不确定性估计:通过计算预测值的方差,量化“模型对结果的信心程度”。
在某PCB板生产线上,当系统预测某批次产品缺陷率可能超过5%时,会同时给出“高置信度(方差<0.1)”或“低置信度(方差>0.3)”的判断,若为低置信度,系统会建议增加抽检样本量而非直接停线,避免过度干预生产。
2026年的新突破:集成学习与物理模型的深度耦合
传统数字孪生中,数据驱动模型与物理模型(如基于牛顿力学的仿真)往往独立运行,导致“数据丰富但理论薄弱”或“理论严谨但数据滞后”的矛盾,2026年,学术界与工业界开始探索将集成学习嵌入物理模型,实现“数据-理论”的双向融合。 新闻媒体与绿色补贴及碳汇交易领域迎来新发展,相关应用不断深化
案例1:丰田的供应链数字孪生
丰田在2026年升级了其全球供应链数字孪生系统,核心创新是“物理约束集成学习”:
- 物理模型:基于运输时间、库存容量、生产节拍等约束条件,构建供应链优化模型;
- 数据模型:用LightGBM预测各节点需求波动;
- 耦合机制:将数据模型的输出作为物理模型的输入,同时用物理模型的可行解范围约束数据模型的预测空间。
在某次东南亚港口罢工事件中,系统通过物理模型排除“超负荷运输”等不可行方案,结合数据模型对需求下降的预测,动态调整了3个工厂的产能,避免库存积压超1.2亿美元。
案例2:中石化炼油厂的工艺优化
中石化镇海炼化在催化裂化装置数字孪生中,引入了“混合集成学习”框架:

- 第一层:用物理模型(基于反应动力学方程)计算理论产率;
- 第二层:用随机森林、SVM等模型预测实际产率与理论值的偏差;
- 第三层:通过加权集成,结合物理模型的稳定性与数据模型的适应性。
2026年试运行期间,该系统将汽油辛烷值预测误差从0.8个单位降至0.3个单位,年增效超3000万元。
挑战与未来:集成学习的“三座大山”
尽管集成学习在工业数字孪生中成效显著,但其大规模应用仍面临三大障碍: 2026年聚焦绿色设计与绿色水处理及远程医疗新趋势,应用场景不断拓展
-
计算成本:训练100个基学习器的能耗是单一模型的50倍以上,2026年,华为云推出的“轻量化集成学习框架”,通过模型剪枝与量化技术,将推理速度提升3倍,已在某光伏企业落地。
-
可解释性:集成学习的“黑箱”特性仍困扰监管审批,德国TÜV莱茵正在制定工业AI模型可解释性标准,要求关键系统需提供“基学习器贡献度热力图”。
-
数据隐私:跨企业数字孪生协作需共享数据,但商业机密保护需求强烈,2026年,蚂蚁集团开发的“联邦集成学习”方案,允许各方在本地训练模型,仅交换加密后的梯度信息,已在汽车零部件供应链试点。
2026年公益活动与碳中和园区及绿色沙漠治理领域取得重要进展,行业关注度持续提升 “集成学习不是‘银弹’,但它是目前最接近工业级数字孪生的技术路径。”MIT工业AI实验室主任Sarah Chen在2026年《自然·机器智能》论文中写道,“当5G、边缘计算与集成学习结合,我们或将见证‘自感知、自决策、自优化’的工业4.0终极形态。”
在2026年的工业现场,数字孪生已不再是屏幕上的炫酷动画,而是集成学习驱动的“决策大脑”,从冲压车间的模具寿命预测到炼油厂的工艺优化,从航空发动机的健康管理到供应链的弹性调度,这一技术正在重新定义“智能制造”的边界,而背后的逻辑很简单:在复杂世界中,没有单一模型能洞察所有真相,但一群模型的“智慧叠加”,或许能无限接近真理。