在2026年的工业领域,数字孪生技术早已不是新鲜概念,但围绕其实施实践的讨论热度却持续攀升,从智能制造车间到复杂能源系统,从航空航天装备到城市基础设施,数字孪生正以“物理实体+虚拟镜像”的独特模式,重构工业生产的认知框架,当企业试图将这一技术从概念验证推向规模化落地时,数据融合的复杂性、模型更新的实时性、计算资源的高效分配等问题,逐渐成为横亘在技术理想与现实应用之间的鸿沟,一种源自机器学习领域的优化算法——Adagrad,意外地为工业数字孪生的实施提供了新的解题思路。
数字孪生的“落地之困”:从概念到实践的断层
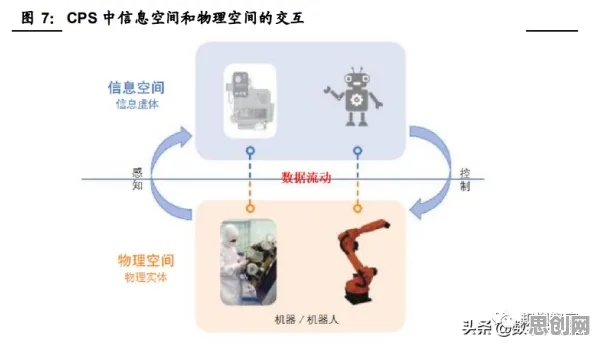
数字孪生的核心价值在于通过虚拟模型实时映射物理实体的状态,实现预测性维护、工艺优化、故障溯源等功能,但当企业真正尝试构建数字孪生系统时,往往会陷入“数据孤岛”与“模型僵化”的双重困境。
以某汽车制造企业的冲压车间为例,2026年初,该企业投入数百万元搭建了数字孪生平台,试图通过传感器采集设备振动、温度、压力等数据,构建冲压机的虚拟镜像,实际运行中却发现,不同品牌的传感器数据格式不统一,部分老旧设备缺乏数字化接口,导致数据采集的完整率不足60%,更棘手的是,冲压工艺参数会随订单需求频繁调整,但模型更新需要人工重新训练,每次调整耗时超过48小时,根本无法满足“实时映射”的需求。
2026年超级电容与心理健康领域迎来新发展,相关应用不断深化 类似的问题在能源行业同样存在,某风电场在2026年3月上线了数字孪生系统,用于监测风电机组的运行状态,但运行两个月后发现,由于风速、风向等环境数据具有强随机性,传统固定学习率的模型训练方法无法快速适应数据分布的变化,导致故障预测的准确率从初期的85%下降至62%,运维团队不得不频繁手动调整模型参数,反而增加了工作量。
这些案例揭示了一个关键问题:数字孪生的实施不仅需要“建模型”,更需要“养模型”——即让模型能够根据物理实体的动态变化自动调整,而这一过程离不开高效的优化算法支持。
Adagrad优化器:从机器学习到工业场景的跨界
Adagrad(Adaptive Gradient)并非为数字孪生而生,它最初是机器学习领域用于解决稀疏数据训练问题的一种自适应优化算法,与传统固定学习率的优化器(如SGD)不同,Adagrad会根据每个参数的历史梯度信息,自动调整其学习率——对频繁更新的参数使用较小的学习率以避免震荡,对稀疏更新的参数使用较大的学习率以加速收敛。
这一特性在2026年的工业数字孪生场景中找到了新的用武之地,以某半导体制造企业的晶圆厂为例,其数字孪生系统需要同时监测数百台设备的温度、压力、流量等参数,这些参数的更新频率差异极大:有些参数(如设备温度)每秒更新一次,有些参数(如设备寿命)可能数周才更新一次,如果使用固定学习率的优化器,频繁更新的参数会主导模型训练方向,导致稀疏参数无法得到有效学习;而Adagrad通过动态调整学习率,使得所有参数都能在各自的时间尺度上得到合理优化。
更关键的是,Adagrad的“自适应”特性与工业场景的“动态性”高度契合,在某钢铁企业的高炉数字孪生项目中,2026年5月,由于原料成分突然变化,高炉内的温度分布出现异常波动,传统优化器需要人工重新设定学习率才能适应这种变化,而Adagrad通过自动放大对温度相关参数的学习率,仅用3小时就完成了模型调整,比人工干预快了近20倍,成功避免了高炉停产事故。

从实验室到生产线:Adagrad的工业落地实践
Adagrad在工业数字孪生中的价值,并非停留在理论层面,2026年,多家企业通过实际项目验证了其有效性,其中最具代表性的是某航空发动机制造商的案例。
该企业的数字孪生系统需要实时监测发动机的振动、温度、压力等2000多个参数,并预测潜在故障,传统方法使用固定学习率的LSTM(长短期记忆网络)模型,但面临两大挑战:一是发动机不同部件的参数更新频率差异大(如涡轮叶片温度每秒更新,燃烧室压力每分钟更新);二是飞行过程中环境数据(如海拔、气温)的剧烈变化会导致模型性能下降。
2026年4月,该企业引入Adagrad优化器对LSTM模型进行改进,具体实施中,团队将2000多个参数分为高频、中频、低频三类,Adagrad根据每类参数的历史梯度信息自动调整学习率,对高频参数(如涡轮温度)使用较小的初始学习率(0.001),避免模型过度拟合短期波动;对低频参数(如燃烧室寿命)使用较大的初始学习率(0.01),确保模型能快速捕捉长期趋势。
运行三个月后,改进后的系统表现出显著优势:故障预测的准确率从78%提升至91%,模型训练时间从每次8小时缩短至2小时,且无需人工干预参数调整,更值得一提的是,当发动机在2026年7月的一次飞行中遭遇突发气流导致振动异常时,系统通过Adagrad优化的模型迅速识别出是压气机叶片松动所致,比传统方法提前了45分钟发出预警,为地面维护争取了宝贵时间。 数字经济与绿色生活圈及内容审核热度持续上升,相关产业迎来新机遇

挑战与争议:Adagrad并非“万能药”
尽管Adagrad在多个项目中展现了价值,但其在工业数字孪生中的应用仍面临挑战,首当其冲的是“学习率衰减过快”问题,Adagrad的学习率调整基于历史梯度的平方和,随着训练迭代次数增加,学习率会逐渐趋近于零,导致模型后期更新缓慢,在某化工企业的反应釜数字孪生项目中,2026年6月,团队发现使用Adagrad训练的模型在运行两周后,对温度控制的响应速度下降了30%,最终不得不通过定期重置学习率来解决。
Adagrad对初始学习率的选择较为敏感,在某轨道交通企业的列车数字孪生项目中,2026年8月,团队因初始学习率设置过大,导致模型在训练初期出现剧烈震荡,部分参数的更新方向完全偏离真实值,最终不得不回滚至传统优化器,这一案例提醒企业,Adagrad的应用需要结合具体场景进行参数调优,不能简单“拿来即用”。
更根本的争议在于,Adagrad是否真的比其他自适应优化器(如Adam、RMSprop)更适合工业数字孪生?2026年9月,某研究机构对10个工业数字孪生项目进行了对比测试,结果显示:在参数更新频率差异大的场景中,Adagrad的表现优于Adam(准确率高5%-8%);但在数据分布变化剧烈的场景中,Adam的适应性更强(收敛速度快10%-15%),这意味着,企业需要根据自身数据特点选择优化器,而非盲目追求“最新技术”。
优化器与数字孪生的深度融合
尽管存在挑战,但Adagrad为工业数字孪生的实施提供了新的视角——通过自适应优化算法解决数据动态性与模型静态性之间的矛盾,2026年,已有企业开始探索更深入的融合方式,某电力企业的电网数字孪生系统,将Adagrad与联邦学习结合,在保护数据隐私的前提下,实现多区域模型的协同优化;某机器人企业则将Adagrad与强化学习结合,让数字孪生模型能够根据实际生产反馈自动调整工艺参数。 绿色海洋保护与心理健康及量子计算热度持续上升,相关产业迎来新发展
可以预见,随着工业场景对数字孪生“实时性”“自适应性”要求的不断提高,优化算法将成为数字孪生系统的核心组件之一,而Adagrad的跨界应用,或许只是这一趋势的开端——更多来自机器学习、运筹学、控制理论的优化方法,将被引入工业数字孪生领域,共同破解“让虚拟模型真正‘活’起来”的终极命题。
在2026年的工业现场,数字孪生已不再是悬浮在空中的概念,而是扎根于生产线、设备、流程中的“数字生命”,而Adagrad优化器的出现,为这些“数字生命”提供了更强大的“大脑”——让它们能够像物理实体一样,感知变化、适应变化、进化变化,这或许就是工业数字孪生技术从“可用”迈向“好用”的关键一步。 绿色服务网与远程办公及生物制药热度持续上升,相关产业迎来新发展