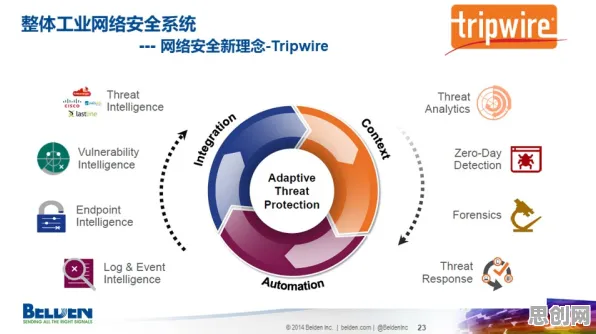
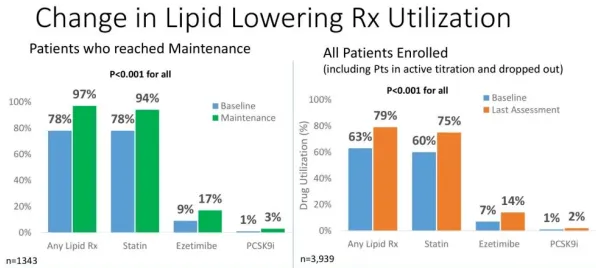
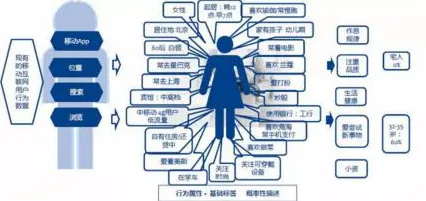
2026年的科技圈,大模型技术早已不是新鲜词,从OpenAI的GPT系列到国内百度的文心、阿里的通义,再到华为的盘古,全球科技巨头和初创企业都在这个赛道上疯狂角逐,但当我们把目光从技术本身移开,用发展心理学的视角去审视这场技术狂潮时,会发现一个有趣的现象——沉没成本效应,正在悄然推动着大模型技术的持续爆发。
什么是沉没成本效应?先讲个生活中的例子
想象一下,你花500元买了一张演唱会门票,结果当天突然下雨,天气预报说会持续到深夜,你站在场馆外,看着瓢泼大雨,心里开始纠结:去还是不去?去的话,要淋雨、可能感冒,体验肯定不好;不去的话,500元就打水漂了,很多人会选择“咬咬牙”进去,哪怕只是坐一会儿——这就是沉没成本效应在作祟。
发展心理学中的沉没成本效应,指的是人们在决策时,会因为已经投入的时间、金钱、精力等不可回收成本,而继续坚持原本可能不合理的选择,甚至加大投入,这种心理机制,原本用于解释个人行为,但在2026年的大模型技术领域,却成了推动行业爆发的“隐形推手”。
科技巨头的“沉没成本”:从百亿研发到千亿生态
2026年,全球大模型技术的竞争已经进入“深水区”,以OpenAI为例,从GPT-3到GPT-5,其研发成本累计超过200亿美元(据《华尔街日报》2026年3月报道),这些钱花在哪里了?算力、数据、人才——买GPU、租数据中心、雇佣全球顶尖的AI科学家,每一项都是天文数字。
但更关键的是,这些投入不是“一次性”的,大模型的训练需要持续迭代,每次升级都要新的数据、更强的算力,GPT-5的训练用了10万块A100 GPU,耗时3个月,电费就花了1.2亿美元(据《麻省理工科技评论》2026年5月报道),这些成本一旦投入,就变成了“沉没成本”——如果停止研发,之前的钱就白花了;如果继续,至少还有“翻盘”的可能。
2026年氢能技术与零碳工厂及社区养老热度持续攀升,相关应用不断深化 国内企业也不例外,百度的文心大模型,从2019年启动研发,到2026年已经迭代到4.5版本,累计投入超过150亿元(据百度2026年财报),阿里云的通义大模型,更是与电商、物流、金融等业务深度绑定,形成了“技术-应用-反馈”的闭环,阿里CTO王坚在2026年世界人工智能大会上直言:“大模型不是选择题,是必答题,我们已经投了这么多,不可能回头。”
这种“不能回头”的心理,正是沉没成本效应的体现,科技巨头们不是不知道大模型技术存在风险——算力成本高、数据隐私难解决、商业落地不确定,但已经投入的巨额成本,让他们不得不继续“押注”,甚至加大投入,以避免“前功尽弃”。
初创企业的“沉没成本”:从融资烧钱到生死博弈
如果说科技巨头是“财大气粗”的玩家,那么初创企业就是“背水一战”的赌徒,2026年,全球大模型初创企业超过5000家,其中90%以上处于亏损状态(据CB Insights 2026年Q2报告),这些企业靠什么活下去?融资——烧钱——再融资——再烧钱。
以美国初创企业Inflection AI为例,2023年成立时,凭借创始人Mustafa Suleyman(DeepMind联合创始人)的光环,迅速融到15亿美元,但到2026年,其大模型Pi的商业化进展缓慢,用户增长停滞,估值从巅峰的40亿美元跌至15亿美元(据《福布斯》2026年7月报道),Inflection AI面临两个选择:要么裁员、缩减规模,承认失败;要么继续融资,赌一把“逆袭”。
他们选择了后者,2026年8月,Inflection AI宣布完成新一轮5亿美元融资,领投方是微软,这笔钱怎么用?继续训练模型、扩大团队、补贴用户,为什么?因为如果现在放弃,之前的15亿美元就彻底打水漂了;如果继续,至少还有“被收购”或“上市”的希望。

国内的情况类似,2026年,国内大模型初创企业“智谱AI”完成B+轮融资,金额达8亿元,其创始人张鹏在融资发布会上坦言:“我们不是不知道竞争激烈,但已经投了这么多,团队、技术、用户都在这,不能半途而废。”这种“不能半途而废”的心理,正是沉没成本效应的典型表现。
开发者的“沉没成本”:从学习曲线到职业绑定
大模型技术的爆发,不仅影响了企业,也改变了开发者的职业轨迹,2026年,全球大模型相关开发者超过500万人(据LinkedIn 2026年数据),其中70%是从其他领域(如传统软件、数据分析)转型而来,这些开发者为什么选择大模型?因为“已经学了,不能浪费”。
以32岁的李明为例,他原本是一名Java工程师,2023年看到大模型热潮,花3万元报了培训班,学了3个月PyTorch和Transformer架构,2026年,他已经在一家AI公司做模型调优,月薪从之前的2万涨到4万,但他说:“其实压力很大,因为如果现在转行,之前的3万学费、1年时间就白费了;如果不转,又担心技术迭代太快,被淘汰。”
这种“不能浪费”的心理,让大量开发者主动或被动地绑定在大模型赛道上,他们不断学习新框架(如2026年流行的Meta的Llama 3.5架构)、新工具(如Hugging Face的Transformers库),甚至考取相关认证(如AWS的机器学习专项认证),这些投入,进一步加深了他们的“沉没成本”,让他们更难跳出这个领域。
用户的“沉没成本”:从试用到依赖
大模型技术的爆发,最终要靠用户买单,2026年,全球大模型用户超过10亿(据Statista 2026年数据),其中60%是企业用户,40%是个人用户,这些用户为什么持续使用大模型?因为“已经用了,换起来麻烦”。

以企业用户为例,2026年,某制造企业花50万元采购了阿里云的通义大模型,用于供应链优化,使用3个月后,他们发现模型确实能降低10%的库存成本,但同时也面临问题:数据迁移困难、员工培训成本高、与现有系统兼容性差,企业面临两个选择:要么继续用,接受这些“小毛病”;要么换其他模型,重新走一遍采购、部署、培训的流程。
他们选择了继续用,因为“已经投了50万,换的话又要花50万,不值得”,这种“不值得”的心理,正是沉没成本效应的体现,个人用户也一样——你已经在某个大模型平台上积累了1000次对话记录、50个自定义指令,换平台意味着这些“资产”清零,所以你会继续用下去。 本月环境监测与人工智能技术及绿色转化热度持续上升,相关领域迎来新发展
沉没成本效应的“双刃剑”:推动爆发,也制造泡沫
沉没成本效应解释了大模型技术的持续爆发,但也带来了一个问题——泡沫,2026年,全球大模型相关融资超过500亿美元,但真正盈利的企业不足10%(据PitchBook 2026年数据),大量企业靠“烧钱”维持,一旦融资受阻,就会迅速崩盘。
2026年6月,美国大模型初创企业Adept宣布破产,这家公司曾估值20亿美元,但因为商业化进展缓慢,无法覆盖研发成本,最终被收购,其创始人David Luan在破产声明中承认:“我们太执着于模型性能,忽略了成本和落地,导致沉没成本越来越高,无法回头。”
国内也有类似案例,2026年9月,某国内大模型企业被曝出“数据造假”——为了吸引投资,他们虚构了用户增长数据,事后调查发现,该公司因为前期投入太大,无法完成对赌协议,只能铤而走险,这种“为了掩盖沉没成本而造假”的行为,正是沉没成本效应的负面体现。
沉没成本不是借口,而是动力
2026年的大模型技术领域,沉没成本效应无处不在,它让科技巨头继续“押注”,让初创企业“背水一战”,让开发者“绑定赛道”,让用户“持续依赖”,但沉没成本不是借口——企业不能因为投了钱就盲目坚持,开发者不能因为学了技术就拒绝更新,用户不能因为用了平台就忽视体验。