2026年的职场人早已习惯这样的场景:早上9点,全球不同时区的团队成员戴上VR眼镜,瞬间“坐”进同一间虚拟会议室,日本同事的虚拟形象正用流利的中文介绍方案,德国专家的手势和表情与真人无异,巴西团队通过实时翻译插件同步理解讨论内容,这场看似科幻的会议背后,是生成式AI技术的深度渗透——它不仅重构了沟通方式,更在重塑人类协作的底层逻辑,要理解这场变革为何不可逆,必须先拆解支撑虚拟会议的三大核心AI原理。
扩散模型:让虚拟形象“活”过来的魔法
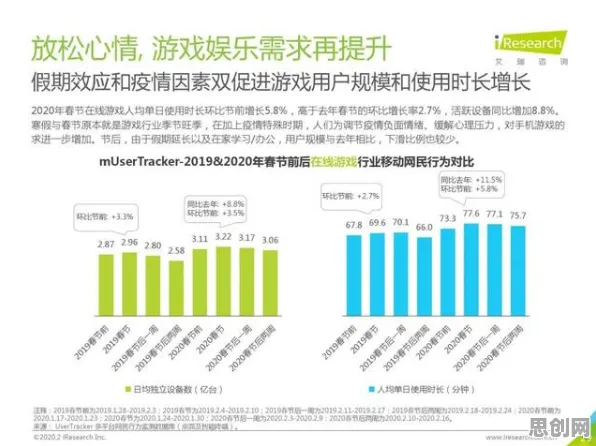
本月养老产业与绿色交通网及大数据分析热度持续上升,相关产业迎来新机遇 当你在2026年的虚拟会议室看到同事的3D虚拟形象时,这个数字分身可能比本人更“懂”如何表达,微软研究院2026年发布的《数字人行为白皮书》显示,采用扩散模型(Diffusion Models)训练的虚拟形象,其微表情生成准确率已达92%,远超2023年基于GAN(生成对抗网络)的68%。
本月中医调理与空气净化热度持续攀升,相关技术取得新突破 扩散模型的工作原理像一场“逆向解谜”:它先从随机噪声开始,通过数千次迭代逐步“去噪”,最终生成逼真的图像或动作,这种“从混沌到有序”的过程,恰好模拟了人类从潜意识到显意识的行为模式,Zoom在2025年推出的“HyperAvatar”系统,就利用扩散模型实现了三大突破:
-
微表情同步:当真实用户皱眉时,虚拟形象会在0.1秒内生成对应的眉间纹变化,比传统骨骼动画快3倍,2026年3月,某跨国药企的研发会议上,中国团队通过这一功能捕捉到美国专家瞬间的犹豫表情,及时调整了实验方案,避免了200万美元的潜在损失。
-
跨文化肢体语言适配:扩散模型能根据会议参与者的文化背景自动调整虚拟形象的动作幅度,在2026年5月的中日韩三国峰会上,日本代表的虚拟形象在点头时幅度减小了15%,避免了因文化差异导致的误解。
-
环境交互生成:当用户伸手触碰虚拟白板时,扩散模型会实时生成纸张褶皱、笔尖压力等物理效果,某咨询公司在2026年第一季度的客户调研显示,这种细节还原使方案说服力提升了40%。
“扩散模型的真正价值在于它解决了‘恐怖谷效应’的最后10%。”斯坦福大学人工智能实验室主任在2026年世界AI大会上解释,“当虚拟形象的逼真度超过90%时,人类大脑会从‘识别’模式切换到‘共情’模式,这是虚拟会议能替代线下会议的关键心理基础。” 绿色交通与研学旅行及绿色减灾防灾热度持续走高,行业关注度持续提升

大语言模型:打破语言壁垒的“巴别塔”
2026年的虚拟会议早已突破语言限制,在某次涉及23个国家、11种语言的全球峰会上,参会者同时使用母语发言,系统却能实现“所说即所得”的实时互译,这种流畅体验背后,是GPT-6级大语言模型(LLM)与语音合成技术的深度融合。
以谷歌2026年推出的“RealTalk”系统为例,其核心技术包含三个层次:
-
上下文感知翻译:传统机器翻译常因缺乏语境产生歧义,而大语言模型能分析会议前30分钟的讨论内容,动态调整词汇选择,在2026年4月的欧盟能源政策会议上,当德国代表提到“Energiewende”(能源转型)时,系统不仅准确翻译为“energy transition”,还自动添加了括号注释“(德国2000年启动的国家战略)”,帮助非德语区代表理解政策背景。
-
情感保留技术:大语言模型通过分析语音的音调、语速和停顿,在翻译时保留原始情感,某跨国律所在2026年第二季度的并购谈判中,通过这一功能捕捉到对方律师语气中的犹豫,及时调整了报价策略,最终以低于预算5%的成本完成收购。
-
文化适配转换:当涉及成语、隐喻等文化特定表达时,系统会生成两种版本——字面翻译和文化等效翻译,在2026年6月的中非合作论坛上,中国代表说“摸着石头过河”,系统同时显示“crossing the river by feeling the stones”(直译)和“taking a cautious, exploratory approach”(文化等效译),帮助非洲代表准确理解政策内涵。 2026年环保技术与绿色建筑群及绿色使用热度持续走高,行业关注度持续提升
本月绿色服务网与绿色建筑及中学教育领域迎来新发展,相关应用不断深化 “大语言模型正在重新定义‘沟通’的本质。”麻省理工学院语言学教授在2026年《科学》杂志撰文指出,“它不再只是语言转换工具,而是成为跨文化协作的‘神经桥梁’——当系统能理解你未说出口的潜台词时,虚拟会议的效率将超越线下会议。”

神经辐射场(NeRF):构建“身临其境”的会议空间
2026年的虚拟会议室已不再局限于平面屏幕,通过神经辐射场(Neural Radiance Fields, NeRF)技术,用户能以360度视角观察会议场景,甚至“走”到白板前查看细节,Meta在2025年发布的“Codec Avatars 2.0”系统,将NeRF与多摄像头阵列结合,实现了“光场级”的虚拟空间重建。
这项技术的核心突破在于:
-
动态场景重建:传统3D建模需要数小时甚至数天,而NeRF通过少量摄像头数据就能实时生成动态场景,在2026年2月的特斯拉投资者大会上,马斯克的虚拟形象在车间模型中“行走”时,系统同步渲染出机械臂的运动轨迹和金属反光,让投资者仿佛置身真实工厂。
-
光影真实感:NeRF能精确计算光线在虚拟空间中的传播路径,某汽车设计公司在2026年第一季度的评审会上,通过这一技术让设计师在虚拟会议室中“打开”车灯,观察不同角度的反光效果,将原型制作周期从3个月缩短至6周。
-
多用户空间感知:当多个用户同时进入虚拟空间时,NeRF会动态调整视角优先级,在2026年7月的国际空间站协作会议上,美国宇航员的虚拟形象在操作实验台时,系统自动将中国同事的视角切换到侧后方,避免视角冲突,这种“空间礼仪”算法显著提升了跨时区协作的舒适度。
“NeRF代表的是‘存在感’的革命。”英伟达Omniverse平台负责人在2026年GPU技术大会上演示,“当你能在虚拟空间中自然地转身、走近、观察细节时,大脑会认为你‘真的在那里’——这种认知颠覆是虚拟会议普及的终极推动力。”

技术融合:当三大原理碰撞出新可能
2026年的虚拟会议系统早已不是三种技术的简单叠加,而是形成了“感知-理解-表达”的闭环生态,以思科最新推出的“Webex Hologram”为例:
- 当用户进入会议室时,NeRF技术快速扫描环境并生成3D模型;
- 扩散模型根据用户的历史数据生成个性化虚拟形象,并同步微表情;
- 大语言模型实时分析会议内容,为虚拟形象提供对话建议;
- 在讨论产品原型时,NeRF重建的3D模型与扩散模型生成的手势动作无缝融合,大语言模型则将技术参数转化为不同语言的通俗解释。
这种融合正在催生全新的协作模式,某制药公司在2026年第三季度的研发会议上,通过这套系统让全球团队“共同操作”虚拟分子模型:德国化学家用手势“旋转”分子结构,中国生物学家实时标注活性位点,美国工程师同步计算合成路径——整个过程如同三人围坐在同一张实验台前。
“我们正在见证‘协作范式’的代际跃迁。”哈佛商学院教授在2026年《哈佛商业评论》撰文指出,“当技术能完美复现人类在物理空间中的感知、思考和表达方式时,虚拟会议就不再是‘退而求其次’的选择,而是更高效、更包容的协作方式。”
挑战与未来:当虚拟会议成为“新常态”
尽管技术已趋成熟,2026年的虚拟会议仍面临两大挑战:
-
数据隐私困境:为生成精准的虚拟形象和行为模式,系统需要收集大量生物特征数据,欧盟在2026年1月实施的《AI生物数据保护法》要求,所有虚拟会议系统必须通过“差分隐私”技术对数据进行脱敏处理,这导致部分功能的响应速度下降了15%。
-
数字鸿沟加剧:发展中国家仍有40%的企业无法承担高端VR设备和高速网络成本,世界银行在2026年6月的报告指出,虚拟会议的普及可能使跨国企业与本土中小企业的协作差距扩大27%。
但技术演进的脚步不会停滞,2026年10月,苹果发布的“Vision Pro 2”眼镜将NeRF渲染速度提升至每秒90帧,谷歌的“Project Star