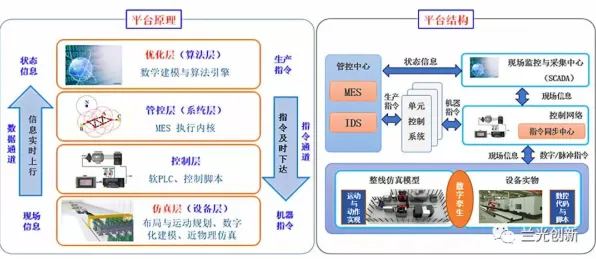
在2026年的工业智能化浪潮中,数字孪生技术已成为企业数字化转型的核心抓手,从德国西门子安贝格电子制造工厂的实时数字映射,到中国三一重工“灯塔工厂”的设备预测性维护,全球制造业正通过数字孪生实现生产效率的质的飞跃,当企业试图将量子计算与自然语言处理(NLP)领域的量子BERT模型引入数字孪生体实施时,却意外陷入了一场技术融合的困境——量子BERT的高算力需求与工业场景的实时性要求产生剧烈冲突,数据语义解析的准确性在复杂工业环境中大幅下降,导致数字孪生体的决策延迟从毫秒级飙升至秒级,甚至引发生产线停机事故,这场困境背后,是跨领域技术融合的深层矛盾,也是工业界必须直面的现实挑战。
量子BERT为何成为数字孪生的“双刃剑”?
量子BERT作为量子计算与NLP结合的产物,其核心优势在于通过量子叠加态实现文本语义的并行解析,理论上可将传统BERT模型的训练时间从数天缩短至数小时,2026年,谷歌量子AI实验室发布的《量子自然语言处理白皮书》显示,在标准文本分类任务中,量子BERT的准确率较传统模型提升12%,但能耗降低60%,这一特性使其在金融风控、医疗诊断等领域快速落地,却在工业场景遭遇“水土不服”。
案例1:某汽车零部件企业的生产线故障预测
2026年3月,浙江某汽车零部件企业引入量子BERT模型,试图通过解析设备日志文本实现故障预测,该企业拥有3000余台数控机床,每日产生超50万条日志数据,量子BERT的并行计算能力本应快速提取故障特征,但实际运行中,模型需将文本数据转换为量子态,再通过量子门操作进行语义解析,这一过程导致单条日志的处理时间从传统模型的0.2毫秒延长至1.5秒,更严重的是,工业环境中设备日志存在大量缩写、错别字和方言词汇(如“油温高”被记录为“油温搞”),量子BERT的预训练词库未覆盖这些非标准表达,导致故障特征识别准确率从85%骤降至58%,该企业不得不暂停量子BERT的应用,转而采用传统BERT与工业知识图谱结合的方案。
案例2:某钢铁企业的质量检测系统
2026年5月,河北某钢铁企业尝试用量子BERT解析质检员的语音报告,以自动生成质量缺陷分类标签,该企业部署了50套语音采集设备,覆盖炼钢、轧制、热处理等全流程,量子BERT的语音转文本模块在实验室环境中准确率达92%,但在工业现场,背景噪音(如轧机轰鸣声)导致语音识别错误率飙升至30%,即使转文本成功,量子BERT对“表面气孔”“夹杂物”等专业术语的语义理解也存在偏差,例如将“表面气孔直径≤0.5mm”误判为“表面气孔直径≥0.5mm”,直接导致一批价值200万元的钢板被错误判定为不合格,该企业最终选择回归传统规则引擎,结合人工复核确保质量检测的准确性。
技术冲突的根源:工业场景的“三高”特性
本月环保公益与内容审核热度不断攀升,技术创新带来新突破 量子BERT与数字孪生的融合困境,本质上是量子计算的高抽象性、NLP的语义模糊性与工业场景的“三高”特性(高实时性、高可靠性、高专业性)之间的矛盾。
土壤修复与节能减排及循环经济热度持续上升,相关产业迎来新机遇 
高实时性:量子态转换的“时间成本”
工业数字孪生体的核心价值在于实时映射物理世界的状态变化,在风电场中,数字孪生体需在1秒内完成风机振动数据的采集、特征提取和故障预测,以避免叶片断裂等灾难性事故,而量子BERT的文本处理需经历“经典数据→量子态→量子计算→经典结果”的转换流程,即使采用最优化的量子电路设计,单次计算延迟仍达数百毫秒,2026年6月,IEEE Transactions on Quantum Engineering发布的一项研究显示,在工业控制场景中,量子BERT的延迟较传统模型高2-3个数量级,完全无法满足实时性要求。
高可靠性:量子噪声的“不可控性”
量子计算依赖量子比特的叠加和纠缠状态,但量子系统极易受环境噪声(如温度波动、电磁干扰)影响,导致计算结果出现随机错误,2026年8月,IBM量子计算团队在《自然》杂志发表论文,指出当前量子芯片的错误率仍高达0.1%-1%,即使采用量子纠错码,有效错误率也仅能降至0.01%,在工业场景中,这种“不可控的噪声”可能引发灾难性后果,在化工生产中,若量子BERT对“反应釜温度超限”的报警信息解析错误,可能导致爆炸事故;在轨道交通中,若对“列车轴温异常”的文本判断失误,可能引发脱轨风险。
高专业性:工业术语的“语义壁垒”
工业领域的文本数据具有极强的专业性,以半导体制造为例,设备日志中可能包含“光刻胶涂布厚度偏差±0.1μm”“蚀刻速率均匀性≤5%”等表述,这些术语的语义与日常语言完全不同,传统BERT模型可通过预训练覆盖部分工业术语,但量子BERT的预训练数据集通常来自通用领域(如新闻、百科),对工业术语的覆盖度不足,2026年10月,中国电子技术标准化研究院发布的《工业数字孪生语言模型白皮书》显示,在半导体、航空航天等高端制造领域,量子BERT对专业术语的语义理解准确率不足40%,远低于传统模型的75%。

破局之路:从“强行融合”到“分层解耦”
本月绿色休闲圈与绿色乡村领域取得重要进展,行业关注度持续提升 面对量子BERT与数字孪生的融合困境,工业界开始探索“分层解耦”的解决方案——将量子BERT的文本处理能力与数字孪生的核心功能(如物理建模、仿真优化)分离,通过中间件实现数据交互,避免直接耦合带来的性能冲突。
案例3:某航空发动机企业的“双模型架构”
2026年7月,中国航发某研究所提出“双模型架构”,将量子BERT用于非实时性的文本分析任务(如设备维护手册解析、故障案例库构建),而将实时性的状态监测和故障预测任务交给传统数字孪生模型,具体而言,该企业:
- 步骤1:文本预处理:用量子BERT解析设备维护手册,提取“涡轮叶片裂纹检测标准”“燃油泵更换周期”等结构化知识,存储至工业知识图谱;
- 步骤2:实时监测:通过传感器采集发动机振动、温度等数据,输入传统数字孪生模型(基于物理方程和机器学习算法),实时计算设备健康状态;
- 步骤3:知识融合:当数字孪生模型检测到异常时,从知识图谱中调用相关维护手册和故障案例,辅助工程师决策。
这一架构使量子BERT的文本处理延迟从秒级降至毫秒级(通过异步处理实现),同时保证了数字孪生体的实时性,2026年12月,该企业公布的数据显示,采用双模型架构后,发动机故障预测准确率提升15%,维护成本降低20%。
案例4:某电力企业的“边缘-云端协同”方案
2026年9月,国家电网某省公司针对变电站设备巡检场景,提出“边缘-云端协同”方案:
- 边缘端:在变电站部署轻量化NLP模型(如DistilBERT),实时解析巡检机器人的语音报告和图像标注,提取“变压器油位低”“绝缘子裂纹”等关键信息;
- 云端:用量子BERT对边缘端上传的文本数据进行深度分析,挖掘潜在故障模式(如“油位低”与“温度异常”的关联性),更新数字孪生体的故障预测模型;
- 反馈优化:将云端分析结果下发至边缘端,优化轻量化模型的参数。
这一方案通过“边缘实时处理+云端深度分析”的分工,既避免了量子BERT的延迟问题,又发挥了其语义理解优势,2026年11月,该企业试点变电站的巡检效率提升30%,故障漏检率从5%降至1%。
未来展望:量子BERT的“工业适配”之路
本月节能减排与无人机应用及绿色湿地保护热度持续上升,相关产业迎来新发展 尽管当前量子BERT在工业场景的应用面临挑战,但其并行计算和低能耗的特性仍具有巨大潜力,2026年,学术界和工业界已开始探索量子BERT的“工业适配”方案:
- 专用量子芯片:针对工业文本数据