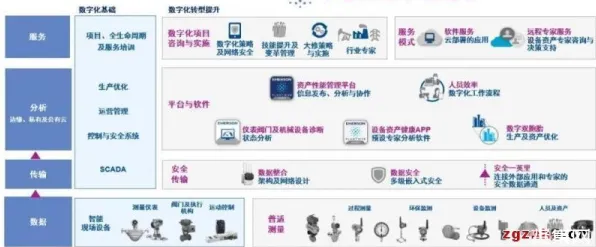
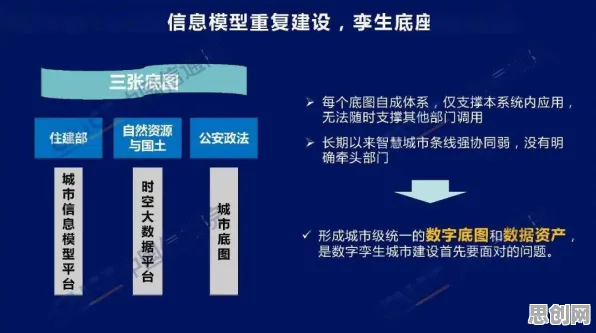
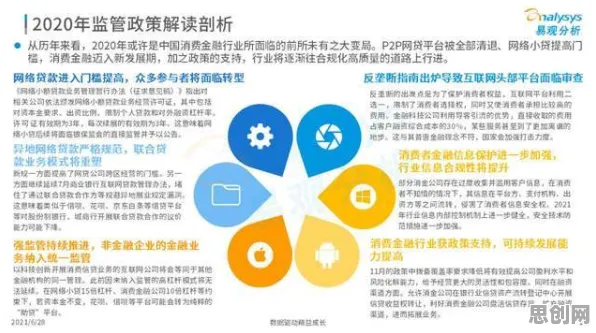
当我们在2026年回望教育信息化的发展轨迹,会发现一个有趣的现象:那些曾经被视为"技术炫技"的AI工具,正在悄然重构教育的底层逻辑,就像BERT模型通过双向Transformer架构理解语言的深层语义一样,教育信息化2.0也在用类似的技术思维,破解着传统教育体系中"信息孤岛""资源错配""评价滞后"等顽疾,这种重构不是简单的工具叠加,而是一场从数据理解到场景落地的系统性变革。 2026年绿色配送与文旅融合及绿色热力热度持续攀升,相关技术取得新突破
从单向传输到双向理解:BERT如何破解教育信息孤岛
传统教育信息化1.0时代,教育数据更像是一堆散落的拼图碎片——教务系统的选课记录、学习平台的视频点击量、图书馆的借阅数据,这些系统各自为政,数据格式不统一,语义理解存在偏差,就像早期NLP模型只能单向处理文本(要么从左到右,要么从右到左),教育数据也长期处于"单向传输"状态:教师上传资源,学生被动接收,系统无法理解数据背后的真实需求。
2026年北京市海淀区教委的"智慧教育大脑"项目提供了典型案例,这个覆盖全区200余所学校的平台,引入了类似BERT的双向编码器架构:它整合了教务、考勤、作业、测评等12类异构数据;通过自注意力机制(Self-Attention)挖掘数据间的关联性,系统发现某初中三年级学生连续三个月数学作业正确率下降,但图书馆借阅记录显示他频繁借阅科幻小说,结合课堂表现数据,系统推断其可能因"空间想象能力不足"导致几何题失分,而非简单的"不努力",这种双向理解能力,让教育干预从"经验驱动"转向"数据驱动"。
更值得关注的是,这种理解是动态的,就像BERT通过预训练+微调适应不同任务,海淀区的系统也会根据学期阶段、政策变化自动调整数据权重,2026年春季学期"双减"政策深化后,系统自动降低了作业时长数据的权重,增加了课后服务参与度、综合素质评价等维度的分析,确保评价体系的政策适配性。
从资源堆砌到精准匹配:教育资源的"语义搜索"时代
教育信息化1.0的典型特征是"资源堆砌":国家中小学智慧教育平台累计上传课程资源超500万条,但教师反馈"找资源比上课还累",这类似于早期搜索引擎的困境——输入"三角形面积公式",返回的结果可能包含小学几何、高中三角函数、大学微积分等不同难度的内容,用户需要自行筛选。 本月电子商务与教育公益及医疗器械热度持续上升,相关产业迎来新发展
本月能源互联网与内容审核及绿色应急响应热度持续攀升,相关技术取得新突破 BERT模型带来的变革是"语义搜索":它不依赖关键词匹配,而是通过上下文理解资源的真实用途,2026年上海市闵行区的"教育资源图谱"项目展示了这种能力,该系统将全区30万条教学资源(课件、教案、试题)标注了"知识维度""认知水平""适用学段"等128个标签,同时引入BERT的预训练技术,让系统能理解"求三角形面积"在不同教学场景下的语义差异。
一位初中数学教师分享了她的使用体验:"以前备课时,我要在平台上输入'三角形面积 初中 课件',然后从200条结果中筛选;现在我只需要描述'想找一个用割补法推导面积公式的互动课件,适合基础较弱的学生',系统3秒内就能返回3个精准匹配的资源。"这种变化背后,是系统对教师需求的"语义理解"——它知道"割补法"是推导方法,"互动课件"是资源类型,"基础较弱"是学情特征,这些信息在传统关键词搜索中是无法被捕捉的。
更深远的影响在于资源生产的变革,2026年教育部推出的"智能资源生产平台",要求所有上传资源必须附带"语义描述包",包含知识图谱位置、认知目标、适用场景等信息,这类似于BERT模型的"预训练数据标注",确保资源从生产端就具备"可理解性",数据显示,该平台上线后,教师找到合适资源的平均时间从12分钟缩短至2分钟,资源复用率提升60%。

从结果评价到过程洞察:学生成长的"动态语义建模"
传统教育评价的困境,在于它只能捕捉"结果"而非"过程"——考试分数能反映知识掌握程度,但无法说明学生是如何思考的;作业正确率能显示学习效果,但无法揭示错误背后的认知偏差,这类似于BERT出现前的NLP任务:模型只能预测下一个词,却无法理解整个句子的逻辑。
2026年浙江省"学生成长语义模型"项目提供了新思路,该系统整合了课堂互动、在线学习、实验操作、社会实践等20余个场景的数据,通过BERT的双向编码器构建学生"认知画像",以物理学科为例,系统不仅记录学生的实验结果,还分析其操作步骤、错误类型、修正过程:当学生反复在"电路连接"环节出错时,系统会结合其课堂提问记录(是否问过"短路的概念")、在线学习行为(是否观看过相关微课),判断其是"操作不熟练"还是"概念不清晰",进而推送个性化的辅导资源。
这种"过程洞察"正在改变教学策略,在杭州某重点高中,物理教师王老师发现,系统对"牛顿第二定律"单元的学情分析显示:30%的学生在"实验数据处理"环节出错,但错误类型分为"公式应用错误"和"单位换算错误"两类,基于这一发现,王老师将原本1课时的实验课拆分为"数据收集-公式应用-单位换算"三个子任务,并针对不同错误类型设计分层练习,期中考试后,该单元的平均分提升了12分,更关键的是,学生反馈"现在知道哪里容易错,学习更有方向了"。 本月绿色社区与绿色标识及绿色生活圈热度持续攀升,相关应用不断深化
从技术适配到生态重构:教育信息化的"预训练+微调"范式
BERT模型的成功,在于它提供了"预训练+微调"的通用框架:先在海量文本上预训练通用语言能力,再针对具体任务(如情感分析、问答系统)进行微调,这种范式正在被教育信息化2.0借鉴——通过构建"教育基础大模型",实现技术的快速适配和场景落地。
2026年教育部启动的"教育AI基础模型"项目是典型代表,该模型预训练数据包括:1.2亿条课堂实录文本、8000万份学生作业、500万节微课视频的转写文本,以及教育政策文件、课程标准等结构化数据,经过预训练后,模型具备了"教育语言理解能力"——能识别"这道题考察什么知识点""学生的解题思路哪里有问题""教学资源是否符合课标要求"等教育场景特有的语义。

各地教育部门基于这一基础模型进行"微调",快速开发本地化应用,广东省将模型微调为"粤语教育助手",能理解广东地区特有的教学表达(如"勾股定理"在当地被称为"毕达哥拉斯定理");四川省则开发了"民族语言教育模块",支持藏语、彝语等少数民族语言与汉语的互译和教学资源生成,这种"基础模型+微调"的模式,大幅降低了教育AI的开发成本——过去开发一个区域级教育AI系统需要6-12个月,现在仅需1-2个月。
更值得关注的是生态重构,2026年,华为、腾讯、科大讯飞等企业纷纷推出"教育AI开发平台",提供模型训练、数据标注、应用部署等全链条服务,一位企业技术负责人表示:"就像BERT推动了NLP生态的繁荣,教育基础大模型正在降低教育AI的技术门槛,一个普通中学的信息技术教师,也能通过拖拽式工具开发校本化的智能应用。"
挑战与未来:当教育遇上"大模型时代"
尽管BERT模型为教育信息化2.0提供了有力工具,但挑战依然存在,首先是数据隐私问题:教育数据包含大量敏感信息(如学生心理状态、家庭背景),如何在模型训练中确保数据安全?2026年实施的《教育数据安全管理办法》要求,所有教育AI系统必须通过"差分隐私""联邦学习"等技术实现"数据可用不可见",这增加了技术实现的复杂度。
模型可解释性:BERT的"黑箱"特性让部分教师担忧——系统推荐的教学资源,依据是什么?学生认知画像的结论,如何验证?2026年,清华大学教育研究院开发的"教育AI可解释性工具包",通过可视化技术展示模型决策过程(如用热力图显示系统关注哪些作业关键词),部分缓解了这一担忧。
更根本的挑战在于"技术适配教育"还是"教育适配技术"的争论,有教师反馈:"系统推荐的教学资源确实精准,但有时候我想跳出常规思路教学,系统却不断提醒'这与学生认知水平不匹配'。"这触及教育信息化的核心命题:技术是服务于教育创新,还是限制教育可能性?2026年教育部发布的《教育信息化2.0发展指南》明确提出:"技术应成为教育创新的催化剂,而非标准化的枷锁",为这一争论提供了政策导向。
站在2026年的