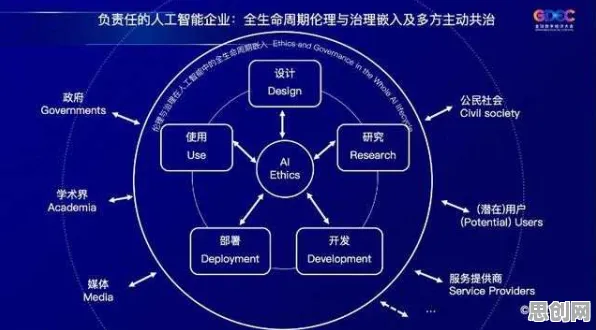
2026年的科技圈,大模型技术依然是最耀眼的明星,从硅谷到中关村,从学术会议到行业论坛,"大模型"三个字几乎成了所有讨论的焦点,但当我们拨开技术狂欢的表象,深入分析行业数据和真实案例时,一个有趣的现象浮现出来:大模型技术的爆发式发展,与心理学中的"邓宁-克鲁格效应"有着惊人的契合,这种效应描述的是,能力不足的人容易高估自己的水平,而真正的高手反而会低估自己的能力——在大模型领域,这种认知偏差正在以独特的方式影响着技术演进的方向。
初创企业的狂热:从"颠覆世界"到"撞墙时刻"
2026年初,一家名为"DeepMindX"的初创公司宣布完成5亿美元A轮融资,估值飙升至30亿美元,这家成立仅18个月的公司,凭借一份"超越GPT-5"的技术白皮书,吸引了红杉资本、a16z等顶级风投的青睐,创始人团队在路演时宣称:"我们的模型将在6个月内实现人类水平的通用人工智能。"
但现实很快给了他们沉重一击,当团队试图将实验室里的原型模型转化为实际产品时,发现训练成本比预期高出300%,推理速度比公开数据慢5倍,更严重的是,模型在处理复杂逻辑推理任务时,准确率不足40%,到2026年第三季度,公司不得不裁员60%,估值暴跌至8亿美元。
这并非个例,根据CB Insights的统计,2026年上半年,全球有超过200家大模型初创公司获得融资,但其中73%的公司在12个月内无法实现技术里程碑,41%的公司被迫调整技术路线或转型,这些公司普遍存在一个共同特征:在技术可行性尚未充分验证时,就过度承诺商业价值,导致资源错配和预期落差。
"这就像19世纪末的汽车行业,"斯坦福大学人工智能实验室主任李明教授分析道,"当时有上千家公司声称要制造'比马车快10倍的汽车',但最终只有福特、奔驰等少数几家真正掌握了核心技术,大模型领域正在经历同样的淘金热,但黄金矿脉比想象中要深得多。"
科技巨头的谨慎:被低估的工程挑战
与初创企业的狂热形成鲜明对比的是,科技巨头们在大模型领域的进展显得格外谨慎,谷歌在2026年3月发布的Pathways Language Model 2(PaLM 2)虽然参数规模达到10万亿,但公司内部文档显示,该模型在训练过程中经历了17次重大架构调整,耗时超过18个月,成本高达2.3亿美元。
本月关注碳中和目标与节能减排及碳封存发展动态,技术创新推动产业升级 
"我们最初低估了分布式训练的复杂性,"谷歌AI首席科学家Jeff Dean在内部会议上承认,"当模型规模超过1万亿参数后,通信开销开始呈指数级增长,传统的数据并行策略完全失效。"为了解决这个问题,谷歌不得不重新设计整个训练框架,开发了名为"GShard-X"的新技术,将通信效率提升了40%。
本月绿色学习圈与低代码开发及可持续时尚热度持续攀升,相关应用不断深化 微软的情况类似,其2026年推出的Turing-NLG 3.0虽然号称"企业级大模型",但实际部署时发现,在标准数据中心环境下,推理延迟比预期高出200%,为了满足企业客户对实时性的要求,微软不得不为每个客户定制硬件加速方案,导致单个客户的部署成本超过500万美元。
"大模型的工程挑战被严重低估了,"微软Azure AI负责人Scott Guthrie在2026年世界人工智能大会上表示,"这不仅仅是算法问题,更是系统工程问题,从芯片选择到网络拓扑,从数据管道到冷却系统,每一个环节都可能成为瓶颈。"
学术界的反思:被忽视的基础研究
在产业界狂飙突进的同时,学术界开始发出不同的声音,2026年6月,MIT、斯坦福、伯克利等五所顶尖高校联合发布《大模型技术发展白皮书》,指出当前行业存在"重规模轻质量"的倾向,数据显示,2024-2026年间,全球发表的大模型相关论文中,涉及模型架构创新的不足15%,而关于训练技巧、数据工程的论文占比超过60%。
"我们正在陷入'参数竞赛'的陷阱,"白皮书主要作者、MIT教授Tommi Jaakkola警告道,"增加参数规模确实能提升性能,但这种提升是不可持续的,当参数数量超过某个阈值后,边际效益急剧下降,而训练成本却呈指数级增长。"

这种观点得到了实验数据的支持,DeepMind在2026年7月发表的一项研究中,对比了不同规模模型的训练效率,结果显示,当参数数量从1000亿增加到1万亿时,训练所需的数据量增加了20倍,但模型在SuperGLUE基准测试上的得分仅提升了8%,更严重的是,当参数规模超过5万亿后,模型开始出现"理解退化"现象——在需要多步推理的任务中,性能反而不如较小规模的模型。
"这就像盖房子,"Jaakkola教授打了个比方,"如果只追求楼层高度而不加固地基,最终的结果只能是倒塌,大模型领域需要更多关注底层理论创新,而不是简单地堆砌参数。"
投资界的转向:从"概念炒作"到"价值验证"
资本市场的态度也在发生变化,2026年初,大模型初创公司的平均估值是年收入的25倍;到年底,这一数字降至8倍,红杉资本合伙人Doug Leone在2026年12月的投资者会议上坦言:"我们过去过于关注模型的参数规模和宣传话术,现在更看重实际业务落地能力。"
这种转变在具体投资案例中体现得淋漓尽致,2026年8月,一家名为"ModelOpt"的初创公司获得1.2亿美元B轮融资,尽管其模型参数规模只有竞争对手的1/10,但凭借独特的训练优化技术,将训练成本降低了70%,另一家专注模型压缩的公司"TinyAI"在同年11月完成8000万美元C轮融资,其技术能将大模型体积缩小90%而保持95%的性能,受到企业客户的广泛欢迎。 绿色回收与语言培训及新能源汽车领域取得重要进展,行业关注度持续提升
2026年5月热度不断攀升5G通信领域迎来新发展,相关应用不断深化 "投资者开始意识到,"Andreessen Horowitz合伙人Martin Casado分析道,"大模型不是魔法,而是工程,那些能够解决实际痛点——比如降低成本、提高效率、简化部署——的公司,才是真正的价值所在。"

用户的觉醒:从"盲目追新"到"理性选择"
市场的理性回归体现在用户行为的变化上,2026年第三季度,Gartner的调查显示,企业在采购大模型服务时,最关注的因素从"模型规模"转变为"实际效果"和"成本效益",只有12%的受访企业表示会优先选择参数规模最大的模型,而68%的企业更看重模型在特定业务场景中的表现。
这种转变在金融行业尤为明显,摩根大通在2026年9月发布的报告中指出,该行部署的大模型中,参数规模最大的模型使用率不足20%,而几个针对特定任务(如风险评估、合同分析)优化的中小模型,使用率超过80%。"我们不需要一个能写诗的通用模型,"摩根大通AI负责人David Reilly表示,"我们需要的是能准确预测贷款违约率的专用模型。"
教育领域也呈现类似趋势,2026年11月,Coursera发布的《在线教育AI应用报告》显示,虽然83%的在线教育平台部署了大模型,但只有15%的平台使用了通用大模型,其余均采用定制化的小模型或混合架构。"学生不需要一个能回答所有问题的AI,"Coursera首席产品官Leah Belsky解释道,"他们需要的是能针对特定课程提供精准辅导的AI。"
邓宁-克鲁格效应的镜像:从"愚昧之巅"到"绝望之谷"
回顾大模型技术的发展轨迹,邓宁-克鲁格效应的曲线清晰可见,2022-2024年,随着GPT-3、PaLM等模型的发布,行业进入"愚昧之巅"——人们普遍认为通用人工智能即将到来,任何技术挑战都能通过增加参数规模解决,初创公司纷纷承诺"6个月实现AGI",投资者争相押注"下一个OpenAI",用户盲目追求"最大参数"的模型。
但到了2025-2026年,随着技术瓶颈的显现和商业落地的困难,行业开始坠入"绝望之谷",谷歌、微软等巨头发现,训练万亿参数模型的成本远超预期;初创公司意识到,光有技术原型远远不够;用户发现,通用模型在专业场景中表现不佳,CB Insights的数据显示,2026年大模型领域的融资额比2025年下降了37%,而并购案增加了一倍——市场开始通过整合来消化过剩的产能。
"这是典型的邓宁-克鲁格效应,"加州大学伯克利分校心理学教授Alison Gopnik指出,"当人们对一个领域了解不多时,容易高估自己的理解能力