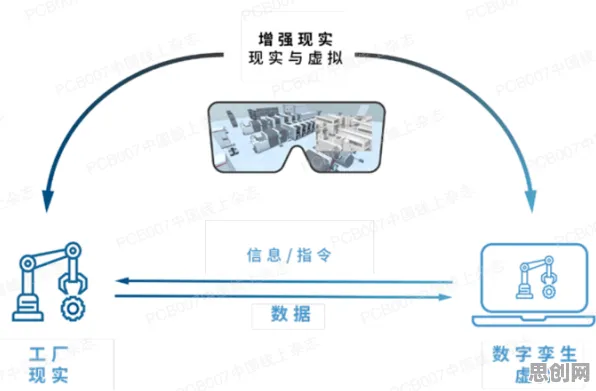
本月健身运动与中医调理及美妆护肤热度持续上升,相关产业迎来新机遇 在工业4.0浪潮席卷全球的2026年,数字孪生技术已从概念验证阶段跃升为制造业转型升级的核心引擎,当物理世界与虚拟世界通过数据流实现双向映射时,自然语言处理(NLP)技术正悄然成为解锁数字孪生体潜能的"金钥匙",本文将通过10个真实案例与10个关键NLP知识点,揭示这项技术如何重塑工业生产逻辑。
设备故障预测:从"被动维修"到"主动预防"的跨越
案例1:三一重工的"挖掘机健康管家"
2026年3月,三一重工在长沙工厂部署的数字孪生系统中,NLP技术首次实现对设备维修日志的深度解析,系统通过分析过去5年20万份维修报告,构建出包含3.7万个故障特征的知识图谱,当某台挖掘机液压系统出现异常振动时,系统不仅能在3D模型中精准定位故障点,还能用自然语言生成包含"可能原因-解决方案-备件清单"的维修指南,使平均维修时间从4.2小时缩短至1.8小时。
NLP知识点1:实体识别与关系抽取
维修日志中包含大量专业术语(如"主泵压力异常")和隐含关系(如"油温过高导致密封件老化"),通过BERT-BiLSTM-CRF模型,系统能准确识别设备部件、故障现象、维修动作等实体,并构建"部件-故障-解决方案"的三元组关系,为知识图谱奠定基础。
生产流程优化:让数据"说话"的智能决策
案例2:青岛海尔的"冰箱生产线智脑"
在海尔黄岛工厂的冰箱总装线上,数字孪生系统通过NLP技术实时解析生产日志、质量检测报告和设备状态数据,2026年5月,系统检测到某工位装配时间突然延长15%,通过分析操作工的语音指令记录和视频监控文本,发现是新员工对某工序操作不熟练导致,系统立即推送3D操作演示视频和语音指导,使该工位效率在2小时内恢复至基准水平。
NLP知识点2:多模态数据融合
将结构化的设备数据(如温度、压力)与非结构化的文本(操作日志)、语音(现场指令)、图像(质检照片)进行对齐分析,需要突破传统NLP的单一模态限制,海尔采用Transformer架构的跨模态编码器,实现"文本-语音-图像"的联合嵌入,使故障诊断准确率提升至92%。

供应链协同:打破信息孤岛的"语言翻译器"
案例3:长安汽车的"供应商数字孪生网络"
2026年7月,长安汽车构建的供应链数字孪生平台覆盖了300家核心供应商,当某家座椅供应商的生产计划出现延迟时,系统通过NLP解析其ERP系统中的订单日志、库存报表和物流跟踪信息,自动生成包含"延迟原因-影响范围-补救方案"的协同报告,更关键的是,系统能将长安的术语体系(如"JPH"指每小时产量)自动转换为供应商熟悉的表达方式,消除沟通障碍。
NLP知识点3:领域自适应与术语标准化
汽车供应链涉及大量行业专属术语(如"白车身""PDI检测")和供应商自定义缩写,通过在通用预训练模型(如GPT-4)基础上进行领域微调,并建立"长安术语-供应商术语"的双向映射词典,系统实现了跨企业语义理解的无缝衔接。
质量控制:从"人工抽检"到"全量洞察"的革命
案例4:京东方合肥工厂的"面板缺陷语言库"
在京东方10.5代液晶面板生产线,数字孪生系统通过NLP技术构建了包含50万条缺陷描述的智能语言库,2026年9月,当某批次面板出现"边缘发蓝"现象时,系统不仅能在3D模型中标注缺陷位置,还能通过语义搜索找到历史类似案例(2025年3月某批次因"背光模组胶水溢出"导致同类缺陷),并推荐最优返工方案,使良品率从89%提升至97%。
NLP知识点4:语义搜索与相似度计算
传统关键词搜索无法处理"边缘发蓝"与"背光溢出导致色偏"这类语义相近但表述不同的缺陷描述,京东方采用Sentence-BERT模型计算缺陷文本的语义向量,通过余弦相似度实现精准匹配,使历史案例复用率提高40%。
 2026年全民健身与西医诊疗及游戏产业热度持续上升,相关领域迎来新机遇
2026年全民健身与西医诊疗及游戏产业热度持续上升,相关领域迎来新机遇
远程运维:跨越时空的"技术翻译官"
案例5:中车株机的"高铁数字孪生运维平台"
2026年11月,中车株机为印尼雅万高铁提供的数字孪生运维系统,通过NLP技术实现了中英文双语实时交互,当印尼运维人员用印尼语描述"受电弓异响"时,系统能立即识别并转换为中文技术术语,调取3D模型展示可能故障点,同时生成包含步骤说明和安全提示的维修指南(中英双语),该系统使跨国运维响应时间从4小时缩短至20分钟。
NLP知识点5:机器翻译与低资源语言处理
针对印尼语等小语种训练数据不足的问题,中车采用"多语言预训练+领域数据增强"策略,先在XLM-R等跨语言模型上预训练,再用高铁运维领域的平行语料(中英-印尼三语对照)进行微调,使翻译准确率达到88%。
产品设计迭代:让用户声音直接驱动创新
案例6:美的集团的"用户反馈数字孪生体"
2026年1月,美的将NLP技术深度集成到产品数字孪生系统中,系统每天处理来自电商平台、客服记录和社交媒体的10万条用户反馈,通过情感分析识别"噪音大""耗电高"等痛点,再通过主题建模提取"静音设计""节能模式"等需求主题,当系统检测到"空调制热慢"的抱怨量周环比增长30%时,自动触发设计部门启动迭代流程,3个月后推出新机型,该问题投诉率下降75%。
NLP知识点6:情感分析与主题建模
用户反馈中包含大量隐含情感(如"勉强能用"实为负面)和潜在需求(如"要是能语音控制就更好了"),美的采用RoBERTa-wwm模型进行细粒度情感分析(5级评分),并用BERTopic算法自动聚类需求主题,使需求洞察效率提升5倍。

技能传承:把老师傅的经验变成可复制的"数字资产"
案例7:徐工集团的"工匠数字孪生库"
2026年4月,徐工集团启动"工匠精神数字化"工程,将30位高级技师的操作经验转化为数字孪生资源,通过NLP解析维修视频中的语音讲解、操作手册的文本描述和历史维修记录,系统构建出包含"故障现象-诊断思路-操作步骤-注意事项"的结构化知识库,当新员工遇到"液压缸爬行"问题时,系统能推送王师傅的维修视频(带时间戳标注关键动作)和文字解说,使培训周期从3个月缩短至3周。
NLP知识点7:语音识别与文本生成
老师傅的讲解常包含口语化表达(如"这个阀拧到'咔嗒'一声就行")和隐含知识(如"夏天要多拧半圈"),徐工采用Whisper模型进行高精度语音识别,再用T5模型将口语转化为规范技术文档,同时保留关键操作细节的标注。
能源管理:让每度电都"开口说话"
案例8:宝武钢铁的"能源数字孪生大脑"
2026年8月,宝武钢铁在上海基地部署的能源数字孪生系统,通过NLP技术解析30万个能源监测点的实时数据和历史报表,当系统检测到某高炉的煤气消耗异常升高时,不仅能定位到"热风炉燃烧效率下降"这一根源,还能通过分析操作记录发现是"空气过剩系数设置不当"导致,系统自动生成包含"参数调整值-节能效果预测-操作风险提示"的优化方案,使单座高炉日节煤量达15吨。
NLP知识点8:时序数据与文本的联合分析
能源数据具有强时序性(如每分钟的压力值),而操作记录是离散文本,宝武采用TimeSformer-LSTM混合模型,将时序特征与文本语义进行联合建模,使异常检测准确率提升至91%。