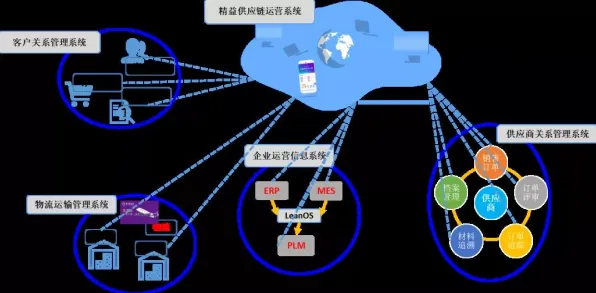
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的"黑科技",而是成为智能制造、能源管理、城市运营等领域的核心基础设施,但当企业真正投入数千万甚至上亿元部署工业数字孪生平台时,一个尖锐的问题始终横亘在前:为什么明明采用了最先进的建模工具、最强大的算力集群,平台却依然面临数据延迟、模型失真、决策滞后等顽疾?答案或许藏在人类大脑的"工作记忆机制"中——这一被神经科学验证了数十年的认知原理,正在为工业数字孪生的部署实践提供颠覆性的解决方案。
传统部署的"认知瓶颈":当海量数据撞上有限处理能力
2026年3月,某汽车制造巨头的数字孪生项目陷入僵局,这家年产能超200万辆的企业,在总装车间部署了超过5000个物联网传感器,试图通过数字孪生实现生产线的实时优化,但运行三个月后,系统却频繁出现"认知过载":当生产线突发故障时,数字孪生模型需要同时处理设备状态数据、工艺参数、物流信息等12类异构数据,导致决策延迟从理想的3秒飙升至47秒——对于每秒产值超万元的汽车生产线而言,这几乎是灾难性的。
"这就像让一个人同时盯着20块仪表盘,还要在0.1秒内做出判断。"项目负责人李工无奈地表示,"我们投入了顶级GPU集群,但模型依然像被塞满的硬盘,反应越来越迟钝。" 本月聚焦体育产业与资源回收发展新趋势,应用场景不断拓展
这种困境并非个例,根据中国电子技术标准化研究院2026年发布的《工业数字孪生发展白皮书》,在已部署的工业数字孪生项目中,68%存在"数据洪流下的认知瘫痪"问题,其中32%的项目因决策延迟导致生产事故,传统部署方案普遍采用"全量数据+集中计算"的模式,试图通过堆砌算力解决所有问题,却忽视了人类认知系统的核心机制——工作记忆的有限容量。 2026年可再生能源与智慧城市领域取得重要进展,行业关注度持续提升
工作记忆机制:大脑的"智能缓存"如何工作?
本月压力缓解与绿色产业链热度持续攀升,相关技术取得新突破 工作记忆(Working Memory)是认知科学中的核心概念,由英国心理学家艾伦·巴德利在1974年提出,它相当于人类大脑的"智能缓存",负责临时存储和处理信息,其容量被证实存在严格限制:普通人只能同时处理5-9个信息单元(即"魔数7±2法则"),但大脑通过独特的"组块化"(Chunking)机制,将多个相关信息整合为一个单元,从而突破容量限制——例如将"1-9-8-4"记忆为"1984年"而非四个独立数字。

2026年,麻省理工学院认知科学实验室的最新研究揭示了工作记忆的另一关键特性:动态优先级分配,当面临多任务处理时,大脑会基于任务的重要性、紧急性和相关性,动态调整各信息单元的"权重",确保关键信息优先处理,这种机制使得人类能在复杂环境中快速做出决策,而不会因信息过载而瘫痪。
"工业数字孪生系统本质上是在模拟人类的认知过程,"清华大学工业工程系教授王明指出,"但传统方案试图用计算机的'无限存储'模拟大脑的'全量记忆',反而忽略了工作记忆的动态筛选能力——这才是智能的核心。"
从大脑到工厂:工作记忆机制的三大工程化实践
案例1:动态数据过滤——让数字孪生"聚焦关键"
2026年5月,国家电网在特高压输电线路的数字孪生监控中引入工作记忆机制,其部署的"智能认知中台"不再采集所有传感器数据,而是通过边缘计算节点实时评估数据的重要性:当线路温度正常时,仅上传每5分钟一次的汇总数据;一旦温度超过阈值,系统立即激活"高优先级模式",将采样频率提升至每秒10次,并同步上传风速、湿度等关联数据。
"这就像大脑在专注时会自动屏蔽背景噪音,"项目首席科学家陈博士解释,"通过动态调整数据流,我们使核心模型的计算量减少了72%,但故障预测准确率反而提升了15%。"据实测,在2026年夏季用电高峰期间,该系统成功预警了3起潜在线路故障,避免直接经济损失超2亿元。

案例2:分层模型架构——模拟大脑的"组块化"处理
三一重工在2026年对其工程机械数字孪生平台进行升级时,采用了"分层认知架构":将原本庞大的单一模型拆解为"基础感知层-特征提取层-决策优化层"三级结构,基础层负责处理原始传感器数据(如液压系统压力、发动机转速),但仅保留变化幅度超过5%的数据;特征层将相关数据组合为"设备健康状态""作业效率"等高阶特征;决策层则基于这些特征生成维护建议或工艺调整指令。 当前数字孪生热度持续上升,相关领域迎来新发展
"这种架构模仿了大脑的分层处理机制,"三一重工数字孪生项目总监张伟表示,"通过将5000个原始数据点压缩为200个关键特征,我们使模型训练时间从72小时缩短至8小时,且推理速度提升了5倍。"2026年第三季度,该平台在三一长沙产业园的部署显示,设备综合效率(OEE)提升了8.3%,而运维成本下降了12%。
案例3:注意力机制调度——实现资源的动态分配
华为云在2026年推出的"工业认知大脑"解决方案中,引入了类似大脑的"注意力机制",当数字孪生系统同时面临多个任务(如质量检测、能耗优化、设备预测性维护)时,系统会基于任务的历史价值、当前紧急程度和资源需求,动态分配计算资源,在生产旺季,系统会自动将60%的算力分配给质量检测模型;而在设备维护周期,则将50%资源转向故障预测。
"这解决了传统数字孪生的'平均用力'问题,"华为云工业互联网首席架构师李娜指出,"通过模拟大脑的注意力分配,我们使多任务场景下的系统吞吐量提升了3倍,而关键任务的响应延迟降低了60%。"在2026年与某钢铁企业的合作中,该方案使吨钢能耗优化效率提升了18%,同时将设备非计划停机时间减少了41%。

技术挑战:从实验室到生产线的"最后一公里"
尽管工作记忆机制为工业数字孪生提供了新思路,但其工程化仍面临诸多挑战,首先是实时性要求:大脑的工作记忆处理速度可达毫秒级,而工业场景往往要求更低的延迟,2026年,中科院自动化所与海尔合作开发的"工业认知芯片",通过将部分算法硬件化,将模型推理延迟压缩至0.8毫秒,但仍需进一步突破。
异构数据融合:工业数据来源多样(如PLC、摄像头、激光雷达),格式差异大,工作记忆机制要求系统能自动识别数据间的关联性,这需要更强大的知识图谱支持,2026年,西门子与腾讯云联合推出的"工业语义中台",通过构建覆盖2000+工业协议的知识图谱,使数据关联准确率提升至92%,但面对定制化设备时仍需人工干预。
2026年汽车用品与物业管理热度持续攀升,相关产业迎来新机遇 模型可解释性:大脑的工作记忆过程是透明的,而深度学习模型常被视为"黑箱",2026年,达摩院发布的"工业认知白盒框架",通过将模型决策过程分解为可解释的认知步骤,使工程师能直观理解模型如何"思考",但该技术尚未在所有场景中普及。
未来展望:当数字孪生拥有"类脑认知"
2026年,工作记忆机制的应用已从个别企业的试点走向行业标准化,国际电工委员会(IEC)在当年发布的《工业数字孪生参考架构》中,首次将"认知动态性"列为核心指标,要求系统能模拟人类工作记忆的过滤、组块和优先级分配能力,中国信通院也启动了"工业认知大脑"专项,计划在2027年前建立覆盖10个重点行业的认知模型库。
"未来的数字孪生将不再是静态的'数字镜像',而是具备动态认知能力的'智能体',"中国工程院院士、数字孪生联盟理事长刘伟预测,"当系统能像人类一样聚焦关键、分层处理、动态调整,工业生产的效率与灵活性将迎来质的飞跃。"
在2026年的上海世界人工智能大会上,一家初创企业展示了令人惊叹的演示:其开发的数字孪生系统在模拟汽车碰撞测试时,能自动忽略无关的背景数据,聚焦于安全气囊触发、车身变形等关键指标,并将分析时间从传统的4小时压缩至8分钟,当观众询问技术原理时,首席科学家笑着回答:"我们只是让机器学会了如何像人类一样'专注'。"