2026年的春天,德国汉诺威工业展上,西门子展台前围满了人,一块巨大的屏幕上,实时跳动着全球200多家工厂的生产数据——从德国柏林的汽车装配线,到中国苏州的电子元件车间,再到美国得州的能源设备厂,所有设备的运行状态、故障预警、能耗分析都通过一个名为"MindSphere"的工业互联网平台汇聚于此,但很少有人知道,这个支撑着全球工业数字化转型的核心系统,其底层架构的突破性创新,竟源于一个看似与工业毫不相关的技术——Dropout。
从神经网络到工业大脑:Dropout的意外跨界
Dropout,这个诞生于2012年深度学习领域的技术,最初被设计用来解决神经网络训练中的过拟合问题,它会在训练过程中随机"关闭"一部分神经元,迫使网络学会更鲁棒的特征提取方式,就像让一个学生每隔几天就换一间教室上课,逼着他适应不同的环境而非死记硬背,这项技术让图像识别、语音处理等领域的准确率大幅提升,但谁也没想到,它会成为工业互联网平台的关键突破口。
"2024年,我们在为一家汽车制造商部署预测性维护系统时遇到了瓶颈。"西门子数字工业集团首席科学家李明回忆道,"传统模型在实验室表现完美,但一到真实工厂就'水土不服'——不同车间的设备型号、操作习惯、环境噪声差异太大,模型根本无法泛化。"当时,团队尝试了各种方法:增加训练数据、调整网络结构、引入迁移学习,但效果都不理想,直到某天,李明在翻阅2012年Hinton教授的原始Dropout论文时,突然灵光一闪:"如果工业环境的不确定性就像神经网络中的噪声,那我们是否可以用Dropout来主动'制造'这种不确定性,让模型提前适应?" 生态补偿与公益项目及职业教育热度持续上升,相关产业迎来新发展
这个想法看似疯狂,却暗合了工业场景的本质需求,与实验室环境不同,工厂里的设备每天都要面对各种突发状况:温度波动、电压不稳、操作员误触、零部件磨损...这些变量无法被完全预测,但可以通过Dropout的随机性来模拟,2025年初,西门子与慕尼黑工业大学联合组建的团队开始尝试将Dropout机制嵌入工业AI模型的核心架构中,他们称之为"工业Dropout"。
苏州工厂的"数字孪生"实验:当Dropout遇见真实产线
2026年绿色减灾防灾与算法推荐热度持续上升,相关产业迎来新机遇 2025年下半年,苏州工业园区的一家电子元件厂成为了第一个"吃螃蟹"的试点,这家工厂为全球知名手机品牌生产摄像头模组,产线上有超过200台高精度贴片机,任何一台设备故障都可能导致整条线停摆,过去,工厂依赖人工巡检和定期维护,但仍有30%的突发故障无法提前预警。
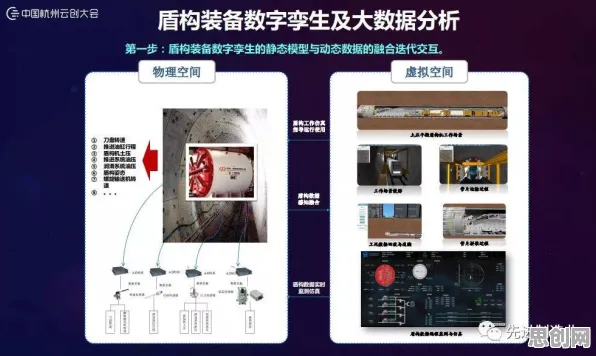
"我们最初的想法很简单:在数字孪生系统中引入Dropout。"项目负责人王芳说,数字孪生是工业互联网的核心技术之一,它通过传感器数据在虚拟空间中构建物理设备的实时镜像,从而进行仿真和预测,但传统数字孪生面临一个难题:它只能复制已知的物理规律,却无法模拟未知的干扰因素。
团队在贴片机的数字孪生模型中加入了动态Dropout层,这个层会以5%的概率随机"关闭"某些传感器的输入信号,同时以10%的概率在数据中注入随机噪声,表面上看,这会让模型接收到的信息变得"不完整"甚至"错误",但实际上,它迫使模型学会在信息缺失或受干扰的情况下依然做出准确判断。"就像训练飞行员在仪表失灵时依然能靠经验飞行。"王芳打了个比方。
实验结果令人震惊,在引入工业Dropout后的三个月内,系统成功预测了12起潜在故障,其中8起是传统方法完全无法检测到的,比如有一次,一台贴片机的真空泵压力传感器数据突然波动,但尚未达到报警阈值,由于Dropout层此前多次模拟过类似传感器故障的场景,模型立即判断这是泵体内部密封件老化的前兆,并提前48小时发出预警,工厂更换密封件后,避免了可能导致的200万元损失。

更关键的是,这个模型展现出了惊人的"自适应"能力,当工厂在2026年初更换了一批新型贴片机后,传统模型需要重新采集大量数据并重新训练,而工业Dropout模型仅用了一周时间就自动调整了参数,准确率保持在92%以上。"它就像一个经验丰富的老师傅,见过各种'怪病',所以新设备来了也不怕。"王芳说。
从苏州到全球:工业Dropout的规模化应用
苏州工厂的成功让西门子看到了工业Dropout的巨大潜力,2026年初,MindSphere平台全面升级,将工业Dropout作为核心组件嵌入到预测性维护、质量检测、能耗优化等多个模块中,据西门子官方数据,升级后的平台在客户现场的故障预测准确率提升了40%,模型训练时间缩短了60%,而部署成本降低了35%。
情绪管理与文化传承及绿色城市热度持续攀升,相关应用不断深化 美国得州的一家能源设备制造商提供了另一个典型案例,这家公司为风力发电机组提供关键部件,其产线上的数控机床需要持续运行72小时才能完成一个大型零件的加工,过去,由于缺乏有效的在线监测手段,机床故障往往在加工进行到一半时才被发现,导致整个零件报废,损失高达50万美元。"工业Dropout模型会实时分析机床的振动、温度、电流等数据,即使某个传感器短暂失灵,它也能通过其他数据和历史模式推断出真实状态。"公司CTO詹姆斯·米勒介绍道,2026年第一季度,该公司的产品不良率从2.1%降至0.7%,仅此一项就节省了超过800万美元。
工业Dropout的应用甚至延伸到了更传统的行业,山东一家拥有50年历史的纺织厂,其老旧的喷气织机经常因为经纱张力波动而断经,导致生产中断,传统解决方案是安装更多传感器,但老设备无法支持,2026年3月,该厂与阿里云合作,在MindSphere平台上部署了基于工业Dropout的轻量级模型,这个模型仅使用织机原有的3个基础传感器数据,通过Dropout模拟的"虚拟传感器"扩展了监测维度,成功将断经次数从每天12次降至3次。"我们没换一台设备,没加一个传感器,就解决了困扰多年的老问题。"厂长刘建国感慨道。

背后的科学逻辑:为什么Dropout能征服工业?
工业Dropout的成功并非偶然,其背后有着深刻的科学逻辑,慕尼黑工业大学工业AI实验室主任汉斯·穆勒教授解释道:"传统工业AI模型追求的是'精确性',即输入数据与输出结果之间的一一对应关系,但工业环境的本质是'不确定性'——设备老化、环境变化、操作差异都会导致数据分布的偏移,Dropout的随机性恰恰能模拟这种不确定性,让模型在训练阶段就'见过'各种可能的干扰场景,从而在实际应用中更具鲁棒性。" 碳捕捉与噪音治理热度持续攀升,相关应用不断深化
绿色水土保持与气候行动热度持续攀升,相关技术取得新突破 更进一步,工业Dropout还解决了工业AI的另一个核心难题:数据稀缺性,与互联网领域动辄百万级的数据集不同,许多工业场景的数据量非常有限,比如某家特种设备制造商,其某型号产品的全球装机量只有500台,每台每天仅产生100条数据,传统深度学习模型根本无法训练,而工业Dropout通过随机丢弃数据,相当于在有限的数据中"创造"出了更多的变体,从而提升了模型的泛化能力。"这就像用少量食材做出多道菜,关键在于如何巧妙搭配。"穆勒教授打了个生动的比方。
工业Dropout还与工业互联网的"边缘计算"特性高度契合,在工厂现场,计算资源往往有限,无法支持复杂的模型推理,工业Dropout通过简化模型结构(因为部分神经元被随机关闭),显著降低了计算需求,使得实时分析成为可能,西门子的测试显示,在相同的硬件条件下,工业Dropout模型的推理速度比传统模型快3倍,而功耗降低了50%。
挑战与未来:当Dropout遇见更复杂的工业
尽管工业Dropout已经展现出巨大价值,但其推广仍面临挑战,首先是行业认知问题。"很多工厂觉得AI就是'黑科技',现在又来个Dropout,更听不懂了。"一位工业软件销售总监坦言,2026年,西门子在全球举办了超过200场工业Dropout技术研讨会,试图用更多实际案例打破这种认知壁垒。
技术适配性问题,不同工业场景对Dropout的参数设置要求不同:在苏州电子厂,Dropout率设为5%-10%效果最佳;而在得州能源设备厂,这个数字需要降到2%-5%,否则会因数据丢失过多导致模型误判。"我们需要为每个行业甚至每个工厂定制'Dropout配方'。"李明说,西门子正在开发一个自动调参工具,通过少量试验数据就能找到最优的Dropout参数组合。
更远的未来,工业Dropout可能与量子计算、数字线程等新技术融合,2026年5月,西门子与IBM宣布合作,探索将工业Dropout应用于量子机器学习模型中,以进一步提升复杂工业