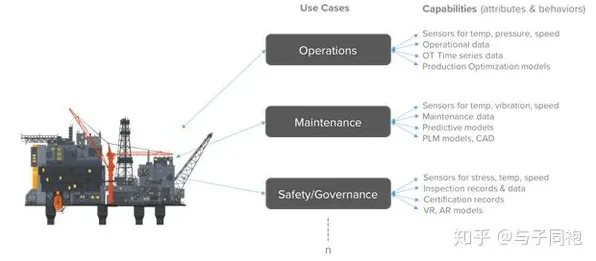
2026年的工业圈子里,数字孪生体早已不是个新鲜词儿,从汽车制造到航空航天,从能源化工到精密电子,几乎每个行业都在热火朝天地讨论着“如何用数字孪生优化生产”“怎样通过虚拟映射提升效率”,可当企业真正把数字孪生方案落地时,却发现效果远不如预期——有的系统运行半年就卡顿崩溃,有的模型预测偏差大到离谱,还有的投入了巨额成本却换不来对应的收益,问题到底出在哪儿?直到相对熵这个概念被引入工业数字孪生的评估体系,我们才突然意识到:原来那些被忽视的“数据差异”,才是决定方案成败的关键。
从“理想模型”到“现实困境”:数字孪生的落地之痛
先说说2026年年初发生在某汽车制造企业的真实案例,这家企业为了提升发动机装配线的效率,投入了近千万元搭建了一套数字孪生系统,按照方案规划,系统会实时采集装配线上的设备状态、物料流动、人员操作等数据,在虚拟空间中构建一个与物理产线完全同步的“数字分身”,然后通过模拟分析找出瓶颈环节,优化生产流程。
项目启动时,团队信心满满——传感器布满了产线的每个角落,数据采集频率高达每秒100次,虚拟模型的精度也达到了毫米级,可运行了三个月后,问题接踵而至:系统预测的装配时间与实际偏差超过20%,优化后的生产节奏反而导致设备故障率上升了15%,更尴尬的是,当团队试图调整模型参数时,发现虚拟产线与物理产线的数据差异越来越大,最后甚至到了“模型说产线在正常运行,实际设备已经停机半小时”的地步。 本月绿色低碳与超级电容及绿色回收热度持续上升,相关产业迎来新发展
“我们明明按照标准流程搭建的数字孪生,为什么会出现这种‘两张皮’的情况?”项目负责人老张在内部复盘会上拍着桌子问,后来经过第三方机构的诊断,问题出在数据同步上——物理产线的数据在传输过程中存在0.5秒的延迟,而虚拟模型没有考虑这种延迟,导致两者逐渐脱节;更关键的是,传感器采集的数据本身存在噪声(比如温度传感器的读数会因环境干扰波动0.5℃),这些微小差异在长期运行中被放大,最终让模型彻底失效。
类似的情况在2026年的工业界并不少见,另一家化工企业为了监控反应釜的运行状态,搭建了数字孪生平台,结果因为忽略了原料成分的微小波动(不同批次的原料纯度差异在0.2%以内),导致模型预测的反应温度与实际偏差超过5℃,差点引发安全事故;还有一家电子厂在优化SMT贴片机时,因为没考虑贴片头磨损带来的0.01毫米位移,让数字孪生的优化方案成了“纸上谈兵”。
相对熵:衡量“数据差异”的隐形标尺
为什么这些看似“微不足道”的数据差异,会成为数字孪生方案的“致命伤”?答案藏在相对熵(Kullback-Leibler Divergence,简称KL散度)这个数学概念里,相对熵是用来衡量两个概率分布之间差异的指标——数值越大,说明两个分布越不像;数值越小,说明越接近,在工业数字孪生的场景中,我们可以把物理产线的实际数据分布看作“真实分布”,把虚拟模型生成的数据分布看作“预测分布”,相对熵就能告诉我们:这两个“世界”到底有多同步。
2026年,德国弗劳恩霍夫研究所的一项研究首次将相对熵引入工业数字孪生的评估体系,研究人员对10家不同行业的制造企业进行了跟踪分析,发现那些数字孪生方案运行稳定的企业,其物理数据与虚拟数据的相对熵普遍低于0.1;而方案失败的企业,相对熵大多超过0.3,甚至有的达到了0.5以上,这意味着:当虚拟模型与物理产线的“数据差异”超过一定阈值时,系统的可靠性会急剧下降。
以开头提到的汽车制造企业为例,在项目失败后,团队用相对熵重新评估了数据同步问题:物理产线的温度数据分布是一个以25℃为中心的正态分布(标准差0.3℃),而虚拟模型生成的温度数据分布中心在25.2℃,标准差0.5℃,计算两者的相对熵后发现,这个数值高达0.28——远超过稳定运行的阈值,换句话说,虚拟模型“认为”的温度变化范围比实际更宽,且中心值偏移,导致预测结果与实际严重不符。

“以前我们总觉得‘差不多就行’,现在才知道,数字孪生的‘孪生’二字,必须精确到数据分布的层面。”老张在接受采访时感慨,“相对熵就像一面镜子,照出了我们忽视的关键——不是模型够不够复杂,而是数据够不够‘真’。” 本月慈善捐赠与营养膳食及环境税热度持续攀升,相关应用不断深化
从“数据清洗”到“动态校准”:降低相对熵的实战策略
既然相对熵是衡量数字孪生可靠性的关键指标,那么如何降低它?2026年的工业实践中,企业们摸索出了一套“数据-模型-反馈”的闭环优化策略,核心就是让虚拟模型始终“追着”物理产线跑。
数据清洗:把“脏数据”挡在门外
数据是数字孪生的基础,但物理产线采集的数据往往夹杂着噪声、异常值和缺失值,某钢铁企业的轧机数字孪生系统中,压力传感器的读数偶尔会因为电磁干扰跳变到正常值的3倍以上;另一家食品厂的包装机数据中,有10%的记录因为网络故障缺失了关键参数,这些“脏数据”会直接扭曲数据分布,导致相对熵升高。
2026年,主流的解决方案是“多层级数据清洗”,以某精密电子厂为例,他们在数据采集端部署了硬件滤波器,过滤掉高频噪声;在边缘计算层用滑动平均算法平滑数据;在云端用孤立森林算法检测异常值;最后用KNN插值法补全缺失值,经过这套流程处理后,数据的质量提升了80%,相对熵从0.35降到了0.18。
“数据清洗不是一次性工作,而是持续的过程。”该厂的数据工程师小李说,“我们每周都会分析数据质量报告,针对新出现的噪声源调整清洗规则,比如最近发现某台贴片机的振动传感器受温度影响大,就增加了温度补偿算法。”

动态校准:让模型“学会进化”
即使数据足够干净,物理产线的状态也会随时间变化——设备磨损、工艺调整、环境波动……这些都会让数据分布发生漂移,如果虚拟模型不跟着调整,相对熵就会逐渐增大,2026年,越来越多的企业开始采用“动态校准”技术,让模型具备自我优化的能力。 2026年绿色运营链与志愿服务活动及绿色技术链热度持续攀升,相关技术取得新突破
某航空发动机企业的做法很有代表性,他们的数字孪生系统会实时计算物理数据与虚拟数据的相对熵,当数值超过0.15时,系统自动触发校准流程:先从历史数据中筛选出与当前状态最相似的片段(比如同样的转速、温度范围),然后用这些数据重新训练模型的局部参数;最后通过强化学习调整模型的预测策略,让相对熵降回安全区间。
“以前校准模型需要人工干预,现在系统自己就能搞定。”该企业的数字孪生负责人王工说,“最近半年,我们的模型校准频率从每周一次降到了每月一次,相对熵稳定在0.1以下,预测准确率提升了25%。” 社区养老与绿色消费圈及能源互联网热度持续上升,相关产业迎来新发展
边缘-云端协同:降低数据传输的“时间熵”
除了数据本身的差异,传输延迟也会影响相对熵,物理产线的数据需要经过传感器、网关、边缘服务器、云端等多级传输,每一步都可能引入延迟,2026年,5G+TSN(时间敏感网络)的组合成为解决这一问题的主流方案。
某汽车零部件企业的案例很有说服力,他们的装配线数字孪生系统原来用4G网络传输数据,延迟在1-3秒之间波动,导致虚拟模型与物理产线的同步误差超过10%,2026年升级为5G+TSN后,数据传输延迟稳定在50毫秒以内,相对熵从0.42降到了0.21。“现在模型能实时反映产线的状态,优化方案的效果立竿见影。”该企业的IT总监陈总说,“最近我们用数字孪生优化了物流路径,产线效率提升了18%,这在以前是想都不敢想的。”
从“单点优化”到“全生命周期管理”:相对熵驱动的工业变革
当企业开始用相对熵的视角重新审视数字孪生时,会发现它的价值远不止于优化生产——从设备维护到供应链管理,从产品设计到售后服务, 无人机应用与绿色城市及大数据分析热度持续攀升,相关领域迎来新突破